gpt4v专题

极速体验媲美GPT4V的国产开源视觉大模型CogVLM2(赠书)
大家好,我是每天分享AI应用的萤火君! 文末赠书 CogVLM2是一款视觉语言模型(Visual Language Model),由智谱AI和清华KEG潜心打磨。这款模型是CogVLM的升级版本,支持高达 1344 * 1344 的图像分辨率,提供支持 中英文双语 的开源模型版本。 这类模型可以做很多跨领域的活儿,比如给图片配上描述文字、回答关于图片的问题(这叫VQA,就是视觉问答)、或者根

GPT4v和Gemini-Pro调用对比
要调用 GPT-4 Vision (GPT-4V) 和 Gemini-Pro,以下是详细的步骤分析,包括调用流程、API 使用方法和两者之间的区别,以及效果对比和示例。 GPT-4 Vision (GPT-4V) 调用步骤 GPT-4 Vision 主要通过 OpenAI 的 API 进行调用,用于处理文本和图像输入。以下是调用 GPT-4V 的详细步骤: 步骤 1: 获取 OpenAI A
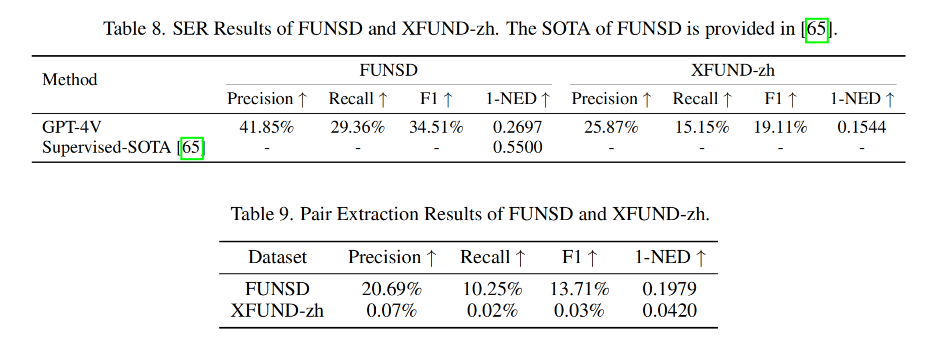
【多模态】30、GPT4V_OCR | GPT4V 在 OCR 数据集上效果测评
文章目录 一、背景二、测评2.1 场景文本识别2.2 首先文本识别2.3 手写数学公式识别2.4 图表结构识别(不考虑单元格中的文本内容)2.5 从内容丰富的文档中抽取信息 三、讨论 论文:EXPLORING OCR CAPABILITIES OF GPT-4V(ISION) : A QUANTITATIVE AND IN-DEPTH EVALUATION 代码:https
Gradio测试-->Gradio映射-->可视化GPT4V API-->Gemini Pro、Claude和Qwen的API
Gradio测试 import gradio as grimport timedef demo_test(text, image=None):time.sleep(1) # 正确的暂停调用return text, image if image is not None else None# 创建 Gradio 接口iface = gr.Interface(fn=demo_test,input