he3db专题

海山数据库(He3DB)数据仓库发展历史与架构演进:(一)传统数仓
从1990年代Bill Inmon提出数据仓库概念后经过四十多的发展,经历了早期的PC时代、互联网时代、移动互联网时代再到当前的云计算时代,但是数据仓库的构建目标基本没有变化,都是为了支持企业或者用户的决策分析,包括运营报表、企业营销、用户画像、BI分析等。 广义上看数据库仓库并不是一项技术或者产品而是数据处理过程,从不同的数据源进行数据汇合,然后经过数据的统一建模成适合于分析的数据模型

海山数据库(He3DB)代理ProxySQL使用详解:(二)功能实测
读写分离实测 ProxySQL官方demo演示了三种读写分离的方式:使用不同的端口进行读写分离、使用正则表达式进行通用的读写分离、使用正则和digest进行更智能的读写分离。最后一种是针对特定业务进行的优化调整,也可将其归结为第二种方式,下边分别进行测试。 基于端口的读写分离 环境准备 MySQL里创建访问用户,监控用户 SQL #创建监控账号 create user monito

海山数据库(He3DB)Redis技术实践:继承开源Redis精髓,强化升级企业级服务
数字化转型中的企业数据的处理速度和效率直接关系到企业的竞争力,Redis作为业界广泛使用的开源键值对存储系统,以其卓越的性能和丰富的数据结构,成为了众多开发者和企业的首选。然而,近期Redis开源社区对Redis协议进行了变更,从 Redis 7.4 版本开始,Redis 将从 BSD 3-Clause 开源许可证过渡到 Redis Source Available License version
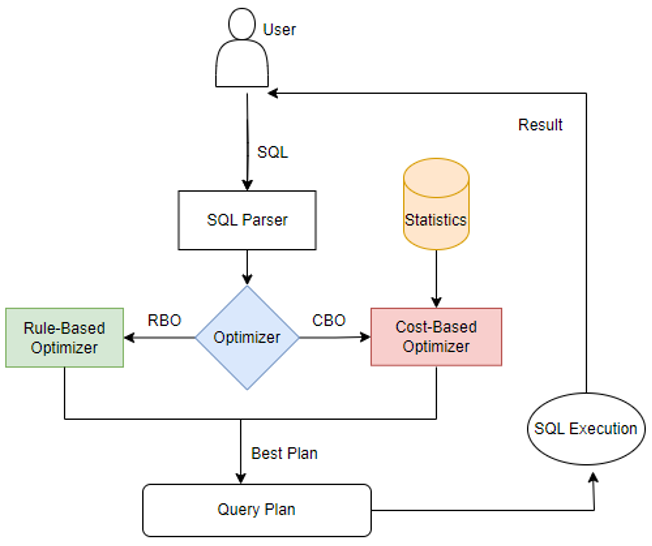
海山数据库(He3DB)原理剖析:浅析OLAP数据库计算引擎中的统计信息
背景: 统计信息在计算引擎的优化器模块中经常被提及,尤其是在基于成本成本优化(CBO)框架中统计信息发挥着至关重要的作用。CBO旨在通过评估执行查询的可能方法,并选择最有效的执行计划来提高查询性能。而统计信息则提供了关于数据分布、数据倾斜等方面的关键信息,帮助CBO做出最优的决策。无论是传统数据库MySQL、PostgreSQL,还是Hive、Spark计算引擎、Doris、StarRocks