jsoup专题

jsoup解析网络HTML页,基本的使用方法
这两天因为获得网页上的数据而纠结,研究了Json、Jsoup两种获取数据的方法 今天总算小有结果,Jsoup的基本用法学会了,把我的总结发到这里,希望对正在学习android的同学有帮助,我也是个初学者,还在努力中,不废话,上代码,(注:我对android的专业术语理解的不是太透彻,有不足请指点,跪谢!) package com.android.web;import java.io.

关于Jsoup 抓取精准数据的几种用法
需要使用的是jsoup-1.7.3.jar包 如果需要看文档我下载请借一步到官网:http://jsoup.org/ 最近需要用到jsoup,由于是第一次接触,就好好学习了一下在网上搜集了一下简单的demo,感觉入手也挺快的,他的功能主要是获取html页面的内容。 找到demo之后发现跟自己需要的有些出入,就修改成自己需要的样子。话不多说,贴一下Java工程的测试代码 。 import jav

jsoup以multipart/form-data格式提交数据的处理办法
1.jsoup代码 // 注意:post方法提交,data部分和后台代码一致Connection connection = Jsoup.connect(target);Connection.Response response1 = connection.timeout(2*60000).method(Connection.Method.POST).ignoreContentType(true)

使用Jsoup抓取数据
问题 最近公司的市场部分布了一个问题,到一个网站截取一下医院的数据。刚好我也被安排做。后来,我发现为何不用脚本去抓取呢? 抓取的数据如下: Jsoup的使用实战代码 结构 Created with Raphaël 2.1.0 开始 创建线程池 jsoup读取网页 解析Element 写入sqlite 结束

使用JSOUP解析HTML文档
这篇文章主要介绍了Jsoup如何解析一个HTML文档、从文件加载文档、从URL加载Document等方法,对Jsoup常用方法做了详细讲解,最近提供了一个示例供大家参考 使用DOM方法来遍历一个文档 从元素抽取属性,文本和HTML 获取所有链接 解析和遍历一个HTML文档 如何解析一个HTML文档: 复制代码代码如下: String html =
Java开发笔记Ⅱ(Jsoup爬虫)
Jsoup 爬虫 Java 也能写爬虫!!! Jsoup重要对象如下: Document:文档对象,每个html页面都是一个Document对象 Element:元素对象,一个Document对象里有多个Element对象 Node:节点对象,用于存储数据,标签名称、属性都是节点对象 Jsoup的主要方法如下: static Connection connect(String url

Jsoup入门学习一
1、Jsoup是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。 2、Jsoup 的主要功能,如下所示: 1)、从一个URL,文件或字符串中解析HTML; 2)、使用DOM或CSS选择器来查找、取出数据; 3)、可操作HTML元素、属性、文本; 4)、Jsou
【爬虫系列】第二部分 网页解析Jsoup
Jsoup是一款Java的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。 在爬虫采集网页领域主要作用是用HttpClient获取到网页后,使用Jsoup提取网页中需要的信息,Jsoup支持类似Jquery、CSS选择器,来获取需要的数据,使用非常方便。 下

jsoup解析的使用
【准备工作】 下载:jsoup-1.6.1.jar 【先看效果】 目标网站 : 中国天气 目的 :获取今天的天气 目标HTML代码 : <li class="dn on" data-dn="7d1"> <h1>今天</h1> <h2>8日</h2> <big class="jpg50 d04"></big> <big class="jpg50 n04"></bi
java 网页解析工具包 Jsoup
Jsoup是一个非常好的解析网页的包,用java开发的,提供了类似DOM,CSS选择器的方式来查找和提取文档中的内容。 相关资料如下: 下载地址:http://jsoup.org/download 中文文档资料:http://www.open-open.com/jsoup/ 比较好的文档:http://www.ostools.net/apidocs/apidoc?api=j
HttpURLConnection 和HttpClient+Jsoup处理标签抓取页面和模拟登录
HttpURLConnection抓取 package com.app.html; import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOExcept
java的jsoup介绍--java爬虫与java解析html
最近的工作需要从网上抓取些信息,奈何不会python,暂时又没时间去研究它,只好用java来搞了。事实证明,做爬虫不一定要用python,java一样能做到。jsoup是java的文档解析工具,很方便,很强大。它可以将html文件、字符串或URL转化为Document对象,然后可以通过DOM、CSS和类似jQuery的操作方式,取出或设置属性和内容。它还可以清理不受信任的html
解析神器PK,花落谁家?Jsoup Or Xpath?
[b][color=green][size=large] 今天简单测了下使用Jsoup和Xpath解析XML的文件的方便程度,两者都可以完成解析,提取特定的元素或节点内容,但明显Jsoup更胜一筹,我们都知道Xpath是专业的xml结构化文档的查询语言,虽然语法功能强大,但是代码还是比较繁琐。虽然jsoup的出现,并不是专门用来解析XML使用的,但是使用jsoup这个轻巧的类库,我们可以完成网页

Android Jsoup的使用(WebView 加载html片段)
Android WebView 加载html片段,会存在css和js缺失问题,导致文字和图片的大小显示出现问题: 1、文字显示太小 2、图片显示太大,超出屏幕宽度 3、通过补全html,添加<style>对字体css和图片css进行设置</style>,会存在文字重叠问题 为了解决上面的问题,需要对html代码判断进行解析并修改,所以就使用到 Jsoup。 //针对<p><span>
spider-java (Jsoup) (媒体信息的爬取)
媒体基础信息爬取实例 GetAppname.java (代码为hive的udf,静态页面的获取) package com.hb.hive.utils;import java.util.Random;import org.apache.hadoop.hive.ql.exec.UDF;import org.apache.hadoop.io.Text;import org.jsoup.Js

java爬取网页内容 简单例子(2)——附jsoup的select用法详解
来源:http://www.cnblogs.com/xiaoMzjm/p/3899366.html?utm_source=tuicool&utm_medium=referral 【背景】 在上一篇博文 java爬取网页内容 简单例子(1)——使用正则表达式 里面,介绍了如何使用正则表达式去解析网页的内容,虽然该正则表达式比较通用,但繁琐,代码量多,现实中想要想出一条简单的正则表达式 对

我的Android笔记(八)—— 使用Jsoup解析Html
想要做一个看新闻的应用,类似Cnbeta客户端的东西。大致思路如下:根据链接获取新闻列表页的html代码,然后解析,找到所有的新闻标题和新闻链接用listView显示,当点击ListView的Item再加载相应的新闻内容。 其中获取html代码,可以使用如下代码实现: [java] view plaincopyprint? public String g
【网络爬虫】使用jsoup对dom树解析
基于jsoup的二次封装,对dom树解析。 package test;import java.util.LinkedList;import java.util.List;import junit.framework.TestCase;import com.vaolan.parser.JsoupHtmlParser;import com.vaolan.status.DataFormatStat
jsoup对于html的解析-爬虫
依赖 <!-- jsoup--><dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.11.3</version></dependency> 代码 //从URL加载HTML// Document document = Jsoup.connect("https://b
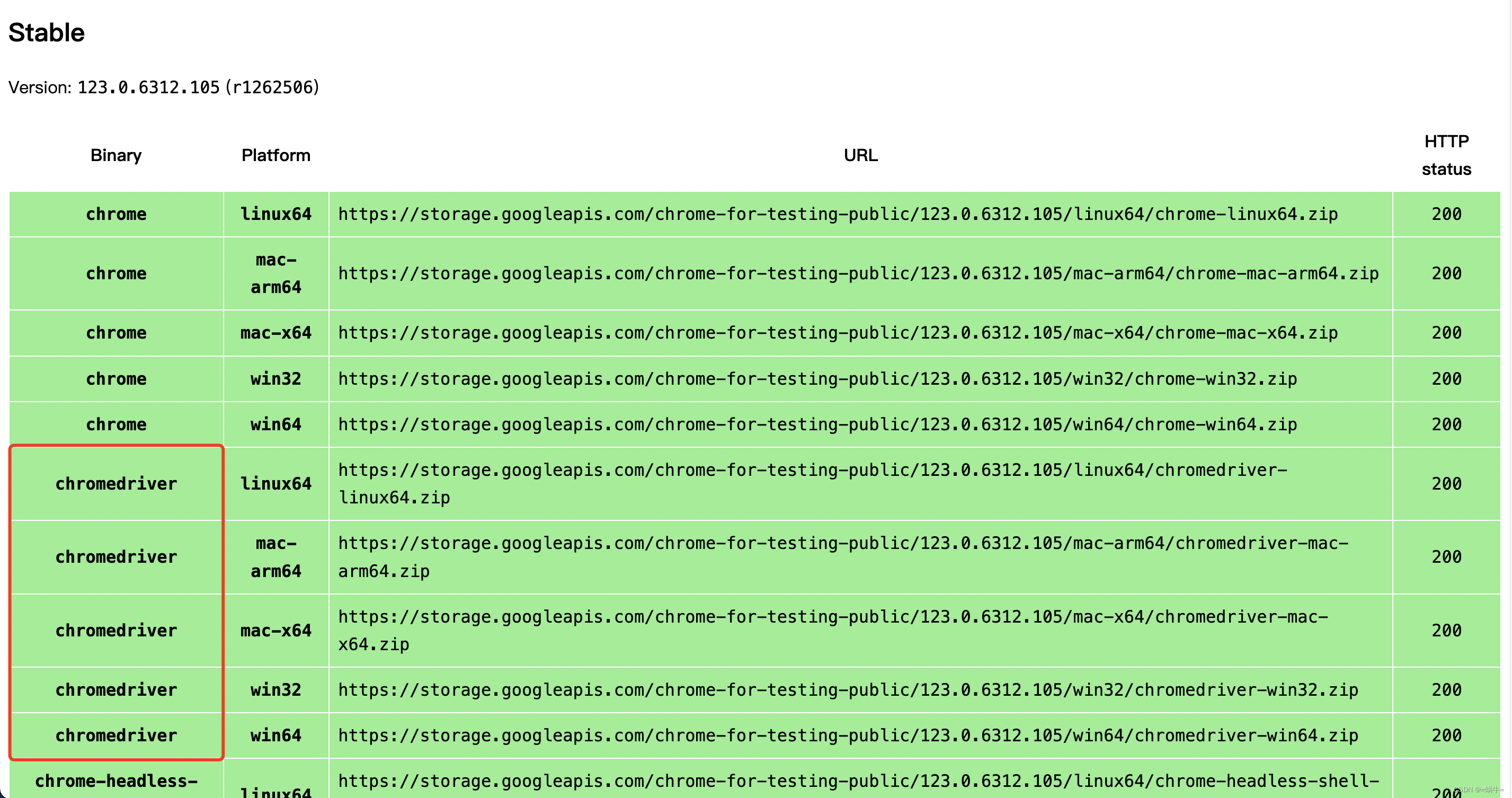
探索 Java 网络爬虫:Jsoup、HtmlUnit 与 WebMagic 的比较分析
1、引言 在当今信息爆炸的时代,网络数据的获取和处理变得至关重要。对于 Java 开发者而言,掌握高效的网页抓取技术是提升数据处理能力的关键。本文将深入探讨三款广受欢迎的 Java 网页抓取工具:Jsoup、HtmlUnit 和 WebMagic,分析它们的功能特点、优势以及适用场景,以助开发者选择最适合自己项目需求的工具。 2、Jsoup 2.1、简介 Jsoup 是一款 Java 编写

Scala中如何使用Jsoup库处理HTML文档?
在当今互联网时代,数据是互联网应用程序的核心。对于开发者来说,获取并处理数据是日常工作中的重要一环。本文将介绍如何利用Scala中强大的Jsoup库进行网络请求和HTML解析,从而实现爬取京东网站的数据,让我们一起来探索吧! 1. 为什么选择Scala和Jsoup? Scala的优势 Scala是一种多范式的编程语言,具有函数式编程和面向对象编程的特点,同时也能够与Java语言完美兼容。它

Java零基础入门——使用jsoup进行初级网络爬虫
文章目录 0. 配置jsoup1. 实战爬虫知乎2. 实战汽车之家爬图 0. 配置jsoup 安装idea并打开创建class 打开idea,File->New->Project->Maven->Next----->Finish在文件夹src->main->java下先创建package,再在该package下创建java class。 配置jsoup 把以下的文档复制粘
推荐 - Jsoup(附网页批量抓取例子)
目标:做一个简单的网站爬虫(怎么听怎么象virus。。。),访问父网站下的超链接,提取里面的文本内容。 开始时,手工写HTML的标签解析,部分代码如下: /** * 获取Href List分析结果 * * @return List<String>* @throws IOException*/ public List<String> getHrefList() throws IOEx
jsoup:一款使用 Java 语言开发的 HTML 解析器
jsoup 是一个用于处理真实世界的HTML的Java库。 它提供了一个非常方便的API来提取和操作数据,使用最好的DOM,CSS和类似jquery的方法。 jsoup 实现了 WHATWG HTML5 规范,并将 HTML 解析为与现代浏览器相同的 DOM。 从URL,文件或字符串中刮取和解析HTML使用DOM遍历或CSS选择器查找和提取数据操纵HTML元素,属性和文本清除用户提交

使用jsoup 抓取 汇率网站信息
最近公司有个业务需求,需要进行币别的兑换。因为汇率每一日都是变化的,得在实时的去抓取当日的汇率进行换算。虽然也发现有api接口能完成需求,但是还是觉得自己去获取某个页面的汇率信息比较靠谱,最终也采用jsoup去抓取汇率的信息。 pom.xml加入依赖 <dependency><groupId>org.jsoup</groupId><artifactId>jsoup</art