instructgpt专题
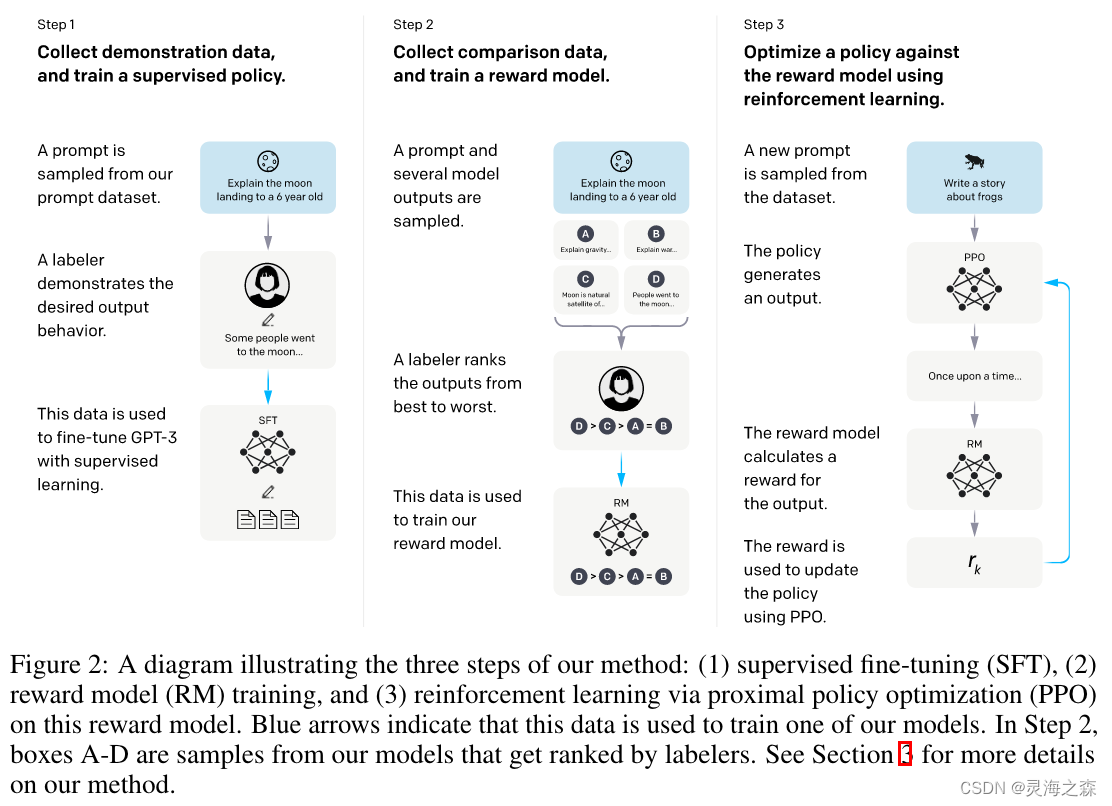
InstructGPT的流程介绍
1. Step1:SFT,Supervised Fine-Tuning,有监督微调。顾名思义,它是在有监督(有标注)数据上微调训练得到的。这里的监督数据其实就是输入Prompt,输出相应的回复,只不过这里的回复是人工编写的。这个工作要求比一般标注要高,其实算是一种创作了。 2. Step2:RM,Reward Model,奖励模型。具体来说,一个Prompt丢给前一步的SFT,输出若干个(4-9个
GPT-1, GPT-2, GPT-3, InstructGPT / ChatGPT and GPT-4 总结
1. GPT-1 What the problem GPT-1 solve? 在 GPT-1 之前,NLP 通常是一种监督模型。 对于每个任务,都有一些标记数据,然后根据这些标记数据开发监督模型。 这种方法存在几个问题:首先,需要标记数据。 但 NLP 不像 CV,它有一个标记良好的数据imagenet。 其次,这些不同任务训练的模型并不是很通用。 例如,翻译训练出来的模型很难直接用于

OpenAI: InstructGPT的简介
OpenAI: InstructGPT paper: 2022.3 Training Language Model to follow instructions with human feedback Model: (1.3B, 6B, 175B) GPT3 一言以蔽之:你们还在刷Benchamrk?我们已经换玩法了!更好的AI才是目标 这里把InstructGPT拆成两个部分,

论文阅读——InstructGPT
论文:Training_language_models_to_follow_instructions_with_human_feedback.pdf (openai.com) github:GitHub - openai/following-instructions-human-feedback 将语言模型做得更大并不能从本质上使它们更好地遵循用户的意图。例

大力出奇迹——GPT系列论文学习(GPT,GPT2,GPT3,InstructGPT)
目录 说在前面1.GPT1.1 引言1.2 训练范式1.2.1 无监督预训练1.2.2 有监督微调1.3 实验 2. GPT22.1 引言2.2 模型结构2.3 训练范式2.4 实验 3.GPT33.1引言3.2 模型结构3.3 训练范式3.4 实验3.4.1数据集3.5 局限性 4. InstructGPT4.1 引言4.2 方法4.2.1 数据收集4.2.2 各部分模型 4.3 总结