gb2312专题

电脑没有仿宋GB2312字体怎么办? 仿宋GB2312字体下载安装及调出来的教程
《电脑没有仿宋GB2312字体怎么办?仿宋GB2312字体下载安装及调出来的教程》仿宋字体gb2312作为一种经典且常用的字体,广泛应用于各种场合,如何在计算机中调出仿宋字体gb2312?本文将为您... 仿宋_GB2312是公文标准字体之一,仿China编程宋是字体名称,GB2312是字php符编码标准名称(简

批量文件编码转换用python实现的utf8转gb2312,vscode设置特殊文件的默认打开编码
批量文件编码转换用python实现的utf8转gb2312, 任意编码之间的相互转换都是可以的.改一下下面的参数即可 convert.py文件内容如下 import osimport globimport chardet#检测文件编码类型def detect_file_encoding(file_path):with open(file_path, 'rb') as f:data = f

ASCII、GB2312、Unicode和UTF-8
ASCII 我们知道,计算机内部,所有信息最终都是一个二进制值。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从00000000到11111111。 上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一

Python实现文件(xml,txt)编码转换GB2312、GBK、UTF-8
Python实现文件编码转换GB2312、GBK、UTF-8 1、查看文件编码格式 import chardetfilename = './flash.c'with open(filename, 'rb') as f:data = f.read()encoding_type = chardet.detect(data)print(encoding_type) 运行结果: 2、文件编码

utf-8和GB2312互转
转自CSDN,出处未知 UTF-8转GB2312: char* convertUTF8ToGB2312(const char* utf8){int len = MultiByteToWideChar(CP_UTF8, 0, utf8, -1, NULL, 0);wchar_t* wstr = new wchar_t[len+1];memset(wstr, 0, len+1);MultiByt

字符集、字符编码、国际化、本地化简要总结(UNICODE/UTF/ASCII/GB2312/GBK/GB18030)
PS:要转载请注明出处,本人版权所有。 PS: 这个只是基于《我自己》的理解, 如果和你的原则及想法相冲突,请谅解,勿喷。 环境说明 普通的linux 和 普通的windows。 VS2015 和 GCC 7.0 前言 曾记得,我在(https://blog.csdn.net/u011728480/article/details/100277582 《数与计算机 (编码、原码

编码GBK和GB2312、Unicode、UTF-8
一、编码GBK和GB2312 随着计算机发展,各国已经不满足于单纯用ASCII码; 对于我们来说能在计算机中显示中文字符是至关重要的,所以我们还需要一张关于中文和数字对应的关系表; 一个字节8位二进制,只能最多表示256个字符,要处理中文显然一个字节是不够的; 所以我们需要采用两个字节来表示,而且还不能和ASCII编码冲突; 所以1980年中国制定了GB2312编码,国家简体中文字
编码 字符集 历史 utf-8 gb2312 gbk unicode
1、美国人首先对其英文字符进行了编码,也就是最早的ascii码,用一个字节的低7位来表示英文的128个字符,高1位统一为0; 2、后来欧洲人发现尼玛你这128位哪够用,比如我高贵的法国人字母上面的还有注音符,这个怎么区分,得,把高1位编进来吧,这样欧洲普遍使用一个全字节进行编码,最多可表示256位。欧美人就是喜欢直来直去,字符少,编码用得位数少; 3、但是即使位数少,不同国家地区用不同的字符
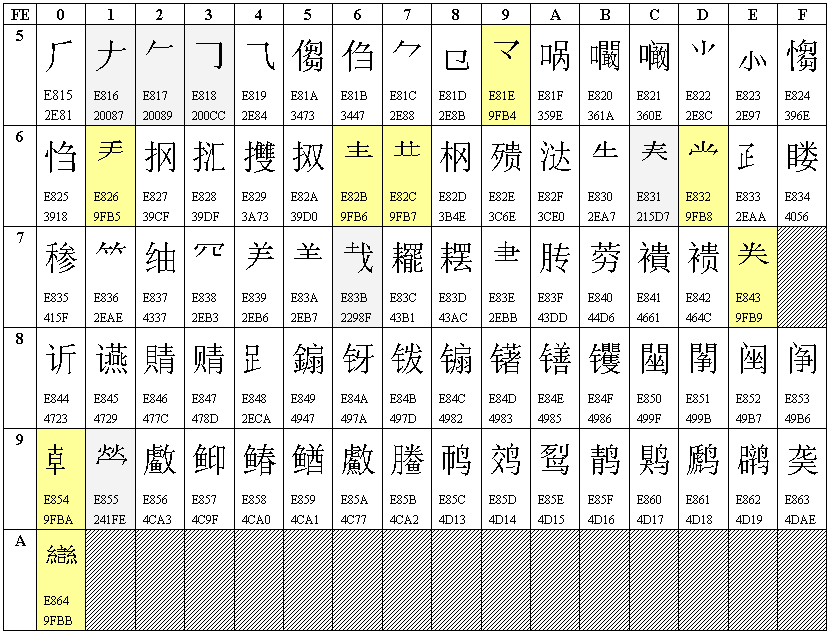
Unicode、GB2312、GBK和GB18030中的汉字
Unicode、GB2312、GBK和GB18030中的汉字 GB18030有两个版本:GB18030-2000和GB18030-2005。GB18030-2000是GBK的取代版本,它的主要特点是在GBK基础上增加了CJK统一汉字扩充A的汉字。GB18030-2005的主要特点是在GB18030-2000基础上增加了CJK统一汉字扩充B的汉字。本文数一数GB18030中的汉字,也顺便看看其它标
txt文本转编码格式(支持utf-8、GBK、GB2312、GB18030、BIG5等所有编码格式)
txt文本转编码格式(支持utf-8、GBK、GB2312、GB18030、BIG5等所有编码格式) 脚本的使用方法 创建一个convert_to_utf8的python文件,将代码复制保存。 在终端输入以下命令,即可实现自动检测原文件的编码格式,并生成对应的新文件: python convert_to_utf8.py 原文件.txt 新文件.txt 当然,也可以指定原文件的编码格式:
[转]ASCII,Unicode,UTF-8,GB2312编码之间的关系
[转]ASCII,Unicode,UTF-8,GB2312编码之间的关系 字符编码:ASCII,Unicode,UTF-8,GB2312 从文件编码的方式来看,文件可分为ASCII码文件和二进制码文件两种。 ASCII文件也称为文本文件,这种文件在磁盘中存放时每个字符对应一个字节,用于存放对应的ASCII码。例如,数5678的存储形式为:ASC码: 00110101 001101
使用request.setCharacterEncoding(gb2312)解决中文乱码的注意事项
前几天发现使用request.getPragrmber()方法获取中文参数出现乱码,后发现没有添加request.setCharacterEncoding("gb2312")语句,奇怪的是加入该语句后获取的参数仍然是乱码。经过本人数次实验得出request.setCharacterEncoding("gb2312")必须放在页面的头部,可以放在<jsp:useBean class="classNa
Ubuntu, Eclipse添加 GBK,GB2312
http://yyys8517750.iteye.com/blog/1150552 <1>首先Windows->Preferences, 然后选择General下面的Workspace. Text file encoding选择Other GBK, 如果没有GBK的选项, 没关系, 直接输入GBK三个字母, Apply, GBK编码的中文, 已经不是乱码了。 Fedoral 下
utf8转gb2312精简版
var strGB="啊阿埃挨哎唉哀皑癌蔼矮艾碍爱隘鞍氨安俺按暗岸胺案肮昂盎凹敖熬翱袄傲奥懊澳芭捌扒叭吧笆八疤巴拔跋靶把耙坝霸罢爸白柏百摆佰败拜稗斑班搬扳般颁板版扮拌伴瓣半办绊邦帮梆榜膀绑棒磅蚌镑傍谤苞胞包褒剥薄雹保堡饱宝抱报暴豹鲍爆杯碑悲卑北辈背贝钡倍狈备惫焙被奔苯本笨崩绷甭泵蹦迸逼鼻比鄙笔彼碧蓖蔽毕毙毖币庇痹闭敝弊必辟壁臂避陛鞭边编贬扁便变卞辨辩辫遍标彪膘表鳖憋别瘪彬斌濒滨宾摈兵冰柄丙秉饼炳病
js的编码成gb2312的编码函数(URLEncode)
擦,以前还没觉得,今天才发现原来在传参数取参数的时候asp.net内部会帮我们给数据编码!而且很无耻的是不能取消不让它自动编码解码. 比如search.aspx?key=中国,在传递过程中会自动先用UTF-8编码,然后在取的时候Request.QueryString["key"]按UTF-8解码. 但是如果我们传递之前用gb2312进行了编码了,他再用utf-8编码一次,再解码出来就乱码了.
[日常]GB2312 GBK GB18030的区别和演进过程
因为经常被乱码问题搞乱 , 中文的编码GB系列就有好几个 , 看看这三的区别 , 转自知乎 1 GB2312-80 GB 2312 或 GB 2312-80 是中国国家标准简体中文字符集,全称《信息交换用汉字编码字符集·基本集》,又称 GB 0,由中国国家标准总局发布,1981 年 5 月 1 日实施。GB 2312 编码通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际
编码方式gbk、gb2312、utf8的区别
gbk一般用于繁体中文,是国家标准gb2312基础上扩容后兼容gb2312的标准。文字编码(中英文)用双字节编码,是国家编码,通用性比utf8差,但utf8占用的数据库比gbk大 gb2312一般用于简体中文 utf8----是全球通用,用于解决国际上字符的一种多字节编码,英文使用8位(一个字节),中文使用28位(3个字节)。现在一般都用utf8编码。允许含BOM,但一般不包含BOM。 gb
GB2312和 UTF8的互相转换函数
//将GB2312转化为UTF8string UpdateModule::GB2132ToUTF8(string strSrc){string result;WCHAR *wstrSrc = NULL;char *szRes = NULL;int i;// GB2312转换成Unicodei = MultiByteToWideChar(CP_ACP, 0, strSrc.c_s
Objective-c NSString 转utf-8和gb2312
转载自:http://www.cocoachina.com/bbs/read.php?tid=62897 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #pragma mark - #pragma mark Encode Chinese to ISO8859-1 in UR
nginx支持GB2312和UTF-8编码
nginx同时支持GB2312和UTF-8,将“UTF-8”改为“ISO-88509-1” server { listen 80; server_name localhost; charset ISO-88509-1; }
VB超级模块函数VB读写记事本-防止乱码支持UTF-8和GB2312编码
Private Sub Command1_Click() Writein “C:\Users\Administrator\Desktop\1.txt”, “文本文内容” End Sub Private Sub Form_Load() Text1 = ReadANSI(“C:\Users\Administrator\Desktop\1.txt”) Text2 = ReadUTF8(“C:\User
常用汉字的GB2312 编码
比如“啊”字的编码是1601 “领航软件”是 3376 2629 4077 2894 区位 行 0 1 2 3 4 5 6 7 8 9 1 0 、 。 · ˉ ˇ ¨ 〃 々 1 1 — ~ ‖ … ‘ ’
![把UTF-8编码转换为GB2312编码[转]](http://blog.joycode.com/images/OutliningIndicators/None.gif)
把UTF-8编码转换为GB2312编码[转]
把UTF-8编码转换为GB2312编码[转] 如果只有某个页的编码需要修改,ASP.net 中则可以简单的使用下面代码: Encoding gb2312 = Encoding.GetEncoding("gb2312");Response.ContentEncoding = gb2312; 在非ASP.net 应用中,可能你读到的数据是UTF-8编码,但是你要转换为GB2312编码
Mono环境下不支持Encoding.GetEncoding(GB2312)的解决方法
转载自:http://www.cnblogs.com/muse/articles/1756821.html mono-locale-extras 可以先写一句测试代码: EncodingInfo[] enc = Encoding.GetEncodings(); 在这行上设置一个断点,可以浏览到所有可用的编码名称/CodePage。这时看到936——也就是GB231
vim 文本 编码 gb2312 转换为 utf8 格式 回车与换行
关于回车与换行 /n //也是一种换行特殊字符 很久以前,老式的电传打字机使用两个字符来另起新行。一个字符把滑动架移回首位 (称为回车,<CR>,ASCII码为0D),另一个字符把纸上移一行 (称为换行, <LF>,ASCII码为0A)。当计算机问世以后,存储器曾经非常昂贵。有些人就认定没必要用两个字符来表示行尾。UNIX 开发者决定他们可以用 一个字符来表示行尾,Linux沿袭U
GB2312的编码规则
2009-07-28 GB2312标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时,GB2312收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄罗斯语西里尔字母在内的682个全形字符。 GB2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖99.75%的使用频率。GB2312中对所收