imbalanced专题

CodeForces 817D : Imbalanced Array 单调栈
传送门 题意 对于给定由 n 个元素构成的数组。一个子数组的不平衡值是这个区间的最大值与最小值的差值。数组的不平衡值是它所有子数组的不平衡值的总和。求数组的不平衡值。 分析 我们用单调栈处理出来每一个数可以作为最大值位于哪个区间,作为最小值位于哪个区间,然后计算一下贡献即可 需要注意的是,因为可能会有区间数字重复的问题,所以在处理单调栈的时候,可以一半取等,一半不取等 代码 #prag
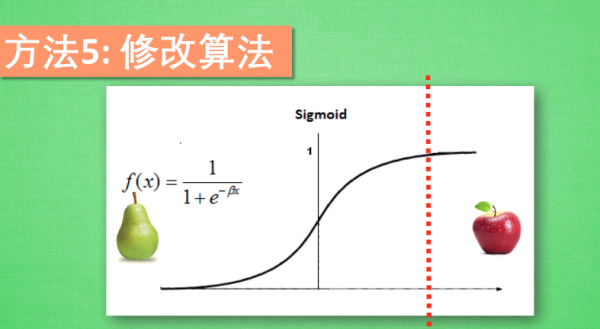
处理不均衡的数据(imbalanced data)
什么是不均衡数据 不均衡数据的形式很简单. 这里有苹果和梨, 当你发现你手中的数据对你说, 几乎全世界的人都只吃梨, 如果随便抓一个路人甲, 让你猜他吃苹果还是梨, 正常人都会猜测梨. 不均衡的数据预测起来很简单. 永远都猜多的那一方面准没错. 特别是红色多的那一方占了90%. 只需要每一次预测的时候都猜红色, 预测准确率就已经达到了相当高的90%了. 没错, 机器也懂这个小伎俩

FocusNetv2: Imbalanced large and small organ segmentation with adversarial shape constraint for head
FocusNetv2: Imbalanced large and small organ segmentation with adversarial shape constraint for head and neck CT images 发表时间:2021 发表期刊:Medical Image Analysis Abstract 放射疗法是一种使用放射线来消除癌细胞的治疗方法。危险器官 (O

Intelligent Fault Diagnosis of Machines with Small Imbalanced Data: Review | 小样本及不平衡数据下的智能故障诊断: 综述
本文是对智能故障诊断领域最新综述文章:Intelligent Fault Diagnosis of Machines with Small & Imbalanced Data: A State-of-the-art Review and Possible Extensions 的翻译,欢迎各位同行前来交流! 相关链接AbstractIntroductionResearch Methodolo

不平衡学习的方法 Learning from Imbalanced Data
之前做二分类预测的时候,遇到了正负样本比例严重不平衡的情况,甚至有些比例达到了50:1,如果直接在此基础上做预测,对于样本量较小的类的召回率会极低,这类不平衡数据该如何处理呢? 不平衡数据的定义 顾名思义即我们的数据集样本类别极不均衡,以二分类问题为例,数据集中的多数类 为 S m a x S_{max} Smax,少数类为 S m i n S_{min} Smin,通常情况下把多数类

论文泛读:Distribution aligning refinery of pseudo-label for imbalanced semi-supervised learning
论文泛读:Distribution aligning refinery of pseudo-label for imbalanced semi-supervised learning

类别不平衡分类:CReST: A Class-Rebalancing Self-Training Framework for Imbalanced Semi-Supervised Learning
一句话总结: 分类问题中的两大难题: 1.类别不平衡 2.标注数据少,半监督学习 这篇文章,将这两个问题都包含进来了,那么看看作者是如何处理这两大难题。 长尾分布(Long-Tailed Distribution) 自然界中收集的样本通常呈长尾分布,即收集得到的绝大多数样本都属于常见的头部类别(例如猫狗之类的),而绝大部分尾部类别却只能收集到很少量的样本(例如熊猫、老虎),这