funasr专题

AI工具-基于funasr打造离线语音转写工具
【说在前面】 该用例基于魔塔社区中发布的预训练模型和funasr构建。仅支持单声道、16KHz、16位采样wav语音文件的离线转写。过程中没有用到onnx模型不支持多线程的并发,但是可以基于多进程实现并发asr工具构建过程中一定要加载vad,否则推理过程中内存会被撑爆 【预训练模型】 所有预训练模型均可在魔塔社区下载 asr:iic/speech_paraformer-large_a

阿里达摩院:FunASR语音识别
阿里达摩院:FunASR语音识别 github: https://github.com/modelscope/FunASR/ 1 clone 代码到本地,切换到 FunASR/ git clone https://github.com/alibaba/FunASR.git && cd FunASR 2 虚拟环境 conda create -p ./venv python=3.12co
FunASR自动语音识别的创新平台
1. 什么是自动语音识别(ASR) 自动语音识别(ASR, Automatic Speech Recognition)是一种将语音信号转换为文本的技术。随着语音助手、智能家居、翻译系统等应用的兴起,ASR技术的重要性日益凸显。传统的ASR系统依赖于复杂的统计模型和大量的语音数据,但随着深度学习技术的普及,现代ASR系统已能更高效、准确地识别语音。 2. FunASR简介 FunASR是一个先

Windows 11部署FunASR离线语音识别系统
Windows 11部署FunASR离线语音识别系统 官网连接 https://github.com/alibaba-damo-academy/FunASR/blob/main/runtime/docs/SDK_advanced_guide_online_zh.md 1-安装Docker 运行Docker Desktop Installer.exe安装Docker 2-Windows添

FunSound: 基于FunASR-onnx 的高精度离线转写
基于funasr的高精度离线语音转写网页 www.funsound.cn 精度和速度表现不错,提供给大家免费测试
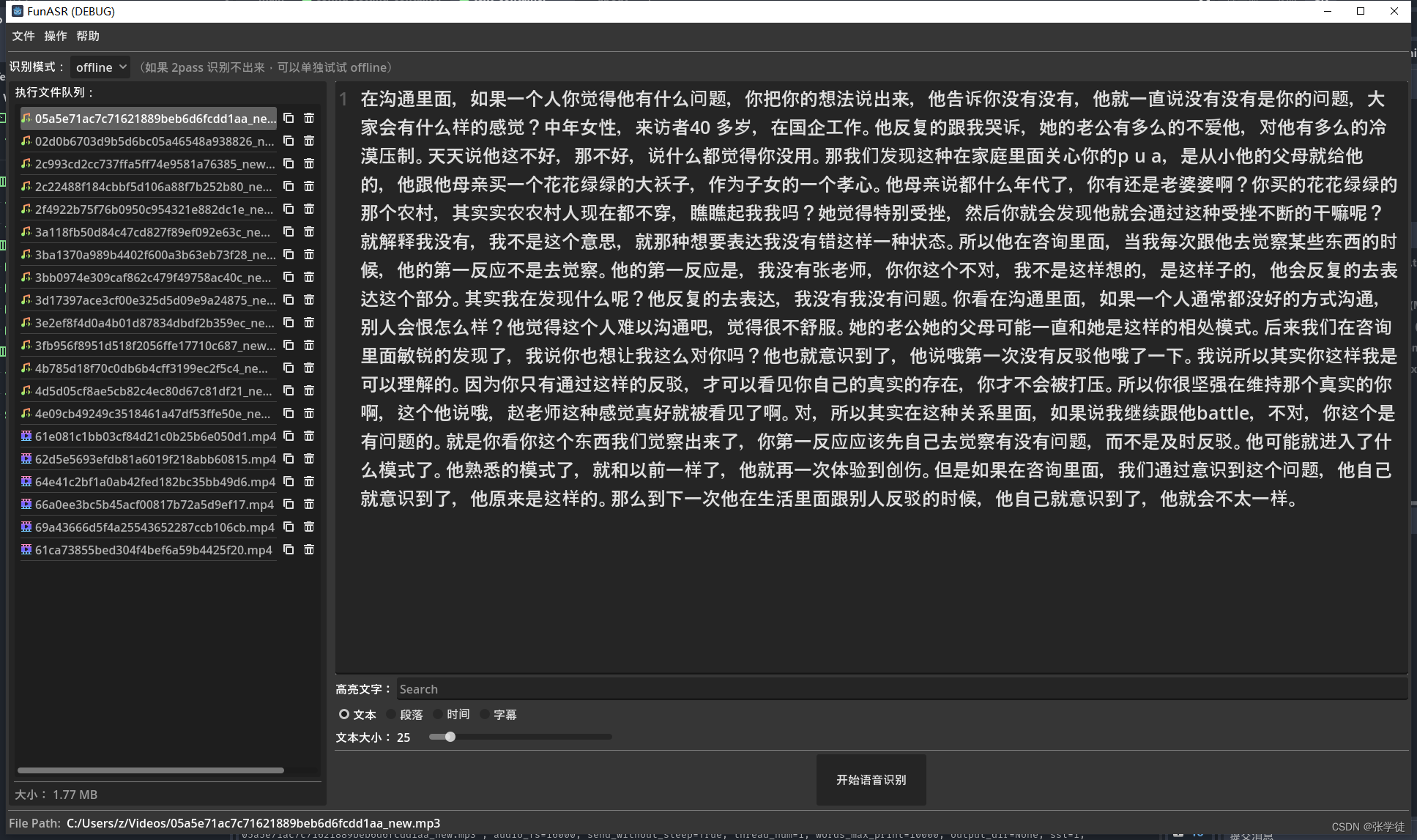
【语音识别】搭建本地的语音转文字系统:FunASR(离线不联网即可使用)
参考自: 参考配置:FunASR/runtime/docs/SDK_advanced_guide_offline_zh.md at main · alibaba-damo-academy/FunASR (github.com)参考配置:FunASR/runtime/quick_start_zh.md at 861147c7308b91068ffa02724fdf74ee623a909e · al
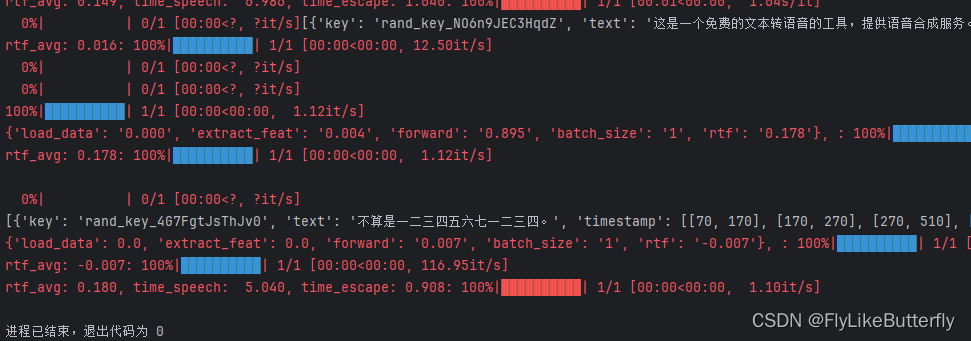
使用FunASR处理语音识别
FunASR是阿里的一个语音识别工具,比SpeechRecognition功能多安装也很简单; 官方介绍:FunASR是一个基础语音识别工具包,提供多种功能,包括语音识别(ASR)、语音端点检测(VAD)、标点恢复、语言模型、说话人验证、说话人分离和多人对话语音识别等。FunASR提供了便捷的脚本和教程,支持预训练好的模型的推理与微调。 网址:FunASR/README_zh.md at ma
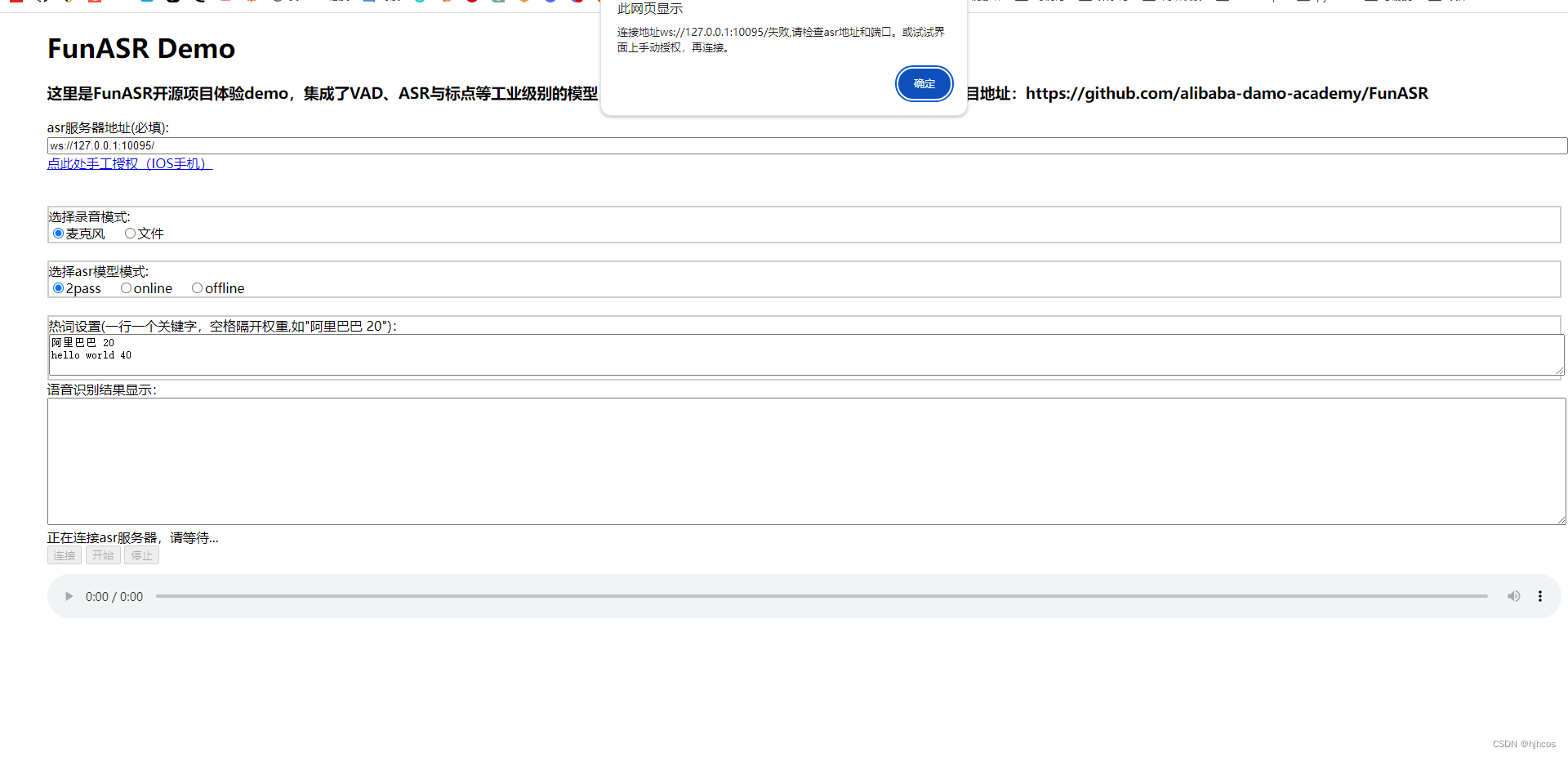
【语音识别】在Win11使用Docker部署FunASR服务器
文章目录 在 Win11 使用 Docker 部署 FunASR 服务器镜像启动服务端启动监控服务端日志下载测试案例使用测试案例打开基于 HTML 的案例连接ASR服务端 关闭FunASR服务 在 Win11 使用 Docker 部署 FunASR 服务器 该文章因官网文档不详细故写的经验论 官网文章:https://github.com/alibaba-damo-academ
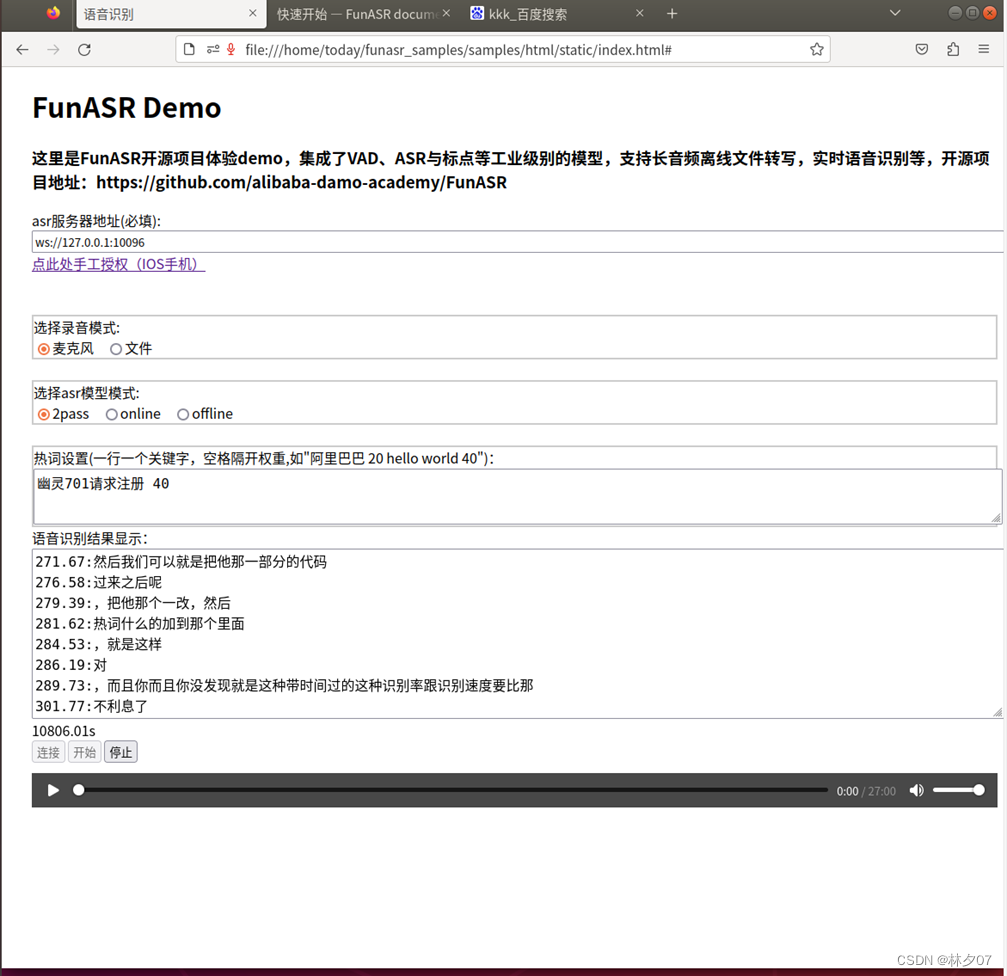
轻松搞定!在 Windows 10 上安装 FunASR 并运行离线时间戳模型
目录 1、FunASR介绍2、系统环境安装2.1 环境要求2.2 环境设置2.3 软件环境安装2.3.1 Ubuntu安装2.3.2 WSL安装2.3.3 docker部署 3、服务部署3.1 docker镜像下载与启动3.2 配置文件调整3.3 启动funasr服务 4 客户端连接4.1 html连接4.2 python连接4.2.1 客户端文件修改4.4.3 客户端运行
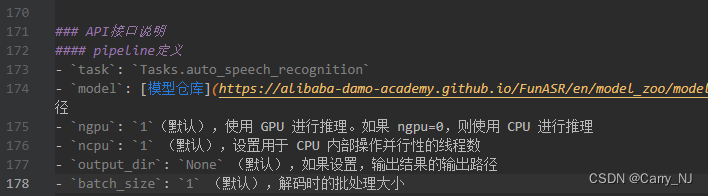
记一次关于FunASR的效率测试
FunASR github modelscope 部分代码 其中 pipeline 有 device 参数可以选择使用GPU或者CPU,这个参数比较好找。这里要说的是另一个参数:ncpu from modelscope.pipelines import pipelinefrom modelscope.utils.constant import Tasksparam_dict = dict(
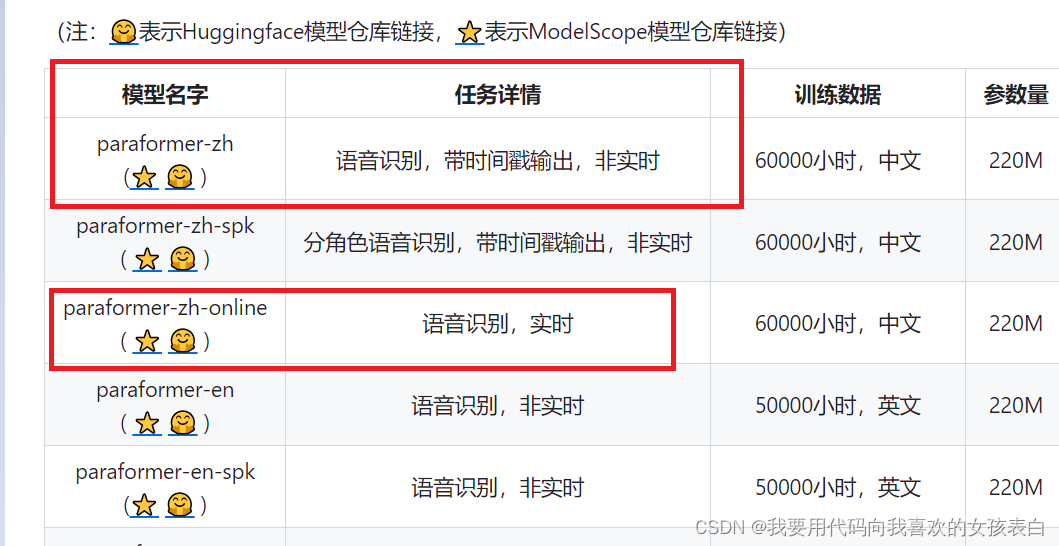
中文语音标注工具FunASR(语音识别)
全称 A Fundamental End-to-End Speech Recognition Toolkit(一个语音识别工具) 可能大家用过whisper(openAi),它【标注英语的确很完美】,【但中文会出现标注错误】或搞了个没说的词替换上去,所以要人工核对,麻烦。 FunASR作用:能【准确】识别语音,并转成【文字、标出声调】 他的原理,就不讲了,俺是搞大数据的,python这东
关于python环境下的语音转文本,whisper或funASR
因为前阵子,有需求要将语音转为文本再进行下一步操作。感觉这个技术也不算是什么新需求,但是一搜,都是大厂的api,或者是什么什么软件,由于想要免费的,同时也要嵌入在代码中,所以这些都不能用。、 一筹莫展的时候,突然搜到whisper,这是个openai开源的工具,主打就是语音转文本。试了一下,还是不错的,虽然搜到的大多数介绍都是关于怎么直接命令行使用的,但是也有少量