glip专题
GLIP,FLIP论文阅读
Scaling Language-Image Pre-training via Masking(FLIP,2023)👍 贡献: 1.图像端引入MAE的随机MASK,image encoder只处理未mask的patches(和之前的MAE方法一致),减少了输入序列长度加速训练,减少memory开销。 text端没引入mask是因为text信息比较dense(图片信息比较稀疏),mas

GLIP DetCLIP
1 GLIP: 十分钟解读GLIP:Grounded Language-Image Pre-training - 知乎 Grounded Language-Image Pre-training(GLIP)论文笔记 - 知乎 GLIP的主要贡献如下: 将phrase grounding和目标检测任务统一,将image和text prompt同时输入到目标检测网络中,prompt中带有图片

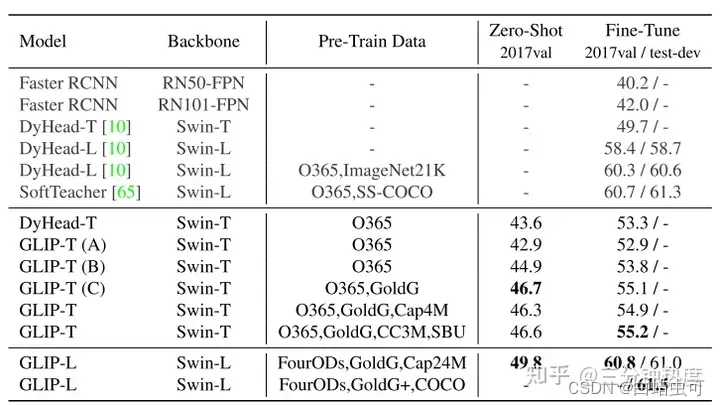
论文阅读-(GLIP)Grounded Language-Image Pre-training (目标检测+定位)
Paper:Grounded Language-Image Pre-training Code:https://github.com/microsoft/GLIP 简介: 定位任务与图像检测任务非常类似,都是去图中找目标物体的位置,目标检测为给出一张图片找出bounding box,定位为给出一个图片和文本,根据文本找出物体。GLIP 模型统一了目标检测(object detection)