forespider专题

使用前嗅ForeSpider在同一个网站中从另一页面采集数据
第一步:新建任务 ①点击左上角“加号”新建任务,如图1: 【图1】 ②在弹窗里填写采集地址,任务名称,如图2: 【图2】 ③点击下一步,选择进行数据抽取还是链接抽取,本次采集企业最新动态链接列表,所以点击抽取链接,选择链接列表,如图3: 【图3】 ④完成之后,在模板抽取配置下生成两个模板,默认模板:01和链接列表:02。模板1中的“链接列表”链接抽取已与模板2关联,如图4

使用前嗅ForeSpider采集网页链接/源码/时间/重定向地址等
第一步:新建任务 ①点击左上角“加号”新建任务,如图1: 【图1】 ②弹窗里填写采集地址,任务名称,如图2: 【图2】 ③ 点击下一步,勾选抽取链接,选择网页内所有链接,如图3: 【图3】 ④完成后模板抽取配置列表有一个模板,默认模板。默认模板下自动生成一个链接抽取,名称为网页全部链接,如4: 【图4】 第二步:创建新的模板,并新建数据抽取 ①模板配置,点击“新

使用前嗅ForeSpider通过搜索框检索关键词采集数据
第一步:新建任务 ①点击左上角“加号”新建任务,如图1: 【图1】 ②在弹窗里填写采集地址、任务名称,由于此次需要配置关键词,所以在新建任务时,需要勾选一下“关键词采集”如图2: 【图2】 ③点击下一步,选择进行数据抽取还是链接抽取,本次采集需要采集列表页中正文的所有文本信息,所以此处需要勾选“抽取链接”-“普通翻页”,如图3: 【图3】 第二步:配置关键词 ①由于在创

前嗅ForeSpider脚本教程:标准对象(二)
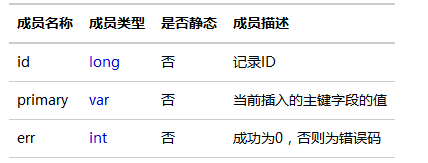
今天,小编主要为大家介绍一下:前嗅ForeSpider脚本中的标准对象:采集文档类grabDoc,采集记录集类result,JavaScript操作类jScript、KeyForm操作类KeyForm,html标签属性类domAttr以及keySearch操作类keySearch。具体内容如下: 一.采集文档类grabDoc grabDoc 类为ForeSpider网页(或文件)的采集文
前嗅ForeSpider脚本教程:基础对象(三)
今天,小编主要为大家介绍一下:前嗅ForeSpider脚本中的基础对象,主要内容包括:记录类record,记录集类records,数据表类dataTable,dataInRet类。具体内容如下: 一.记录类record record 类为数据记录类。 1.类成员: 2.成员方法: 二.记录集类records records 类为数据记录集类,

前嗅ForeSpider脚本教程:基础对象(二)
今天,小编给大家介绍一下:前嗅ForeSpider脚本中的基础对象,主要内容有:数组类array、键值对类hash、文件类file、字段操作类field。具体内容如下: 一.数组类array array 类为数组类。 1.类成员 2.成员方法 3.脚本应用 如果在导航栏的采集预览中找到多个栏目,我们需要的个别栏目在爬虫的链接过滤中很难得到的时候。那

前嗅ForeSpider脚本教程:基础对象(一)
今天,小编为大家介绍一下:前嗅ForeSpider脚本中的基础对象。主要内容有:基础对象var、字符串string、数字类number、时间类time。具体内容如下: 一.基础对象var var 类为基本类,任何一个变量或常量都是var类,任何其他的对象类都派生域var类。 1.类成员 2.成员方法 二.字符串string string 类为

前嗅ForeSpider脚本教程:运算符与运算顺序
今天小编为大家介绍的是:前嗅ForeSpider脚本中的运算符和运算顺序,具体内容有:脚本支持的运算符、运算顺序、运算级别以及默认类型转换顺序。 一.ForeSpider脚本支持的运算符 1.一般运算符: 2.比较运算符: 3.赋值运算: 4.自增自减运算: 5.移位运算: 二.运算顺序与运算级别 ForeSpider脚

前嗅ForeSpider脚本教程:基本语句
今天,小编主要为大家介绍一下:前嗅ForeSpider脚本中的基本语句。内容包括:顺序语句,条件语句,循环语句,开关语句和返回语句。 1.顺序语句 ForeSpider脚本语法规则类似JavaScript、C++等标准语言,每一条语句用分号隔开,例如: x = 1; y =2; z=x+y; 或者,一行一条语句,例如: x=1 y=2 z = x+y 多个变量声明之间可
前嗅ForeSpider脚本教程:脚本概述
本教程主要对前嗅ForeSpider脚本做了详细的介绍。主要内容包括:脚本结构,脚本与可视化配置的关系,各节点脚本之间的关系,以及脚本编辑区。具体内容如下: 一.ForeSpider脚本结构 ForeSpider脚本是前嗅自主研发的爬虫脚本语言,风格类似于JavaScript。ForeSpider脚本语言属于轻量级的脚本语言,为支持高级数据采集的规则补充,它支持对象操作,函数,数组
前嗅ForeSpider脚本教程:变量申明及引用
今天,小编为大家介绍前嗅ForeSpider脚本中的语法规则——变量申明及引用。在此之前先为大家介绍一下,语法规则中的注释和标准常量,具体内容如下: 一 .注释 ForeSpider脚本的注释类似于C++及JavaScript。通常有两种方式:单行注释和块注释。 1.单行注释 //这是行注释 2.块注释 /*这是块注释这是块注释这是块注释这是块注释*/ 二.标准常量 NULL
前嗅ForeSpider教程:运行设置(三)
今天,小编为大家详细介绍一下:前嗅ForeSpider运行设置中的任务定时,预警设置,过滤设置,这三大模块。具体内容如下: 一,任务定时 【任务定时】 用户可以通过任务定时,进行自动启动/停止采集。也可以选择间隔某个时间段后启动/停止采集。 二,预警设置 【预警设置】 1. 网络异常 可以设置网络异常连续多少次,则进行预警提醒。 2. 反爬识别
前嗅ForeSpider教程:运行设置(二)
今天,小编为大家详细介绍一下:前嗅ForeSpider运行设置中的网络超时,HTTP设置,加载设置,任务模式,这四大模块。具体内容如下: 一,网络超时 【网络超时】 1. 接收超时 当对方服务器繁忙时,可将接收超时的时间调大,否则软件在超时后将不再接收该链接地址的数据。 2. 发送超时 当采集的数据量过大时,可以将发送超时的时间调大。 3. 重试次数 网
前嗅forespider---关键词采集【检索结果】
如何采集关键词检索结果,今天前嗅大数据就以古诗文网为例为大家演示,话不多说一起看看吧。 一. 网站内容 1. 网站截图说明 本教程通过“古诗文网”官网来采集所需“关键词”的正文数据,本教程以关键词“鹅鹅鹅”为例,故链接入口为:https://so.gushiwen.org/search.aspx?value=%E9%B9%85%E9%B9%85%E9%B9%85 Step1:在官网输