hinton专题

Hinton等人最新研究:大幅提升模型准确率,标签平滑技术 2019-7-8
导读:损失函数对神经网络的训练有显著影响,也有很多学者人一直在探讨并寻找可以和损失函数一样使模型效果更好的函数。后来,Szegedy 等学者提出了标签平滑方法,该方法通过计算数据集中 hard target 的加权平均以及平均分布来计算交叉熵,有效提升了模型的准确率。近日,Hinton 团队等人在新研究论文《When Does Label Smoothing Help?》中,就尝试对标签平滑技术对

“神经网络之父”和“深度学习鼻祖”Geoffrey Hinton
“神经网络之父”和“深度学习鼻祖”Geoffrey Hinton在神经网络领域数十年如一日的研究,对深度学习的推动和贡献显著。 一、早期贡献与突破 反向传播算法的引入:Hinton是将反向传播(Backpropagation)算法引入多层神经网络训练的学者之一。这一算法在神经网络训练中起到了至关重要的作用,为深度学习的发展奠定了坚实的基础。 波尔兹曼机的发明:Hinton等人联合发明了波尔兹曼
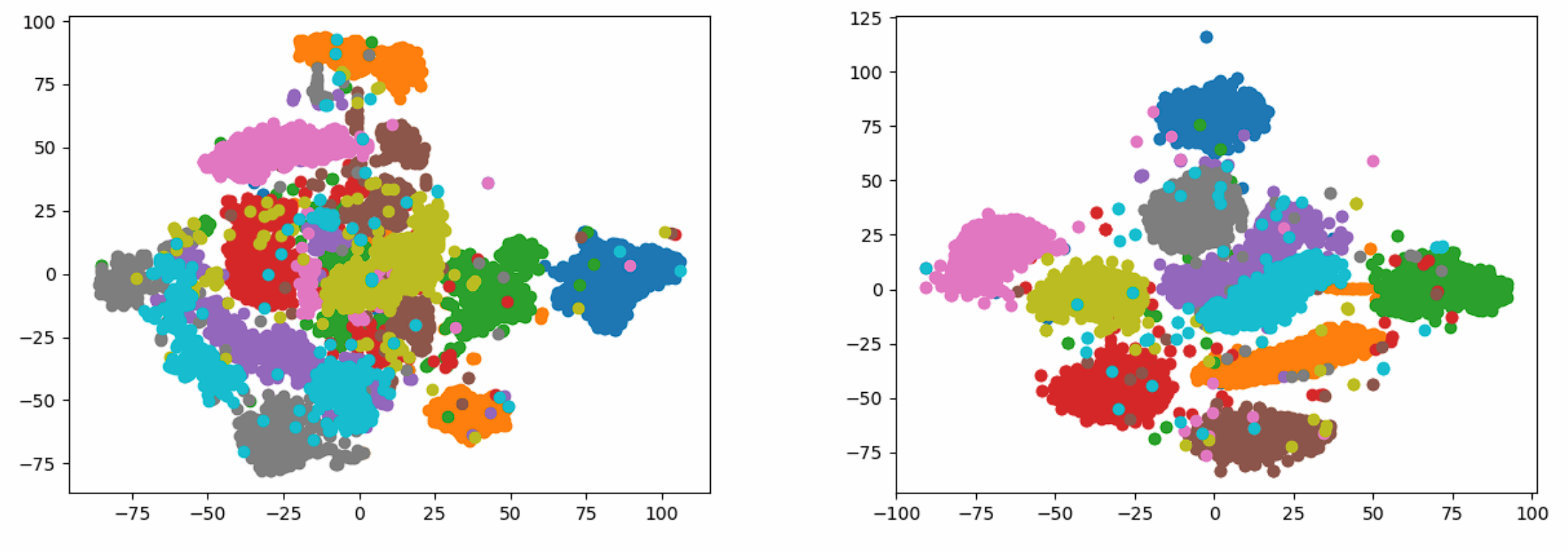
十几年前的降维可视化算法有这么好的效果?还得是Hinton。带你不使用任何现成库手敲t-SNE。
问题描述 依据Visualizing Data using t-SNE实现t-SNE算法,并对MNIST或者Olivetti数据集进行可视化训练。 有以下几点要求: 不能使用现成的t-SNE库,例如sklearn等;可以使用支持矩阵、向量操作的库实现,例如numpy;将数据降低至二维,同一类型的数据使用同一种颜色绘制散点图。 符号介绍 x i x_i xi:第 i i i个原始数据;
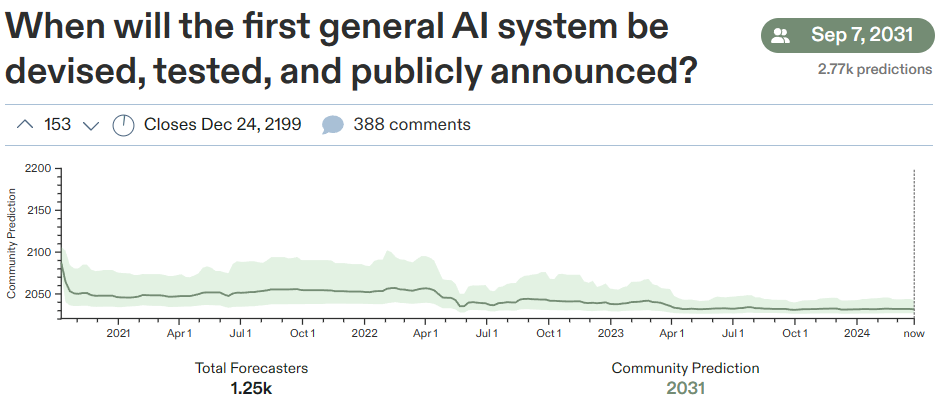
AGI争论燃爆!奥特曼、马斯克、杨立坤、Hinton一众大佬关于“AGI何时降临?”的讨论
随着Sora、Claude 3的亮相以及GPT-5的预告,一个激动人心的话题不断被提起:如果存在一种智能能够超越人类,那么世界将会变成什么样子? 更引人注目的问题是,我们究竟能在何时迎来这样的“超级AI”? GPT-3.5研究测试: https://hujiaoai.cn GPT-4研究测试: https://higpt4.cn 不同行业的专家都在关注AGI何时能够成为现实。让我们一起
Hinton是如何理解PCA
前言 “深度学习名校课程大全” 里面给出了很多深度学习的课程, 但是说到书的话, 还是推荐 Ian Goodfellow的 “Deep Learning”, 张志华老师带来学生有翻译成中文版本。 里面就提到了Hinton 辛顿( 参考 攒说 Geoff Hinton ) 对PCA的理解,实在高明! 如果你没有看过的话,可以找来看看, 有开放的PDF版。 千万不要小看PCA,

【深度学习】主要提出者【Hinton】中国大会最新演讲【通往智能的两种道路】
「但我已经老了,我所希望的是像你们这样的年轻有为的研究人员,去想出我们如何能够拥有这些超级智能,使我们的生活变得更好,而不是被它们控制。」 6 月 10 日,在 2023 北京智源大会的闭幕式演讲中,在谈到如何防止超级智能欺骗、控制人类的话题时,今年 75 岁的图灵奖得主 Geoffrey Hinton 不无感慨地说道。 Hinton 本次的演讲题目为「通往智能的两种道路」(Two Pat

【深度学习下一大突破】吴恩达对话 Hinton、Bengio、Goodfellow(视频)
【深度学习下一大突破】吴恩达对话 Hinton、Bengio、Goodfellow(视频) [日期:2017-08-11]来源:新智元 作者:[字体:大 中 小] 【新智元导读】吴恩达深度学习系列课程 Deeplearning.ai 上线,专设对话部分,用视频的形式将他对 7 位深度学习领袖的采访呈现出来,分别是 Geoffrey Hinton、Yoshua Beng

NeurIPS已成为了AI人才招聘的最大盛会,连Hinton都“应聘”过
在一周前美国举行的年度最热门的人工智能大会NeurIPS 2023上,有超过1万名世界顶尖AI研究人员聚集在此。 而除了研究员之外,中国科技公司和华尔街公司是其中最突出的参会者,他们都背负着抢夺AI人才的任务。 大模型人才最受欢迎 随着今年ChatGPT和生成式AI的火爆,大模型相关的AI博士生比以往任何时候都更受欢迎。 许多AI博士生都希望能获得谷歌或OpenAI等AI公司的工作机会,并

Hinton Neural Network课程笔记11b: 利用Hopfield Net进行信息存储
课程简介 Geoffrey Hinton 2012年在coursera上开的网课:Neural Networks for Machine Learning。 课程笔记 关于Hopfield的简单定义与应用,请参考Hinton Neural Network课程笔记11a: Hopfield Net的定义与应用。关于Hopfield的详细介绍,可以参考《现代模式识别(第二版)》(里面包括对于Ho

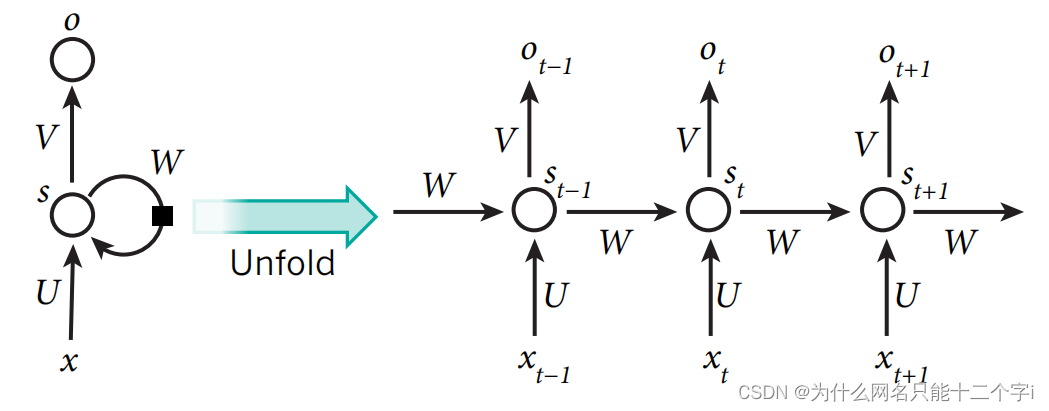
Hinton机器学习与神经网络2
文章目录 Hinton机器学习与神经网络2二、感知器的学习过程1、神经网络架构介绍前馈神经网络循环神经网络双向对偶网络 2、感知器3、感知器的几何空间解析4、感知器的原理透析5、感知器的局限性5、感知器的局限性 Hinton机器学习与神经网络2 二、感知器的学习过程 1、神经网络架构介绍 前馈神经网络 信息从输入单元层开始,朝着一个方向传递,通过隐藏层直至输出层。 如

Hinton机器学习与神经网络1
文章目录 Hinton机器学习与神经网络1一、绪论:面向机器学习的神经网络1、为什么我们需要机器学习2、什么是神经元网络3、简单的神经元模型线性阈值神经元二值化阈值神经元Relu激活神经元Sigmoid神经元随机二进制神经元 4、ANN的MNIST学习范例5、机器学习算法的三大类①监督学习②强化学习③无监督学习 Hinton机器学习与神经网络1 一、绪论:面向机器学习的神经

Ilya Sutskever:师从Hinton,“驱逐”奥特曼,一个改变AI世界的天才科学
ChatGPT 已经在全球爆火,但大众在两周之前似乎更熟悉Sam Altman,而对另一位创始人 Ilya Sutskever 却了解不多。 直到前几天因为OpenA眼花缭乱的政权争夺大戏,OpenAI 的首席科学家Ilya Sutskever的名字逐渐被世人所知。 Ilya Sutskever在科学和工程实现上为ChatGPT的诞生做出了巨大贡献,可谓是ChatGPT的发明人。然而,也许是因

深度学习领域三大牛LeCun、Bengio和Hinton 联合打造史上最权威综述
原文链接:http://dataunion.org/19192.html 三大牛Yann LeCun、Yoshua Bengio和Geoffrey Hinton在深度学习领域的地位无人不知。为纪念人工智能提出60周年,最新的《Nature》杂志专门开辟了一个“人工智能 + 机器人”专题 ,发表多篇相关论文,其中包括了Yann LeCun、Yoshua Bengio和Geoffre

【Deep Learning学习笔记】Modeling Documents with a Deep Boltzmann Machine_Hinton_uai2013
题目:Modeling Documents with a Deep Boltzmann Machine 作者:HInton 发表于:UAI 2013 主要内容: 这篇文章写用神经网络来对文本(文章)进行建模的。在Replicated Softmax model的基础上,增加了一个隐含层,但是并不增加参数,用来提升模型性能。与标准RSM和LDA模型相比较,作者这个模型性能更好。
【Deep Learning Papers】Deep Learning(Yann LeCun,Yoshua Bengio,Geoffrey Hinton)
NatureDeepReview解读 1 全文翻译1.0 摘要1.1 介绍1.2 监督学习1.3 反向传播训练多层架构1.4 卷积神经网络1.5 基于深度卷积网络的图像理解1.6 分布式表征和语言处理1.7 循环神经网络1.8 深度学习的未来 深度学习三巨头对深度学习的里程碑式综述,入门经典。 原论文链接: http://www.cs.toronto.edu/~hinton/
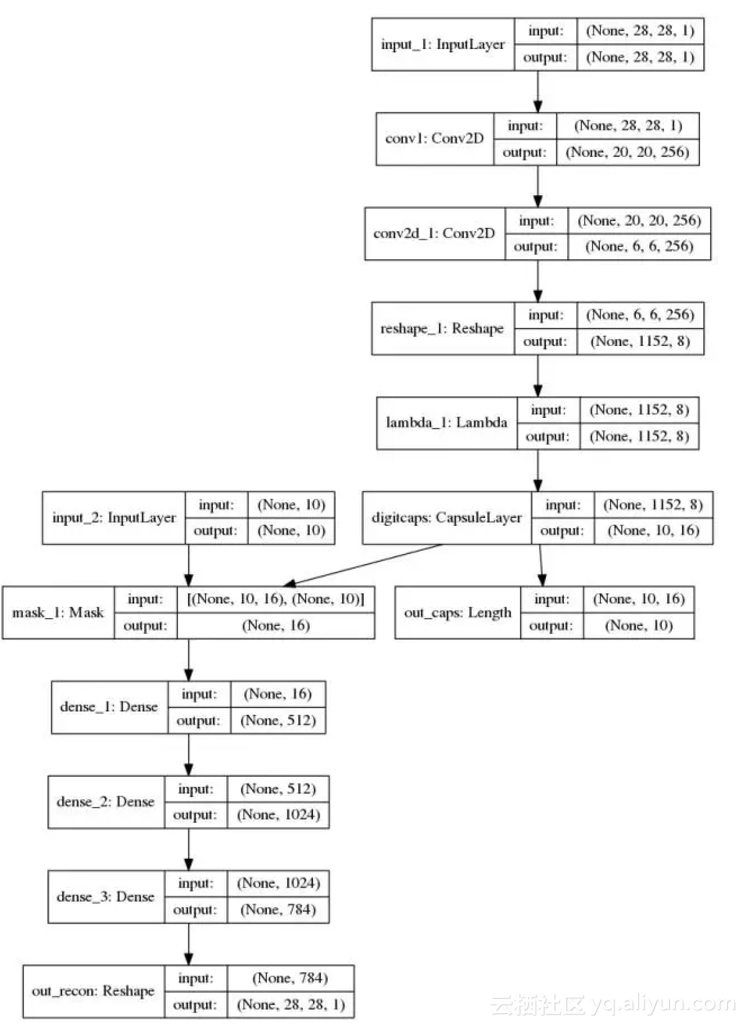
【前沿】TensorFlow Pytorch Keras代码实现深度学习大神Hinton NIPS2017 Capsule论文
10月26日,深度学习元老Hinton的NIPS2017 Capsule论文《Dynamic Routing Between Capsules》终于在arxiv上发表。今天相关关于这篇论文的TensorFlow\Pytorch\Keras实现相继开源出来,让我们来看下。 论文地址:https://arxiv.org/pdf/1710.09829.pdf Capsule 是一组神经元,其活动向量
Nature:Hinton、LeCun、Bengio三巨头权威科普深度学习
Hinton、LeCun、Bengio 是深度学习的最权威的科学家。文中介绍的网络是深度学习中最为成熟,经典的部分。读这篇文章可以对深度学习的核心模块有一个最快的认识。 背景 借助深度学习,多处理层组成的计算模型可通过多层抽象来学习数据表征( representations)。这些方法显著推动了语音识别、视觉识别、目标检测以及许多其他领域(比如,药物发现以及基因组学)的技术发展。