kryo专题

spark性能调优---Kryo序列化
1.为啥要用Kryo序列化 Spark算子操作的时候如果用到外部数据的话,都会对外部数据进行序列化,Spark内部是使用Java的序列化机制,ObjectOutputStream / ObjectInputStream,对象输入输出流机制,来进行序列化这种默认序列化机制的好处在于,处理起来比较方便;也不需要我们手动去做什么事情,只是,你在算子里面使用的变量,必须是实现Serializable接口

【报错】spark序列化报错:Kryo serialization failed: Buffer overflow
文章目录 spark序列化报错问题解决 spark序列化报错 org.apache.spark.SparkException: Kryo serialization failed: Buffer overflow. Available: 0, required: 61186304. To avoid this, increase spark.kryoserializer.buf
Spark---性能调优之使用Kryo序列化
1、Spark默认的序列化机制和Kryo序列化机制相比有什么优势? 默认情况下,Spark内部是使用Java的序列化机制,ObjectOutputStream / ObjectInputStream,对象输入输出流机制,来进行序列化 这种默认序列化机制的好处在于,处理起来比较方便;也不需要我们手动去做什么事情,只是,你在算子里面使用的变量,必须是实现Serializable接口的,可序列化即可。
关于spark运行FP-growth算法报错com.esotericsoftware.kryo.KryoException
Spark运行FP-growth异常报错 在spark1.4版上尝试运行频繁子项挖掘算法是,照搬官方提供的python案例源码时,爆出该错误com.esotericsoftware.kryo.KryoException (java.lang.IllegalArgumentException: Can not set final scala.collection.mutable.ListBuffe
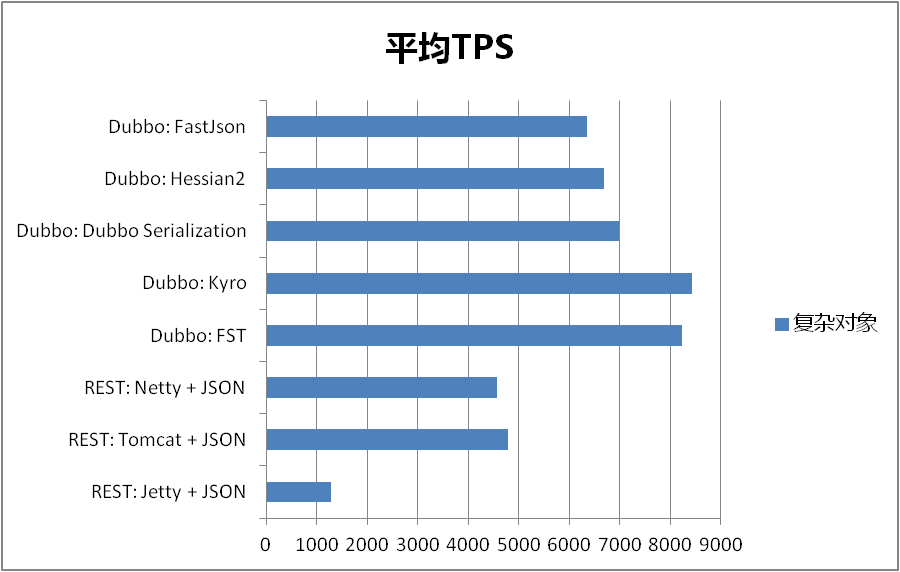
高效的Java序列化(Kryo和FST)
转:http://www.xuetimes.com/archives/572 序列化漫谈 dubbo RPC是dubbo体系中最核心的一种高性能、高吞吐量的远程调用方式,我喜欢称之为多路复用的TCP长连接调用,简单的说: 长连接:避免了每次调用新建TCP连接,提高了调用的响应速度 多路复用:单个TCP连接可交替传输多个请求和响应的消息,降低了连接的等待闲置时间,从而减少了同样并发数下的

四、Spark性能调优——Kryo序列化
默认情况下, Spark 使用 Java 的序列化机制。 Java 的序列化机制使用方便,不需要额外的配置,在算子中使用的变量实现 Serializable 接口即可, 但是, Java 序列化机制的效率不高,序列化速度慢并且序列化后的数据所占用的空间依然较大。 Kryo 序列化机制比 Java 序列化机制性能提高 10 倍左右, Spark 之所以没有默认使用 Kryo 作为序列化类库,是因为
Kryo框架的获取、基本应用例子
Kryo框架的source已移至https://github.com/EsotericSoftware/kryo ,进入此页面,然后点击右边的Download Zip按钮,就能下载到最新版本的Kryo框架。 导入Eclipse时,记得JDK/JRE选用 JDK1.7版本,因为Kryo会引用到unsafe()对象的一些方法JDK1.7才兼容。。 先来一
Kryo序列化框架简介
这句话引用oschina对Kryo的解释:Kryo 是一个快速高效的Java对象图形序列化框架,主要特点是性能、高效和易用。该项目用来序列化对象到文件、数据库或者网 络。 但是,它也有一个致命的弱点:生成的byte数据中部包含field数据,对类升级的兼容性很差!所以,若用kryo序列化对象用于C/S架构的话,两边的Class结构要保持一致。
应用Kryo Pool来改善性能,并与JDK/Jackson性能对比
pom.xml先加入引用: <dependency><groupId>com.esotericsoftware</groupId><artifactId>kryo</artifactId><version>5.0.0-RC1</version></dependency> 先上KryoUtils工具类. package com.freestyle.common.utils;import co