flashattention2专题
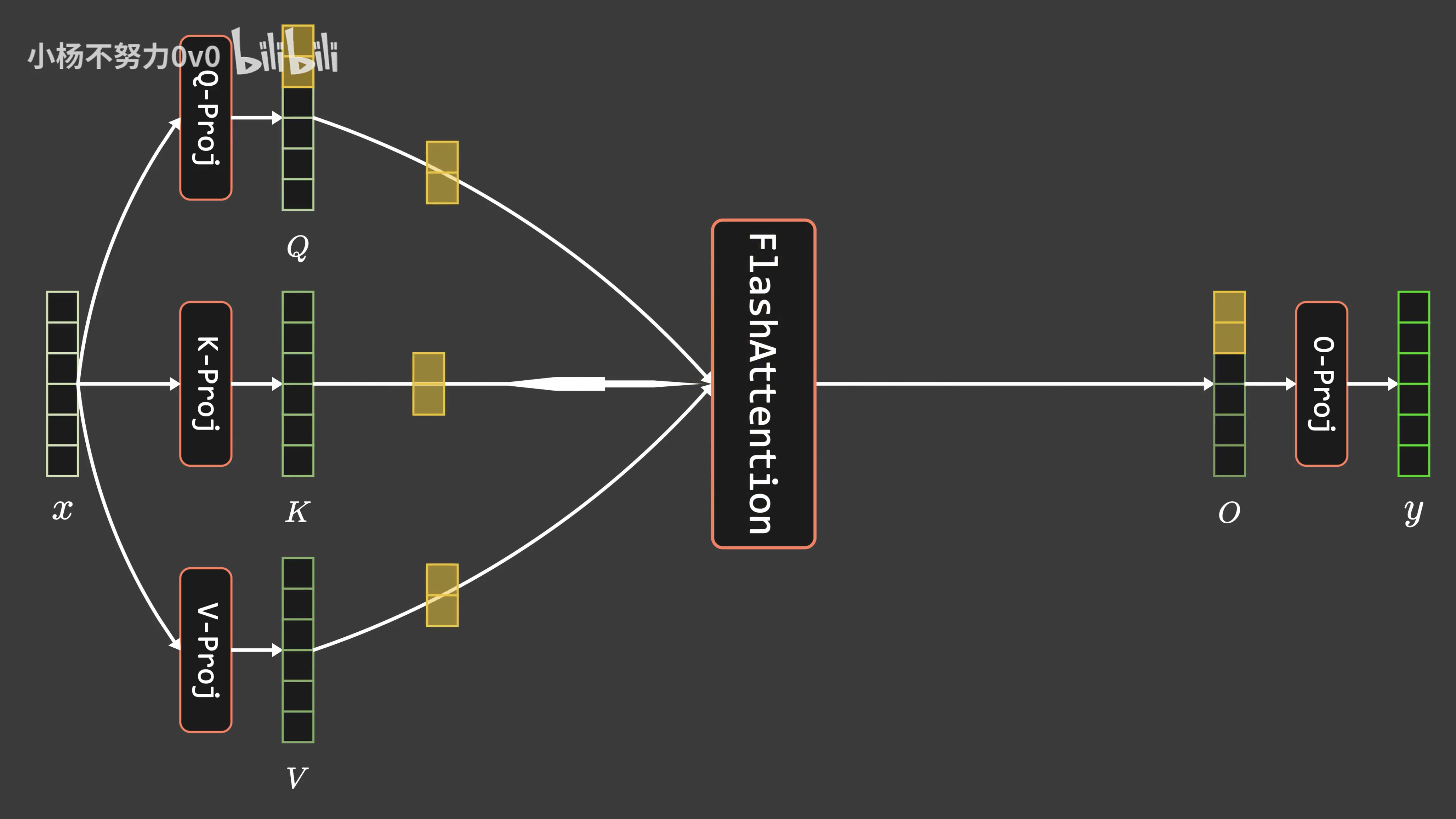
通透理解FlashAttention与FlashAttention2:全面降低显存读写、加快计算速度
前言 成就本文有两个因素 第一个因素是,我带长沙的LLM项目团队做论文审稿GPT这个项目时,遇到了不少工程方面的问题(LLM方面的项目做多了,你会逐步发现,现在模型没啥秘密 技术架构/方向选型也不是秘密,最终都是各种工程细节的不断优化),比如数据的问题,再比如大模型本身的上下文长度的问题 前者已经得到了解决,详见此文《学术论文GPT的源码解读与微调:从ChatPaper到七月论文审稿GPT第1
通透理解FlashAttention与FlashAttention2:让大模型上下文长度突破32K的技术之一
前言 成就本文有两个因素 第一个因素是,我带长沙的LLM项目团队做论文审稿GPT这个项目时,遇到了不少工程方面的问题(LLM方面的项目做多了,你会逐步发现,现在模型没啥秘密 技术架构/方向选型也不是秘密,最终都是各种工程细节的不断优化),比如数据的问题,再比如大模型本身的上下文长度的问题 前者已经得到了解决,详见此文《学术论文GPT的源码解读与微调:从chatpaper、gpt_academi