hadooper专题

hadooper-深入hadoop的调度器
Hadoop有两个大版本 0.20.x,1.x通常为hadoop 1版本,运行环境依赖JobTracker和TaskTracker,运行资源通过作业表示模型MapTask和ReduceTask来组成;运行资源通过槽位Slot来表示。 0.23.x,2.x称之为hadoop 2版本,在开发模型上类似1,都有新旧两套MapReduce API来完成;针对JobTracker的职责有YARN来管理;
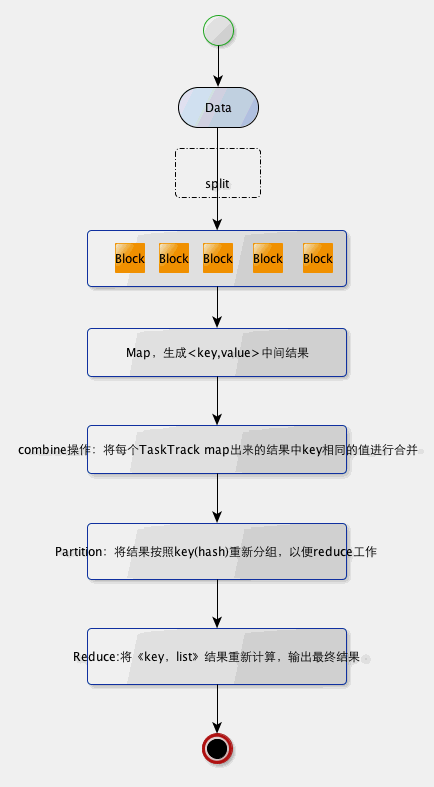
hadooper-hadoop原理-让你一目了然于心
关于hadoop的原理,可以google一下,这里用图说话。 hadoop内部结构: hadoop执行map-reduce流程图:

hadooper-关于Hadoop的shuffle
我们知道每个reduce task输入的key都是按照key排序的。 但是每个map的输出只是简单的key-value而非key-valuelist,所以洗牌的工作就是将map输出转化为reducer的输入的过程。 在map结束之后shuffle要做的事情: map的输出不是简单的写入本地文件,而是更多的利用内存缓存和预排序工作,以提高效率。i
hadooper-Hadoop中的各种排序
1:shuffle阶段的排序(部分排序) shuffle阶段的排序可以理解成两部分,一个是对spill进行分区时,由于一个分区包含多个key值,所以要对分区内的<key,value>按照key进行排序,即key值相同的一串<key,value>存放在一起,这样一个partition内按照key值整体有序了。 第二部分并不是排序,而是进行merge,merge有两次,一次是map端将多个s