hiveql专题

问题解决:java运行HiveQL,报错:java.lang.NoClassDefFoundError: org/apache/hadoop/conf/Configuration
文章目录 问题场景问题环境问题原因解决方案结果总结随缘求赞 问题场景 使用Java编写HiveQL语句,然后通过jdbc的方式远程连接hive集群,并执行。在执行过程中,报错,错误信息如下: java.lang.NoClassDefFoundError: org/apache/hadoop/conf/Configurationat org.apache.hive.jdbc.Hi
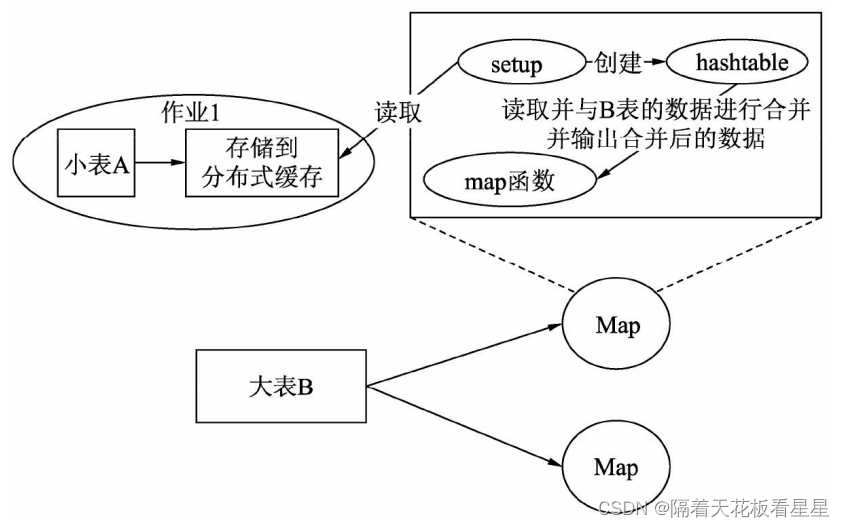
HiveQL性能调优-概览
一、铺垫 1、HiveQL 在执行时会转化为各种计算引擎的能够运行的算子,这里以mr引擎为切入点,要想让HiveQL 的效率更高,就要理解HiveQL 是如何转化为MapReduce任务的 2、hive是基于hadoop的,分布式引擎采用mr、spark、tze,调度使用的yarn,分布式存储使用的hdfs,而一般大数据的性能瓶颈往往在带宽消耗和磁盘IO,cpu往往不是瓶颈。因此hive优化

HiveQL练习(hive3.x)
零、准备工作 1. Hive环境安装 参见搭建Hive 3.x环境(CentOS 9 + Hadoop3.x) 2. 准备数据 在虚拟机HOME目录创建如下文件内容: cd /rootvi emp.csv 内容如下: 7369,SMITH,CLERK,7902,1980/12/17,800,,207499,ALLEN,SALESMAN,7698,1981/2/20,1600,3

Postgresql、HiveQL时间日期比较及加减写法
一、postgreSQL ----当前时间 now() >>2018-09-14 16:46:51.103709+08 current_timestamp >>2018-09-14 16:47:58.547305+08----当前日期 current_date >>2018-09-14 ----小于某个固定时间 create_time < to_date('2018-09-04
HiveQL——不借助任何外表,产生连续数值
注:参考文章: HiveSql一天一个小技巧:如何不借助其他任何外表,产生连续数值_hive生成连续数字-CSDN博客文章浏览阅读1.3k次。0 需求描述输出结果如下所示:12345...1001 问题分析方法一:起始值(start)+步长(diff)=结束值(end)select split(space(5), ' ')+----------------------+| _c0 |+-----

Hive 读书笔记3:HiveQL Data Definition(上)
HiveQL可以认为是SQL的一种方言,它不完全遵循任何一个版本的ANSI SQL标准,它似乎跟MySQL比较接近,但有一个显著地不同:Hvie不支持行级别的Insert、Update和Delete,并且Hive不支持事务。 创建一个库:create database mydb; 或者create database if not exists mydb; 删除库:DROP DATABA
HiveQL Tips
在Hive中,某些小技巧可以让我们的Job执行得更快,有时一点小小的改动就可以让性能得到大幅提升,这一点其实跟SQL差不多。 首先,Hive != SQL,虽然二者的语法很像,但是Hive最终会被转化成MapReduce的代码去执行,所以数据库的优化原则基本上都不适用于 Hive。也正因如此,Hive实际上是用来做计算的,而不像数据库是用作存储的,当然数据库也有很多计算功能,但一般并不建议在
HiveQL常用查询函数——nvl、case when、concat、collect_set、collect_list、explode lateral view、窗口函数、rank
目录1. nvl(value,default_value)2. case wheneg1:对表emp_sex,求每个部门男女人数eg2:统计每个国家隶属洲的人口数(已知字段数据按照另一种条件分组)eg3:统计不同国家男女个数(完成不同条件的分组)3. concat、concat_ws、collect_set(列转行)4. explode & lateral view(行转列)5. 窗口函数(聚合函
Hive-2.HiveQL查询中分析函数
1 RANK()函数 返回数据项在分组中的排名,排名相等会在名次中留下空位 2 DENSE_RANK()函数 返回数据项在分组中的排名,排名相等会在名次中不会留下空位 3 NTILE()函数 返回n分片后的值 4 ROW_NUMBER() 为每条记录返回一个数字 5 分析函数案例实战 针对分组后,对组内数据进行排序 (1)Rank函数返回一个唯一的值,除非遇到相同的数据时
Hive-2.HiveQL查询中抽样查询
当数据集非常大的时候,我们需要找一个子集来加快数据分析。此时我们需要数据采集工具以获得需要的子集。在此可以使用三种方式获得采样数据:random sampling, bucket sampling, block sampling。 8.1随机抽样(Random sampling ) 使用RAND()函数和LIMIT关键字来获取样例数据,使用DISTRIBUTE和SORT关键字来保证数据是随
Hive-2.HiveQL查询中ORDER BY 和SORT BY 语句|包含SORT BY 的DISTRIBUTE BY|CLUSTER BY
1. ORDER BY 和SORT BY 语句 order by 会对输入做全局排序,因此只有一个reducer(多个reducer无法保证全局有序) 只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。 sort by不是全局排序,其在数据进入reducer前完成排序.因此,如果用sort by进行排序,并且设置mapred.reduce.tasks>1, 则sort
Hive-2.HiveQL查询中JOIN语句
Hive支持常用到的SQL JOIN语句,但是只支持等值连接。 4.1 INNER JOIN 内连接(INNER JOIN)中,只有进行连接的两个表中都存在与连接标准相匹配的数据才会展示出来。例如: 查询每个部门下的员工列表 查询语句: select t.deptname,e.name from employees e inner join dept t on e.dept
Hive-2.HiveQL查询中where和group by语句
1. WHERE语句 查询英语成绩大于等于70的列表: select name,ceil(salary) as salary,age from employees where score['English']>=70; 输出结果: name salary age wangwu1 5500 20 wangwu3 8400 20 wangwu4 8400 20

Hive-2.HiveQL查询中常用函数
1. SELECT ....FROM 语句 1、创建表 CREATE EXTERNAL TABLE employees( ID STRING, name STRING, AGE INT, BIRTHDAY DATE, subordinates ARRAY<STRING>, score MAP<STRING,FLOAT>, address STRUCT<street:STRING,city:ST

【Hive】08-HiveQL:索引
Hive 只有有限的索引功能。 Hive 中没有普通关系型数据库中键的概念,但是还是可以对一些字段建立索引来加速某些操作的。一张表的索引数据存储在另外一张表中。同时,因为这是一个相对比较新的功能,所以目前还没有提供很多的选择。然而,索引处理模块被设计成为可以定制的 Java 编码的插件,因此,用户可以根据需要对其进行实现,以满足自身的需求。当逻辑分区实际上太多太细而几乎无法使用时,建立索引也就成为

【Hive】07-HiveQL:视图
视图可以允许保存一个查询并像对待表一样对这个查询进行操作。这是一个逻辑结构,因为它不像一个表会存储数据。换句话说,Hive目前暂不支持物化视图。 当一个查询引用一个视图时,这个视图所定义的查询语句将和用户的查询语句组合在一起,然后供Hive制定查询计划。从逻辑上讲,可以想象为Hive先执行这个视图,然后使用这个结果进行余下后续的查询。 1、使用视图来降低查询复杂度 当查询变得长或复杂的时候,通

【Hive】06-HiveQL:查询
1、SELECT FROM语句 1.1、使用正则表达式来指定列 我们甚至可以使用正则表达式来选择我们想要的列。下面的查询将会从表stocks中选择symbol列和所有列名以price作为前缀的列: SELECT symbol ,`price.*` FROM stocks; 1.2、使用列值进行计算 用户不但可以选择表中的列,还可以使用函数调用和算术表达式来操作列值。例如,我们可以查询得到
hiveQL学习和hive常用操作
Hive服务 Hive外壳环境是可以使用hive命令来运行的一项服务。可以在运行时使用- service选项指明要使用哪种服务。键入hive-servicehelp可以获得可用服务 列表。下面介绍最有用的一些服务。 cli Hive的命令行接口(外壳环境)。这是默认的服务。 hiveserver 让Hive以提供Trift服务的服务器形式运行,允许用不同语言编写的客