flashattention专题

FlashAttention之我见
Attention机制可以算是Transformer的灵魂。正因为有了attention,模型的效果才能大幅提升。但同样是因为attention,导致transformer很难处理超长上下文,因为attention占用显存的大小与上下文长度的平方成正比,会导致上下文很长时显存爆炸。FlashAttention正是为了解决显存爆炸而设计的,它不光解决了显存爆炸的问题,同时也加速了attention的
FlashAttention-2 论文阅读笔记
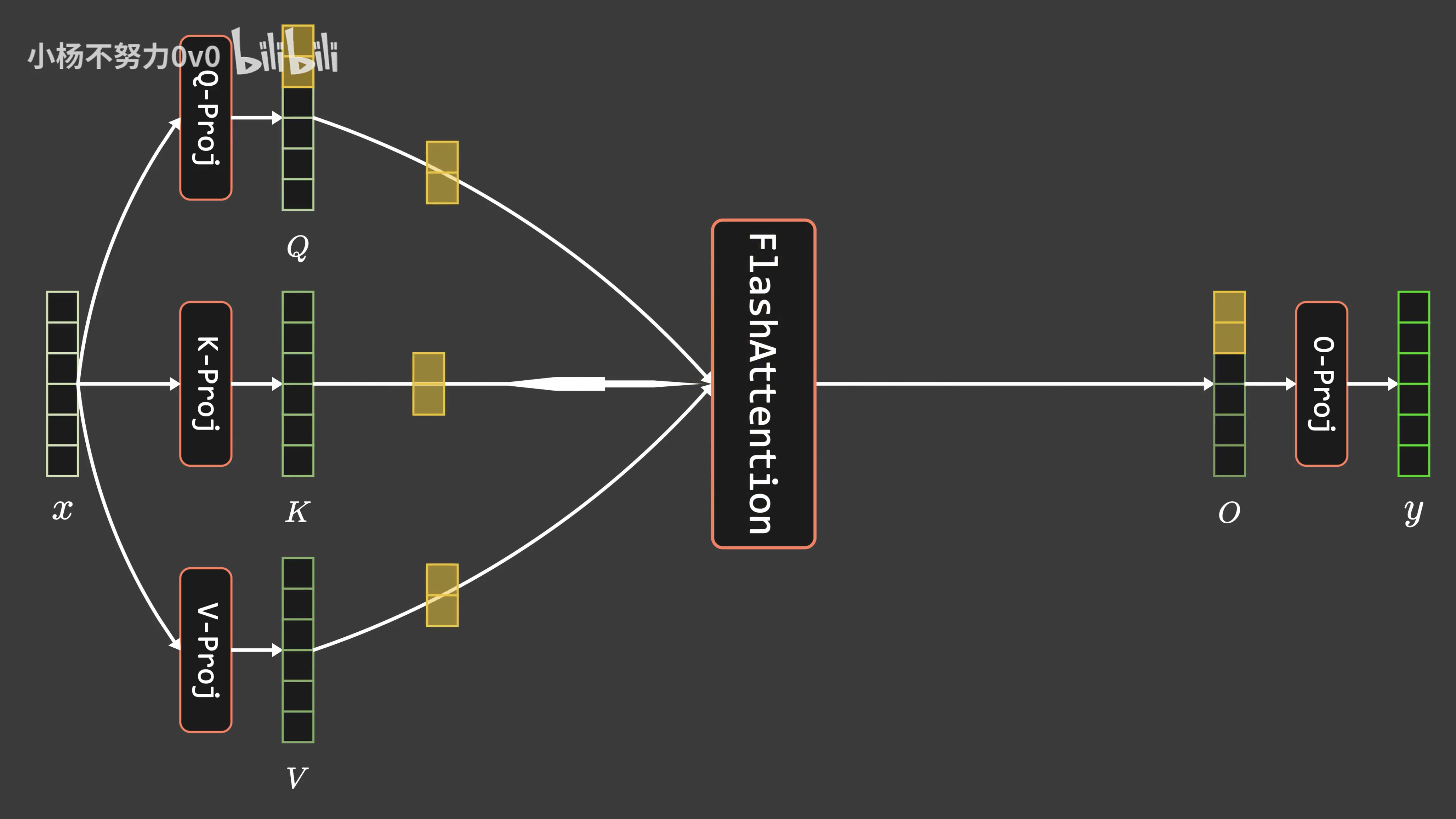
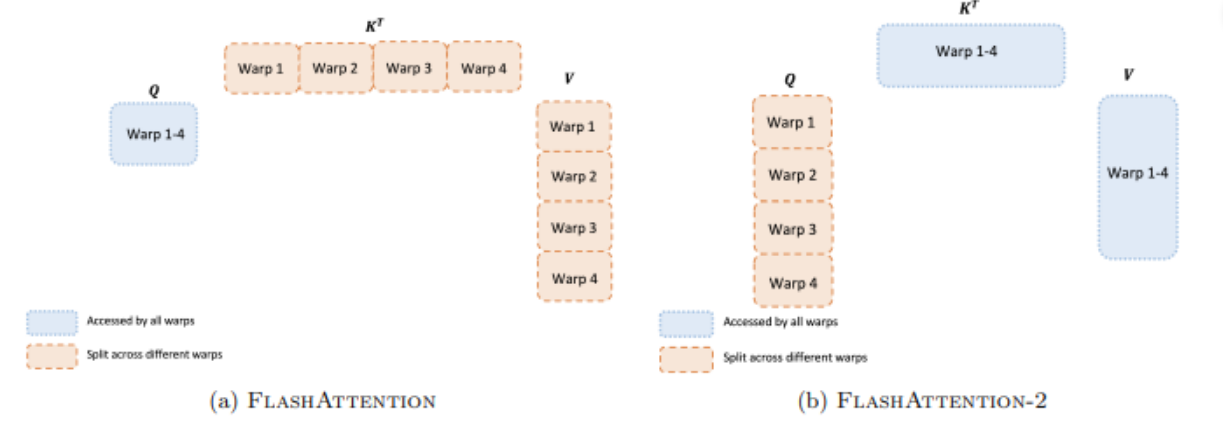
FlashAttention-2是对原始FlashAttention算法的一系列改进,旨在优化在GPU上的计算性能。本节详细讨论了FlashAttention-2的算法、并行性以及工作分区策略。 算法 FlashAttention-2的关键优化点在于减少非矩阵乘法(matmul)的浮点运算,以充分利用GPU上的专用计算单元(如Nvidia GPU上的Tensor Cores),这些单元在处理m
Pytorch官方FlashAttention速度测试
在Pytorch的2.2版本更新文档中,官方重点强调了通过实现FlashAtteneion-v2实现了对scaled_dot_product_attention约2X左右的加速。 今天抽空亲自试了下,看看加速效果是否如官方所说。测试前需要将Pytorch的版本更新到2.2及以上,下面是测试代码,一个是原始手写的Self-Attention的实现,一个是使用Pytorch官方的scaled_dot
通透理解FlashAttention与FlashAttention2:全面降低显存读写、加快计算速度
前言 成就本文有两个因素 第一个因素是,我带长沙的LLM项目团队做论文审稿GPT这个项目时,遇到了不少工程方面的问题(LLM方面的项目做多了,你会逐步发现,现在模型没啥秘密 技术架构/方向选型也不是秘密,最终都是各种工程细节的不断优化),比如数据的问题,再比如大模型本身的上下文长度的问题 前者已经得到了解决,详见此文《学术论文GPT的源码解读与微调:从ChatPaper到七月论文审稿GPT第1

PyTorch 2.2大更新!集成FlashAttention-2,性能提升2倍
【新智元导读】新的一年,PyTorch也迎来了重大更新,PyTorch 2.2集成了FlashAttention-2和AOTInductor等新特性,计算性能翻倍。 新的一年,PyTorch也迎来了重大更新! 继去年十月份的PyTorch大会发布了2.1版本之后,全世界各地的521位开发者贡献了3628个提交,由此形成了最新的PyTorch 2.2版本。 新的版本集成了Flash
【大模型上下文长度扩展】FlashAttention-2:比1代加速1.29倍、GPU利用率从55%上升到72%
FlashAttention-2 提出背景FlashAttention-2 改进 前向传播和反向传播对比FlashAttention前向传播FlashAttention反向传播FlashAttention-2前向传播FlashAttention-2反向传播FlashAttention-2并行性线程束之间的工作分区 总结FlashAttentionFlashAttention-2
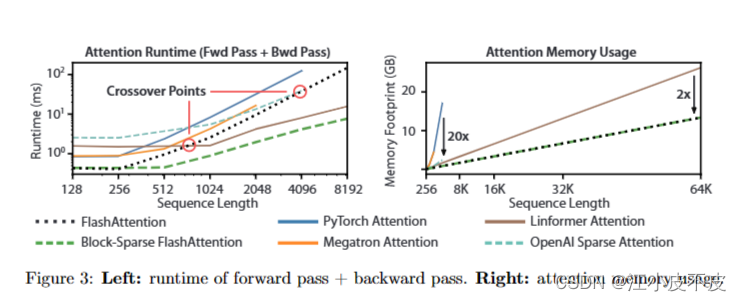
FlashAttention:Fast and Memory-Efficient Exact Attention with IO-Awareness
FlashAttention让语言模型拥有更长的上下文 FlashAttention序:概述:简介:FlashAttention块稀疏 FlashAttention优点:标准注意力算法实现流程: FlashAttentionBlock-Sparse FlashAttention实验使用FlashAttention后更快的模型BERTGPT-2Long-range Arena 具有更长序列的更
通透理解FlashAttention与FlashAttention2:让大模型上下文长度突破32K的技术之一
前言 成就本文有两个因素 第一个因素是,我带长沙的LLM项目团队做论文审稿GPT这个项目时,遇到了不少工程方面的问题(LLM方面的项目做多了,你会逐步发现,现在模型没啥秘密 技术架构/方向选型也不是秘密,最终都是各种工程细节的不断优化),比如数据的问题,再比如大模型本身的上下文长度的问题 前者已经得到了解决,详见此文《学术论文GPT的源码解读与微调:从chatpaper、gpt_academi
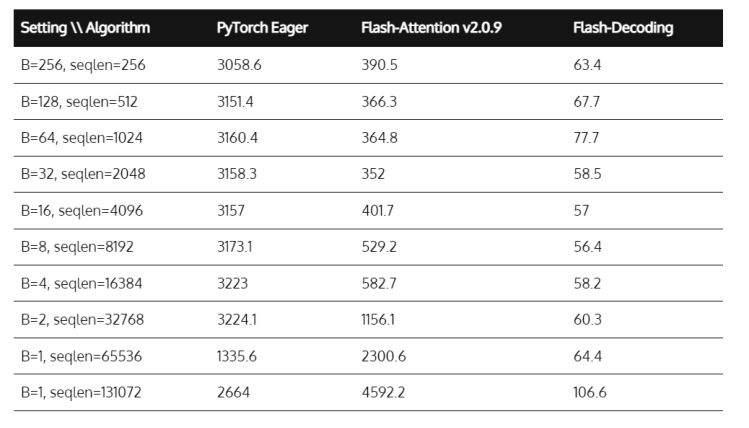
英伟达禁售?FlashAttention助力LLM推理速度提8倍
人工智能领域快速发展,美国拥有强大的AI芯片算力,国内大部分的高端AI芯片都是采购英伟达和AMD的。而为了阻止中国人工智能领域发展,美国频繁采取出口管制措施。10月17日,美国拜登突然宣布,升级芯片出口禁令。英伟达限制细则披露,A/H800、A/H100、L40、L40S以及游戏卡RTX 4090全部禁售!这也倒逼中国企业通过大模型优化提高推理速度,减少对芯片数量的依赖。 我们知道处理小说、法律
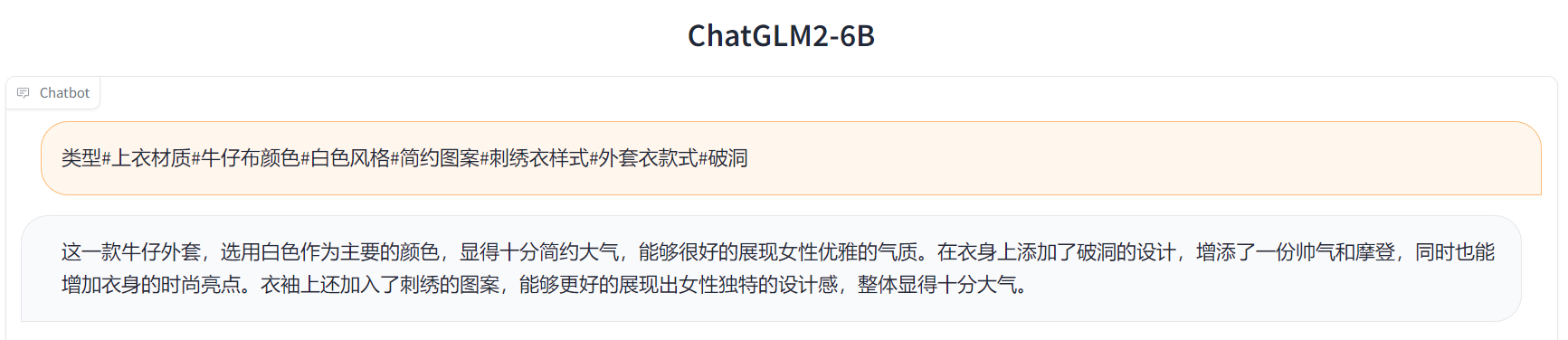
ChatGLM2-6B的通透解析:从FlashAttention、Multi-Query Attention到GLM2的微调、源码解读
目录 前言 第一部分 相比第一代的改进点:FlashAttention与Multi-Query Attention 第二部分 FlashAttention:减少内存访问提升计算速度——更长上下文的关键 2.1 FlashAttention相关的背景知识 2.1.1 Transformer计算复杂度:编辑——Self-Attention层与MLP层 2.1.1.1 Self-Atte