hbase2专题

Hbase2.x新特性Hbase常见问题性优化小总结
在很早之前,我曾经写过两篇关于Hbase的文章: 《Hbase性能优化百科全书》 《Hbase FAQ热门问答小集合》 如果你没有看过,推荐收藏看一看。另外,在我的CSDN有专门的HBase专栏可以系统学习,参考: 《Hbase专栏》 https://blog.csdn.net/u013411339 本文在上面文章的基础上,新增了更多的内容,并且增加了Hbase2.x版本的新功能。
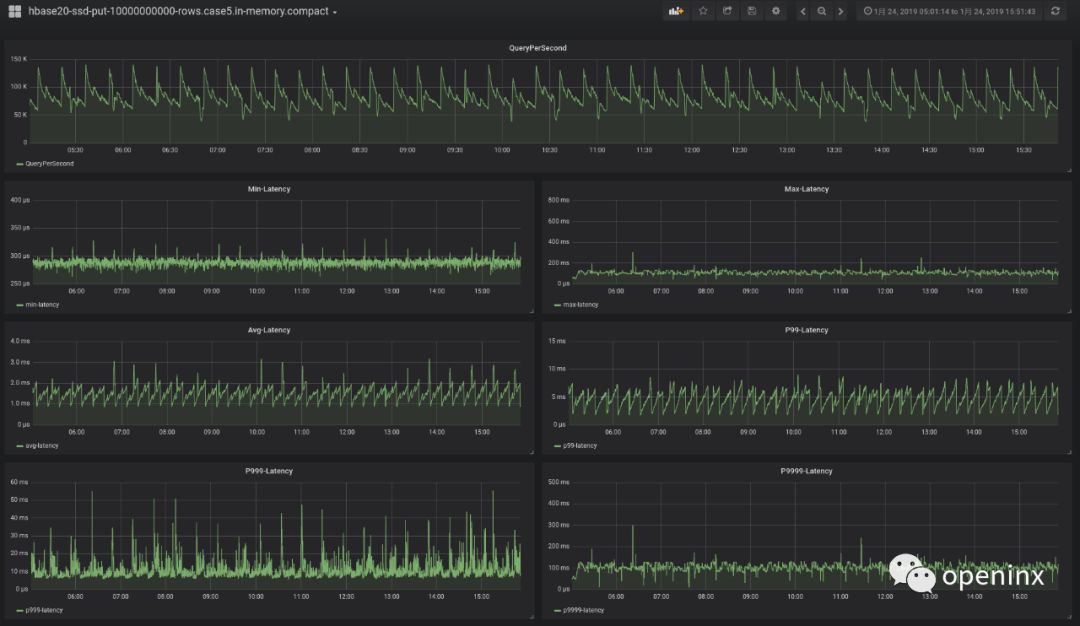
HBase实践 | 一场HBase2.x的写入性能优化之旅
HBase2.x的写入性能到底怎么样?来,不服跑个分! 首先,简单介绍一下我们的测试环境:集群由5个节点组成,每个节点有12块800GB的SSD盘、24核CPU、128GB内存;集群采用HBase和HDFS混布方式,也就是同一个节点既部署RegionServer进程,又部署DataNode进程,这样其实可以保证更好的写入性能,毕竟至少写一副本在本地。关于软件版本,我们使用的HBase2.1.2版
HBase2.x学习笔记
文章目录 一、HBase 简介1、HBase 定义1.1 概述1.2 HBase 与 Hadoop 的关系1.3 RDBMS 与 HBase 的对比1.4 HBase 特征简要 2、HBase 数据模型2.1 HBase 逻辑结构2.2 HBase 物理存储结构2.3 HBase的表数据模型 3、HBase 基本架构3.1 Master3.2 Region Server3.3 Zookeep

【生产级实践】Docker部署配置Hadoop3.x + HBase2.x实现真正分布式集群环境
网上找了很多资料,但能够实现Docker安装Hadoop3.X和Hbase2.X真正分布式集群的教程很零散,坑很多, 把经验做了整理, 避免趟坑。 一、安装Docker Hadoop3.X分布式集群 1、机器环境 这里采用三台机器来部署分布式集群环境: 192.168.1.101 hadoop1 (docker管理节点) 192.168.1.102 hadoop2 192.168
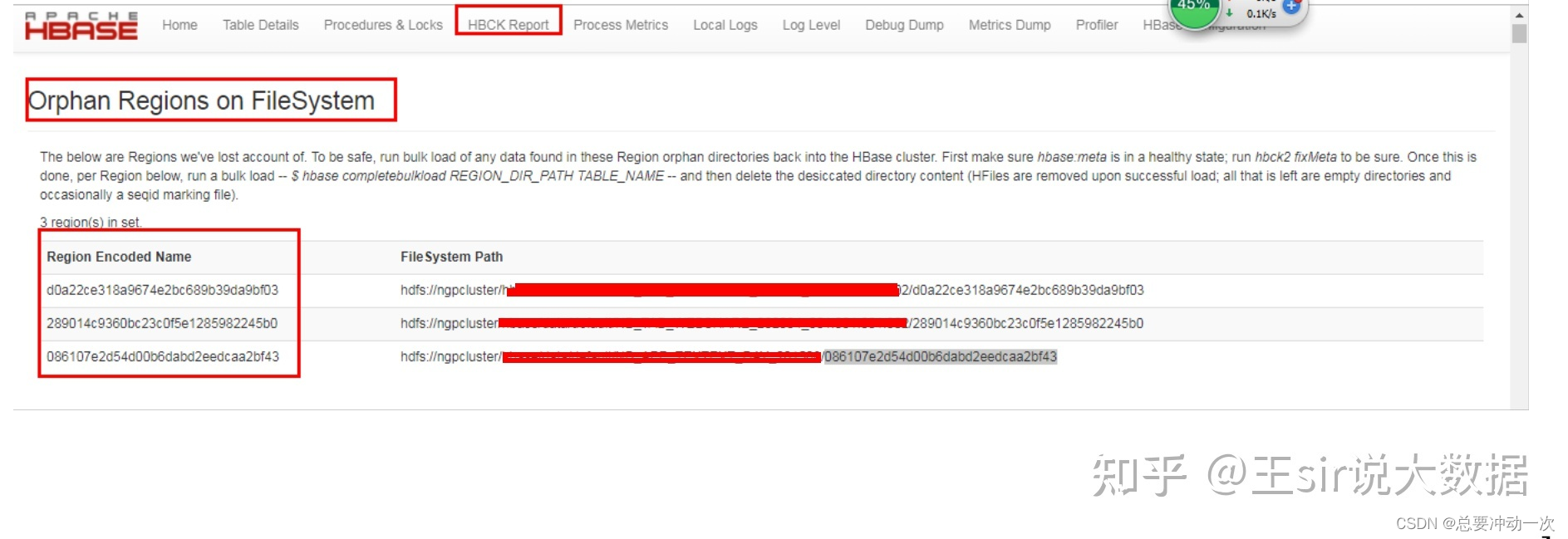
hbase2.x orphan regions on filesystem(region丢失)问题修复
orphan regions on filesystem 问题说明:表目录下存在region未上线问题,也就是说这些region下的数据你是访问不到的 可以通过主master web页面的HBCK Report查看未上线Region 也可以通过hbck2工具查看未上线Region # 查看指定表hbase hbck -j $HBASE_HOME/lib/hbase-hbck2-1.3.0-