gb18030专题

字符集、字符编码、国际化、本地化简要总结(UNICODE/UTF/ASCII/GB2312/GBK/GB18030)
PS:要转载请注明出处,本人版权所有。 PS: 这个只是基于《我自己》的理解, 如果和你的原则及想法相冲突,请谅解,勿喷。 环境说明 普通的linux 和 普通的windows。 VS2015 和 GCC 7.0 前言 曾记得,我在(https://blog.csdn.net/u011728480/article/details/100277582 《数与计算机 (编码、原码
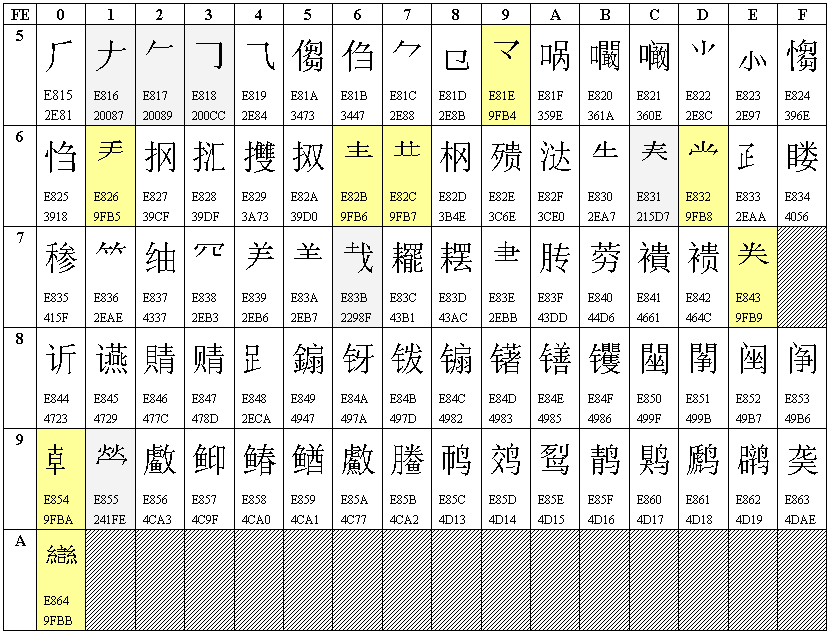
Unicode、GB2312、GBK和GB18030中的汉字
Unicode、GB2312、GBK和GB18030中的汉字 GB18030有两个版本:GB18030-2000和GB18030-2005。GB18030-2000是GBK的取代版本,它的主要特点是在GBK基础上增加了CJK统一汉字扩充A的汉字。GB18030-2005的主要特点是在GB18030-2000基础上增加了CJK统一汉字扩充B的汉字。本文数一数GB18030中的汉字,也顺便看看其它标

txt文本转编码格式(支持utf-8、GBK、GB2312、GB18030、BIG5等所有编码格式)
txt文本转编码格式(支持utf-8、GBK、GB2312、GB18030、BIG5等所有编码格式) 脚本的使用方法 创建一个convert_to_utf8的python文件,将代码复制保存。 在终端输入以下命令,即可实现自动检测原文件的编码格式,并生成对应的新文件: python convert_to_utf8.py 原文件.txt 新文件.txt 当然,也可以指定原文件的编码格式:
![[日常]GB2312 GBK GB18030的区别和演进过程](/front/images/it_default.gif)
[日常]GB2312 GBK GB18030的区别和演进过程
因为经常被乱码问题搞乱 , 中文的编码GB系列就有好几个 , 看看这三的区别 , 转自知乎 1 GB2312-80 GB 2312 或 GB 2312-80 是中国国家标准简体中文字符集,全称《信息交换用汉字编码字符集·基本集》,又称 GB 0,由中国国家标准总局发布,1981 年 5 月 1 日实施。GB 2312 编码通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际

恼人的“龙天“(䶮)--谈谈从GBK转到GB18030的特殊情况
背景 最近在做一个去O迁移适配,刚好也有友商在一起做,两边测试方式不一样。友商先遇到了一个问题,就是在ORACLE中某个的2字节GBK字符到迁移到友商的库中变成了4字节,刚好那个字段在这个字是2字节的时候,已经存满了,转换成4字节后就会超长,死活都导不进去,经分析,是因为友商建库时选择了GB18030字符集,可是为什么2字节的GBK字符到了GB18030会变成4字节?而我在MogDB中建GBK的
恼人的“龙天“(䶮)--谈谈从GBK转到GB18030的特殊情况
背景 最近在做一个去O迁移适配,刚好也有友商在一起做,两边测试方式不一样。友商先遇到了一个问题,就是在ORACLE中某个的2字节GBK字符到迁移到友商的库中变成了4字节,刚好那个字段在这个字是2字节的时候,已经存满了,转换成4字节后就会超长,死活都导不进去,经分析,是因为友商建库时选择了GB18030字符集,可是为什么2字节的GBK字符到了GB18030会变成4字节?而我在MogDB中建GBK的

字符集:ASCII、GB2312、GBK、GB18030、Unicode
文章目录 1 字符集、代码点、编码的概念2 字符集发展的脉络2.1 最早是ASCII2.2 各个国家后续推出的编码表2.3 ANSI到底是什么编码 3 ASCII3.1 ASCII字符集简介及其编码的字符3.2 ASCII字符集的代码点3.3 ASCII字符集的编码方式3.4 扩充的ASCII编码 4 GB23124.1 GB2312字符集简介及其编码的字符4.2 GB2312字符集的代码点
GB2312、GBK、GB18030 、UTF-8、Unicode、ASCII这几种字符集的主要区别是什么?
很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物。他们看到8个开关状态是好的,于是他们把这称为”字节“。再后来,他们又做了一些可以处理这些字节的机器,机器开动了,可以用字节来组合出很多状态,状态开始变来变去。他们看到这样是好的,于是它们就这机器称为”计算机“。开始计算机只在美国用。八位的字节一共可以组合出256(2的8次方)种不同的状态。 他们把其中的编
Unicode、GB2312、GBK和GB18030中的汉字
Unicode、GB2312、GBK和GB18030中的汉字 GB18030有两个版本:GB18030-2000和GB18030-2005。GB18030-2000是GBK的取代版本,它的主要特点是在GBK基础上增加了CJK统一汉字扩充A的汉字。GB18030-2005的主要特点是在GB18030-2000基础上增加了CJK统一汉字扩充B的汉字。本文数一数GB18030中的汉字,也顺便看看其它标

刨根究底字符编码之——简体汉字编码方案(GB2312、GBK、GB18030、GB13000)以及全角、半角、CJK
一、概述 1. 英文字母再加一些其他标点字符之类的也不会超过256个,用一个字节来表示一个字符就足够了(2^8 = 256)。但其他一些文字不止这么多字符,比如中文中的汉字就多达10多万个,一个字节只能表示256个字符,肯定是不够的,因此只能使用多个字节来表示一个字符。 于是当计算机被引入到中国后,相关部门设计了GB系列编码(“GB”为“国标”的汉语拼音首字母缩写,即“国家标准”之意)。
常见的编码方式,ASCII码、ISO-8859-1、GB2312、GBK、GB18030、UTF-16、UTF-8
1.ASCLL码 ASCLL码共有128个,用一个字节(byte)的低七位表示,0到31是控制字符如换行、回车、删除等,32到126是打印字符,可以通过键盘输入并且能够显示出来。 2.ISO-8859-1 128个字符显然是不够用的,于是ISO组织在ASCII码基础上又制定了一系列标准用来扩展ASCII编码,它们是ISO-8859-1~ISO-8859-15,其中ISO-8859-1涵盖了大
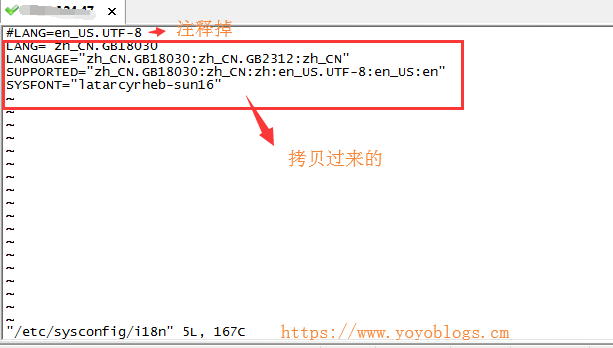
写xml文件到服务器gb18030,服务器上build.xml文件乱码解决(亲测有效)
前提条件:必须root账户登录系统,否则无权限 1. 修改/etc/sysconfig/i18n: 拷贝如下内容到文件中 #LANG="zh_CN.UTF-8" LANG="zh_CN.GB18030" LANGUAGE="zh_CN.GB18030:zh_CN.GB2312:zh_CN" SUPPORTED="zh_CN.GB18030:zh_CN:zh:en_US.UTF-8:en_US:e