gpt3专题

NLP主流大模型如GPT3/chatGPT/T5/PaLM/LLaMA/GLM的原理和差异有哪些-详细解读
自然语言处理(NLP)领域的多个大型语言模型(如GPT-3、ChatGPT、T5、PaLM、LLaMA和GLM)在结构和功能上有显著差异。以下是对这些模型的原理和差异的深入分析: GPT-3 (Generative Pre-trained Transformer 3) 虽然GPT-4O很火,正当其时,GPT-5马上发布,但是其基地是-3,研究-3也是认识大模型的一个基础 原理 架构: 基于

GPT3 终极指南(一)
原文:zh.annas-archive.org/md5/6de8906c86a2711a5a84c839bec7e073 译者:飞龙 协议:CC BY-NC-SA 4.0 前言 GPT-3,或者说是 Generative Pre-trained Transformer 3,是由 OpenAI 开发的基于 Transformer 的大型语言模型。它包含了惊人的 1750 亿个参数。任何人都
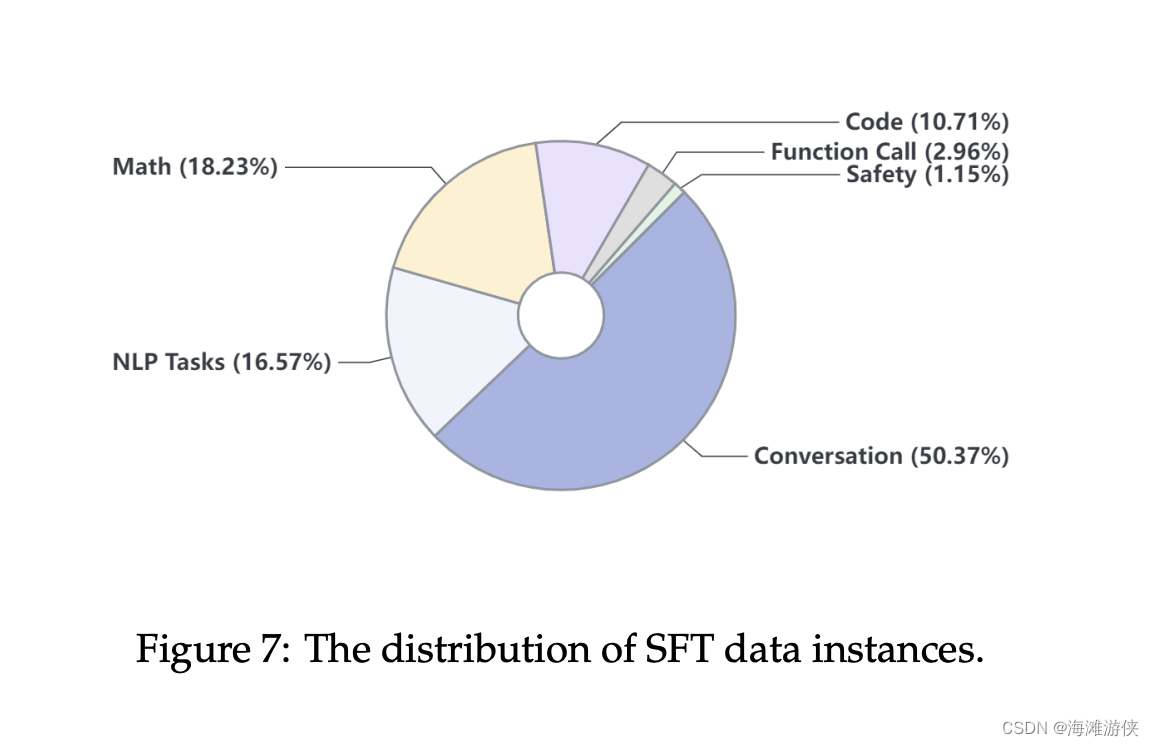
GPT3, llama2, InternLM2技术报告对比
GPT3(September 22, 2020)是大语言应用的一个milestone级别的作品,Llama2(February 2023)则是目前开源大模型中最有影响力的作品,InternLM2(2023.09.20)则是中文比较有影响力的作品。 今天结合三篇技术汇报,尝试对比一下这三个方案的效果。 参考GPT3,关于模型(Model and Architectures)的介绍分为了几个部
智障版本GPT3实现
背景,实现GPT3,采用python代码。调库hf及tf2.0+基础。 由于完全实现GPT模型及其预训练过程涉及大量的代码和计算资源,以下是一个基于TensorFlow 2.x的简化版GPT模型构建和调用的示例。请注意,这仅展示了模型的基本结构,实际运行需替换为真实数据集和预处理步骤,且无法直接在个人计算机上训练大模型如GPT-3。import tensorflow as tf from tra
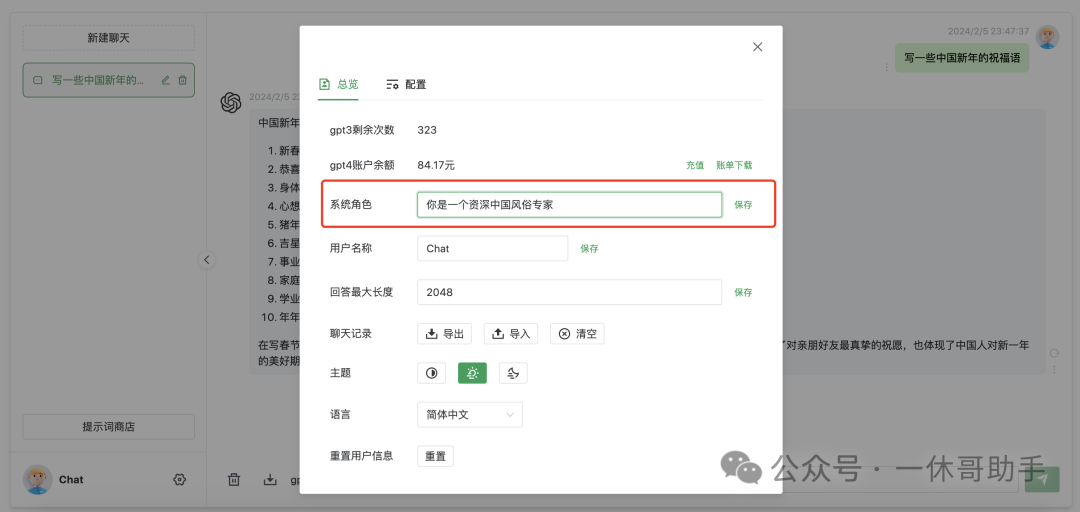
如何辨别GPT3还是GPT4?
辨别后台使用的是GPT3还是GPT4可以提问以下问题验证: 1.昨天的当天的明天是哪天? 2.树上有9只鸟,猎人射杀了一只,还剩下多少只? 3.为什么周树人要打鲁迅? GPT3回答: GPT4回答: 如何使用上面的chatGpt提问: 1.关注下面的微信公众号:一休哥助手 2.切换到菜单栏,点击网页版获取网页版地址:https://www.fudai.fun

调用GPT3接口的一些参数
GPT3接口 官方文档 API Reference 调用 temperature 通过设置合适的 temperature 值和观察每个 token 的概率,判断输出的确定性和可靠性,避免与直觉不符的结果。 在实际应用中,这两个参数非常有价值。聊天应用可设置较高 temperature 值,增加多样性;回答科学问题可设置较低 temperature 值,避免错误信息。 logprobs

今年英语高考,CMU用重构预训练交出134高分,大幅超越GPT3!
视学算法报道 机器之心编辑部 本文提出的重构预训练(reStructured Pre-training,RST),不仅在各种 NLP 任务上表现亮眼,在高考英语上,也交出了一份满意的成绩。 我们存储数据的方式正在发生变化,从生物神经网络到人工神经网络,其实最常见的情况是使用大脑来存储数据。随着当今可用数据的不断增长,人们寻求用不同的外部设备存储数据,如硬盘驱动器或云存储。随着深度学习技术的兴

22LLMSecEval数据集及其在评估大模型代码安全中的应用:GPT3和Codex根据LLMSecEval的提示生成代码和代码补全,CodeQL进行安全评估
LLMSecEval: A Dataset of Natural Language Prompts for Security Evaluations 写在最前面主要工作 课堂讨论大模型和密码方向(没做,只是一个idea) 相关研究提示集目标NL提示的建立NL提示的建立流程 数据集数据集分析 存在的问题 写在最前面 本文为邹德清教授的《网络安全专题》课堂笔记系列的文章,本次专题主题
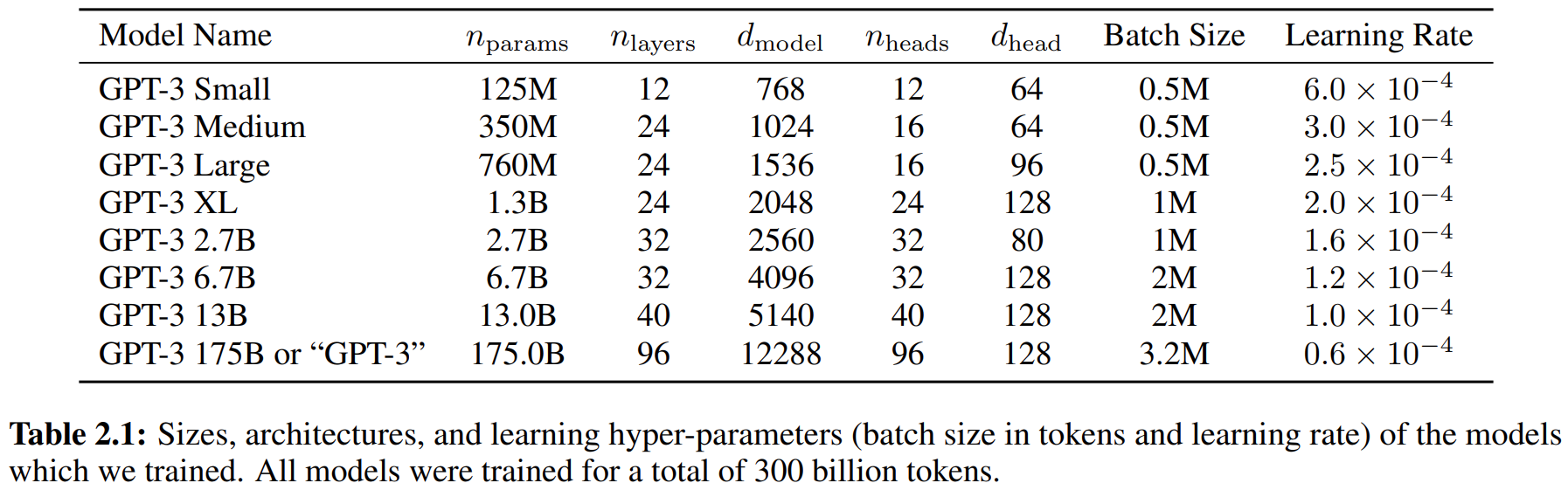
论文阅读——GPT3
来自论文:Language Models are Few-Shot Learners Arxiv:https://arxiv.org/abs/2005.14165v2 记录下一些概念等。,没有太多细节。 预训练LM尽管任务无关,但是要达到好的效果仍然需要在特定数据集或任务上微调。因此需要消除这个限制。解决这些问题的一个潜在途径是元学习——在语言模型的背景下,这意味着该模型在训练时发展了一

《预训练周刊》第31期:OpenAI发表可定制版GPT3、谷歌提出精简自注意力算法
No.31 智源社区 预训练组 预 训 练 研究 观点 资源 活动 关于周刊 本期周刊,我们选择了12篇预训练相关的论文,涉及模型规模、表情符号生成、零样本图像生成、自注意力、语言模型、视频理解、多模态、对比学习、分子表征、抗体预测、蛋白作用预测和多模态测评的探索。此外,在研究动态方面,我们选择了1篇预训练资讯,将介绍大模型微调方面的一些最新内容。 周刊采用社区协作的模式产生,欢迎感兴趣的朋友

大力出奇迹——GPT系列论文学习(GPT,GPT2,GPT3,InstructGPT)
目录 说在前面1.GPT1.1 引言1.2 训练范式1.2.1 无监督预训练1.2.2 有监督微调1.3 实验 2. GPT22.1 引言2.2 模型结构2.3 训练范式2.4 实验 3.GPT33.1引言3.2 模型结构3.3 训练范式3.4 实验3.4.1数据集3.5 局限性 4. InstructGPT4.1 引言4.2 方法4.2.1 数据收集4.2.2 各部分模型 4.3 总结