hadoopspark专题

【转载 HadoopSpark 动手实践 2】Hadoop2.7.3 HDFS理论与动手实践
原文:http://www.cnblogs.com/licheng/p/6825089.html 简介 HDFS(Hadoop Distributed File System )Hadoop分布式文件系统。是根据google发表的论文翻版的。论文为GFS(Google File System)Google 文件系统(中文,英文)。 HDFS有很多特点: ① 保存多个副本

HadoopSpark解决二次排序问题(Hadoop篇)
问题描述 二次排序就是对每一个key对应的value进行排序,也就是对MapReduce的输出(KEY, Value(v1,v2,v3,......,vn))中的Value(v1,v2,v3,......,vn)值进行排序(升序或者降序),使得Value(s1,s2,s3,......,sn),si ∈ (v1,v2,v3,......,vn)且s1 < s2 < s3 < ......
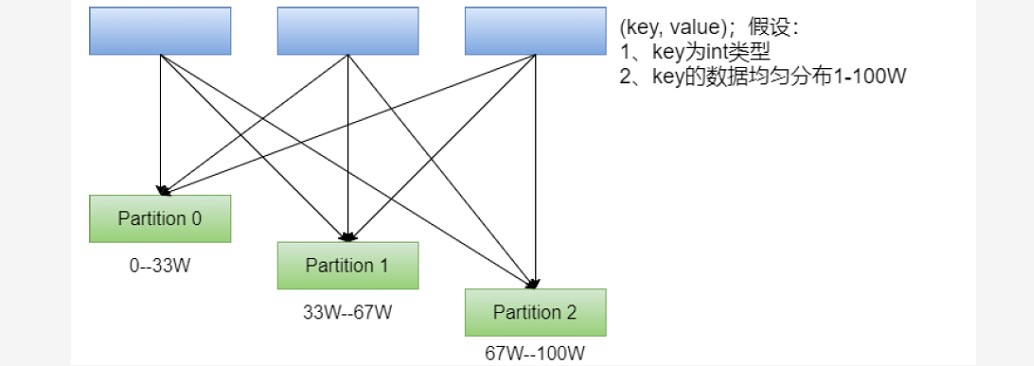
CC00032.spark——|HadoopSpark.V06|——|Spark.v06|sparkcore|RDD编程高阶RDD分区器|
一、RDD分区器 ### --- 以下RDD分别是否有分区器,是什么类型的分区器scala> val rdd1 = sc.textFile("/wcinput/wc.txt")rdd1: org.apache.spark.rdd.RDD[String] = /wcinput/wc.txt MapPartitionsRDD[34] at textFile at <console>:2