hadoop2.7专题

【转载 HadoopSpark 动手实践 2】Hadoop2.7.3 HDFS理论与动手实践
原文:http://www.cnblogs.com/licheng/p/6825089.html 简介 HDFS(Hadoop Distributed File System )Hadoop分布式文件系统。是根据google发表的论文翻版的。论文为GFS(Google File System)Google 文件系统(中文,英文)。 HDFS有很多特点: ① 保存多个副本

hadoop2.7.3的安装
1. 准备工作 1.已安装的linux系统,我安装的是ubuntu16.04.2。可以用虚拟机进行安装。 jdk和hadoop的安装包。我的版本是jdk-8u121-linux-x64和hadoop-2.7.3。 2. 在linux系统下创建hadoop用户 创建hadoo用户是为了更加方便,如果只是为了实验,也可以不创建。 创建hadoop用户的命令: sudo useradd -m

Linux Hadoop2.7.3 安装(单机模式) 一
java环境安装 http://www.cnblogs.com/zeze/p/5902124.html java 环境安装配置 etc/profile: export JAVA_HOME=/usr/jdk/jdk1.8.0_112export JRE_HOME=/usr/jdk/jdk1.8.0_112/jreexport CLASSPATH=.:$JAVA_HOME/lib/dt.j
Hadoop2.7 安装
Hadoop2.7 安装 参考:http://www.linuxidc.com/Linux/2015-01/112029.html 机器准备 192.168.72.130 master 192.168.72.131 slave1 192.168.72.132 slave2 192.168.72.133 slave3 目录 安装JDK 配置host文件
ubuntu14-Hadoop2.7.2完全分布式集群搭建操作时遇到的错误
问题1 *(1)***sudo:sudo /etc/sudoers is world writable sudo:no valid sudoers sources found ,quitting sudo:unable to initialize policy plugin sudoers的权限被改了,改回来就好了。 chmod 0440 /etc/sudoers 问题2 *(2)*

Ubuntu14.04下单机、伪分布式配置Hadoop2.7.2
1.在Ubuntu14.04下创建hadoop组和hadoop用户 增加hadoop用户组,同时在该组里增加hadoop用户,后续在涉及到hadoop的操作时,均使用该用户。 1、创建hadoop用户组 2、创建hadoop用户 sudo adduser -ingroup hadoop hadoop 回车后会提示输入新的UNIX密码,这是新建用户hadoop的密码,输入回车即可。

hadoop2.7.3搭建
实验环境中搭建hadoop集群(3台示例) 1.修改主机名、修改hosts vi /etc/sysconfig/network,然后将HOSTNAME修改成hadoop-node1(自定义) vi /etc/hosts ,添加hostname及其对应的ip 2.安装jdk和配置环境变量 2.1jdk下载安装不赘述 2.2环境变量: /etc/profile文件中添加:
Eclipse中hadoop2.7.1的插件下载及安装步骤
我的eclipse、linux、windows、hadoop、zookeeper都是64位的,插件也是基于64位的,安装好的界面如下: 我上传的hadoop2.7.1插件链接: http://pan.baidu.com/s/1i3LaXO5 密码: pkqm 整个的过程可以参考如下,这边文章 我就不重复这个过程了:http://my.oschina.net/muou/blog/4085
基于HA的hadoop2.7.1完全分布式集群搭建
本文的前提是假设你已经成功安装一台服务器的hadoop伪分布式,因此有些细节没有具体给出解释(http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/SingleCluster.html)。 参考文章:http://hadoop.apache.org/docs/r2.7.1/hadoop-project-di

hive安装 (hive1.2.1+hadoop2.7+mysql)
1. 下载解压 cd /mk/softtar -xvzf apache-hive-1.2.1-bin.tar.gz -C /appl/cd /applmv apache-hive-1.2.1-bin hive-1.2.1 2. 配置环境变量 vi /etc/profileexport HIVE_HOME=/appl/hive-1.2.1export PATH=$PATH:

CentOS7下基于Hadoop2.7.3集群搭建
一、准备工作 1.修改Linux主机名 2.修改IP 3.修改主机名和IP的映射关系 4.关闭防火墙 5.ssh免登陆 6.安装JDK,配置环境变量等 7.集群规划: 主机名 IP 所需安装工具 运行进程 hadoop01 220.192.10.10 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMa

Hadoop2.7.3伪分布式搭建
1.安装JDK ①找到自己的jdk压缩文件的目录,解压:tar -zxvf jdk-8u112-linux-x64.tar.gz -c /usr/java ②配置环境变量: 输入命令:vim /etc/profile 在结尾添加以下内容: 刷新资源:source /etc/profile 2.安装Hadoop-2.7.3 ①解压Hadoop到指定文件夹中:tar -zxvf
CentOS-6.4下安装hadoop2.7.3
一.环境介绍 实验安装使用hadoop的版本为stable版本2.7.3,下载地址为: http://www-eu.apache.org/dist/hadoop/common/ 实验总共三台机器: [hadoop@hadoop1 hadoop]$ cat /etc/hosts127.0.0.1 localhost localhost.localdomain

Hadoop(二)CentOS7.5搭建Hadoop2.7.6完全分布式集群
一 完全分布式集群(单点) Hadoop官方地址:http://hadoop.apache.org/ 1 准备3台客户机 1.1防火墙,静态IP,主机名 关闭防火墙,设置静态IP,主机名此处略,参考 Linux之CentOS7.5安装及克隆 1.2 修改host文件 我们希望三个主机之间都能够使用主机名称的方式相互访问而不是IP,我们需要在hosts中配置其他主机的host。因此我
Hadoop2.7.3源码编译教程
转于:hadoop 2.7.3 源码编译教程 一、工具准备 最靠谱的是hadoop说明文档里要求具备的那些工具。 1、Hadoop2.7.3下载 安装哪个版本的hadoop,需要进入各个源码查看requirements 进入hadoop官网,点击source下载hadoop-2.7.3-src.tar.gz解压:tar -zxvf hadoop-2.7.3-src.tar.gz进入hadoo
HDFS HA 集群搭建 - 基于Quorum Journal Manager(hadoop2.7.1)
0、前置概念 0.1 checkpoint 检查点 在Hadoop分布式文件系统(HDFS)中,检查点(Checkpointing)是一个关键的过程,它涉及到将文件系统的命名空间状态持久化到磁盘。这个状态由两部分组成:EditLogs和FsImage。 EditLogs:记录了自FsImage生成后对文件系统所做的所有修改。每次对文件系统的修改都会追加到EditLogs中。FsImage:包

Hadoop环境搭建(ubuntu+hadoop2.7 - 伪分布式)
Hadoop简介 在进行环境搭建之前,先简要回顾一下Hadoop的基本知识。 Hadoop背景 Hadoop是面向集群的分布式并行计算框架(cluster、distributed、parallel),其核心组成是HDFS分布式文件系统和MapReduce并行编程模型。在开发者的业务背景下(如数据分析项目),Hadoop可被视为一套工具,它解决了并行计算中的种种复杂问题(如分布式存储,任务调度

Hadoop2.7.3 mapreduce(一)原理及hello world实例
MapReduce编程模型 【1】先对输入的信息进行切片处理。 【2】每个map函数对所划分的数据并行处理,产生不同的中间结果输出。 【3】对map的中间结果数据进行收集整理(aggregate & shuffle)处理,交给reduce。 【4】reduce进行计算最终结果。 【5】汇总所有reduce的输出结果。 【名词解释】 ResourceManager:是YAR

关于Hadoop2.7.2运行wordcount
1.每次机器重启后需要重新format否则namenode无法启动的问题,解决办法就是修改core-site.xml,在你的hadoop安装目录添加临时文件夹。 <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoophome/hadoop_tmp</value> </property>

hadoop2.7.2详细完整配置
我的hadoop2.7安装目录/usr/local/hadoop 配置文件在/usr/local/hadoop/etc/hadoop,几个重要的配置文件分别为: slaves主机名 core-site.xml 全局配置 yarn-site.xml YARN框架

hadoop2.7.5安装使用(一)
使用centos6.5虚拟机安装ip:192.168.0.31 创建目录 /opt --父目录 /opt/modules --存放软件的安装目录 /opt/softwares --存放软件包(tar,zip,bin) /opt/tools --存储工具目录(eclipse等) /opt/data --存储测试数据 /home/hadoop --存储工具盒测数据目录

《Hadoop》呶呶不休(五)Windows10下的Eclipse搭建Hadoop2.7.3开发环境
在这一章里,我们来学习如何在Windows操作系统下,搭建Hadoop2.7.3集群的Eclipse开发环境。 一、准备工作 1、安装Hadoop2.7.3集群 我们使用VMware工具安装多台Linux系统,然后在Linux系统上搭建我们所需要的Hadoop2.7.3完全分布式集群。具体步骤可以参考我写的《Hadoop》之"踽踽独行"(十)快速搭建一个Hadoop完全分布式集群或者是另一篇
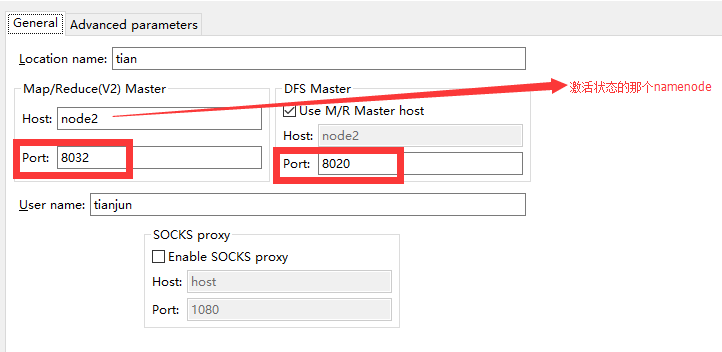
Hadoop2.7.3单机伪分布式环境搭建
Hadoop2.7.3单机伪分布式环境搭建 作者:家辉,日期:2018-07-10 CSDN博客: http://blog.csdn.net/gobitan 说明:Hadoop测试环境经常搭建,这里也做成一个模板并记录下来。 基础环境:CentOS7模板,参考: https://blog.csdn.net/gobitan/article/details/80993
CentOS7.0+Hadoop2.7.2+Hbase1.2.1搭建教程
1、软件版本 CentOS-7.0 -1406-x86_64-DVD.iso jdk-7u80-linux-x64.tar.gz hadoop-2.7.2.tar.gz hbase-1.2.1-bin.tar.gz 2、集群配置 主机: Master.Hadoop IP地址: 192.168.1.100 主机: Slave1.Hadoop
搭建Hadoop2.7.3+Hive2.1.1及MySQL(配置Hive+Hadoop)(二)
续上一篇: 搭建Hadoop2.7.3+Hive2.1.1及MySQL(配置Hadoop)(一) 1、 创建文件夹 1.1、在hive文件下创建文件夹 [root@localhost hive]# cd /usr/hive[root@localhost hive]# mkdir warehouse 1.2、/tmp系统目录下创建方法 [root@localhost tmp