kafaka专题

linux 安装kafaka单体服务
1.下载kafka的linux安装包 前往Apache Kafka官方网站下载页面(Apache Kafkahttps://kafka.apache.org/downloads),选择最新稳定版的Kafka二进制分发文件,通常是以`.tgz`结尾的文件。 手动下载kafka_2.13-3.8.0.tgz到本地,然后上传到linux服务器 2.解压Kafka 将下载的Kafka压缩包解压
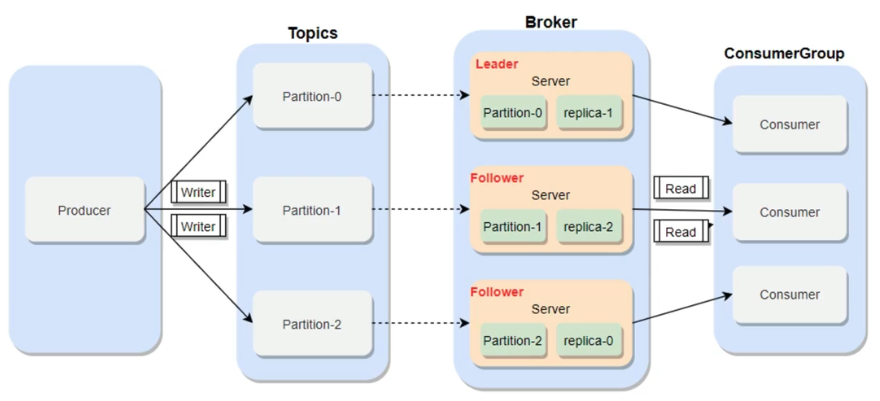
02、Kafaka 简介
02、Kafka 简介 1、 Kafka 简介 Apache Kafka 是一个分布式的发布-订阅消息系统,最初由 LinkedIn 公司开发,并在 2010 年贡献给了 Apache 软件基金会,成为一个顶级开源项目。Kafka 设计之初是为了满足高吞吐量、可扩展性、持久性、容错性以及高并发的需求,它非常适合用于实时数据流的处理,包括日志聚合、事件源、流式处理等场景。 Kafka 的架构包


RabbitMQ、kafaka、rocketmq等消息队列MQ消息堆积如何解决
文章目录 概述解决方案消息堆积如何处理如何解决消息队列的延时以及过期失效问题?消息队列满了以后该怎么处理?有几百万消息持续积压几小时,怎么办? 概述 1.产生背景: 生产者投递消息的速率与我们消费者消费的速率完全不匹配。 2.生产者投递消息的速率>消费者消费的速率 导致我们消息会堆积在我们 mq 服务器端中,没有及时的被消费者消费 所以就会产生消息堆积的问题 3.注意的是:ra

kafaka发送接收消息stream方式实例
1.配置文件 input为接收,output为发送 如果发送接收在同一个程序中,则不需要加上consumer: headerMode:raw ,如果本程序仅是接收消息进行消费,需要加上consumer: headerMode:raw spring: cloud: stream: bindings: input-collect:
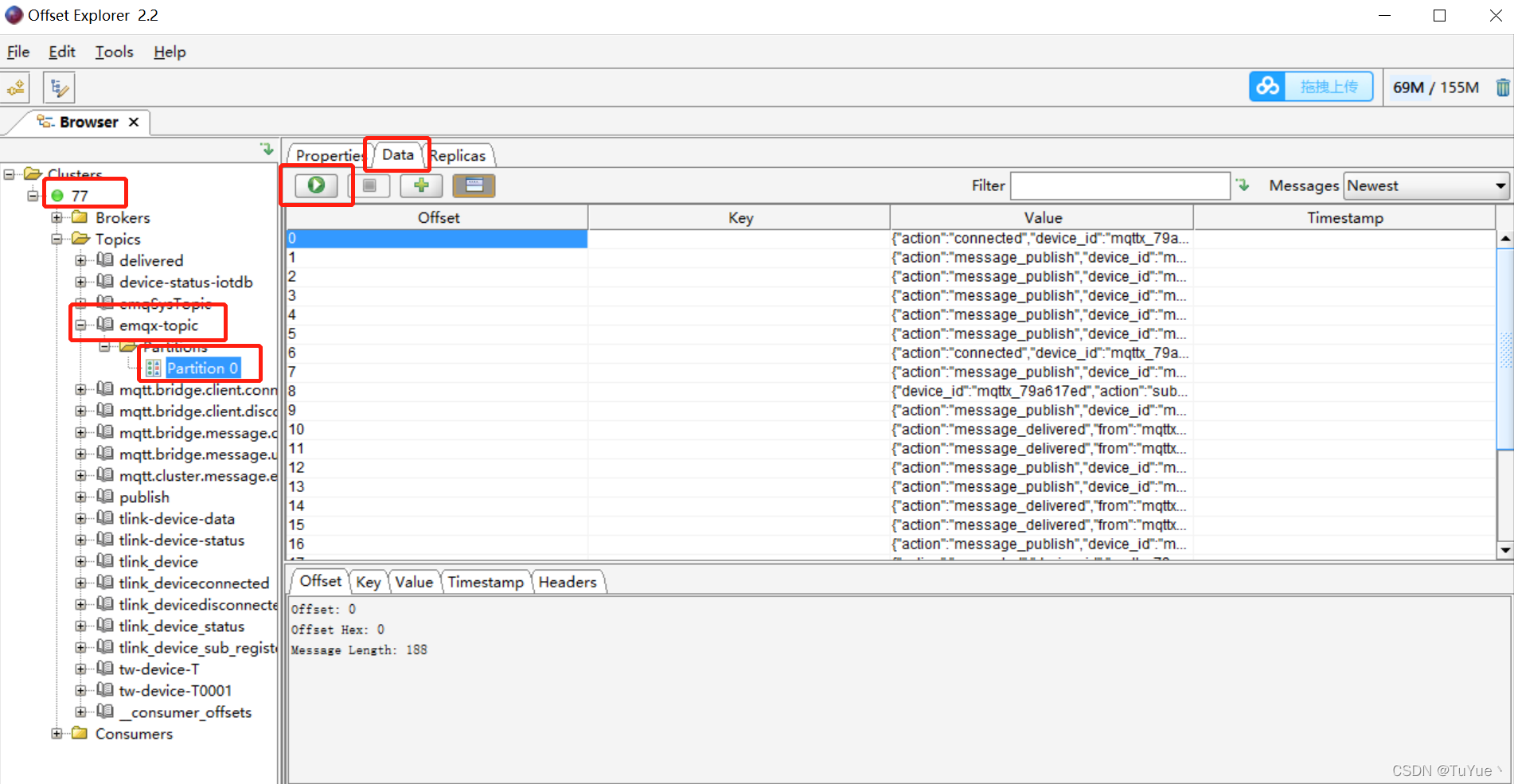
EMQ与Kafka插件emqx_plugin_kafka修改使用实现EMQ上行消息转发kafaka供服务消费 服务消息存入kafka EMQ主动消费
emqx和kafka消息通信插件实现应用 插件地址:https://github.com/ULTRAKID/emqx_plugin_kafka 1、拉取插件代码导入自己仓库 拉取插件代码 git clone https://github.com/ULTRAKID/emqx_plugin_kafka.git 之后通过git传入自己仓库或者直接fork一份到自己github仓库 2、EM