fink专题

自定义fink source
实现思路: (1)继承RichSourceFunction (2)在open方法里重写初始化内容 (3)在run方法里实现具体的数据生成逻辑,例如从数据库中读取、或者程序自动生成,使用context.collect(str),来将数据输出 (4)可以调用cancle来取消数据生成 参考资料: Flink自定义source、自定义sink-阿里云开发者社区
Fink CDC数据同步(六)数据入湖Hudi
数据入湖Hudi Apache Hudi(简称:Hudi)使得您能在hadoop兼容的存储之上存储大量数据,同时它还提供两种原语,使得除了经典的批处理之外,还可以在数据湖上进行流处理。这两种原语分别是: Update/Delete记录:Hudi使用细粒度的文件/记录级别索引来支持Update/Delete记录,同时还提供写操作的事务保证。查询会处理最后一个提交的快照,并基于此输出结果。
Fink CDC数据同步(四)Mysql数据同步到Kafka
依赖项 将下列依赖包放在flink/lib flink-sql-connector-kafka-1.16.2 创建映射表 创建MySQL映射表 CREATE TABLE if not exists mysql_user (id int,name STRING,birth STRING,gender STRING,PRIMARY KEY (`id`) NOT ENFOR
Fink CDC数据同步(五)Kafka数据同步Hive
6、Kafka同步到Hive 6.1 建映射表 通过flink sql client 建Kafka topic的映射表 CREATE TABLE kafka_user_topic(id int,name string,birth string,gender string) WITH ('connector' = 'kafka','topic' = 'flink-cdc
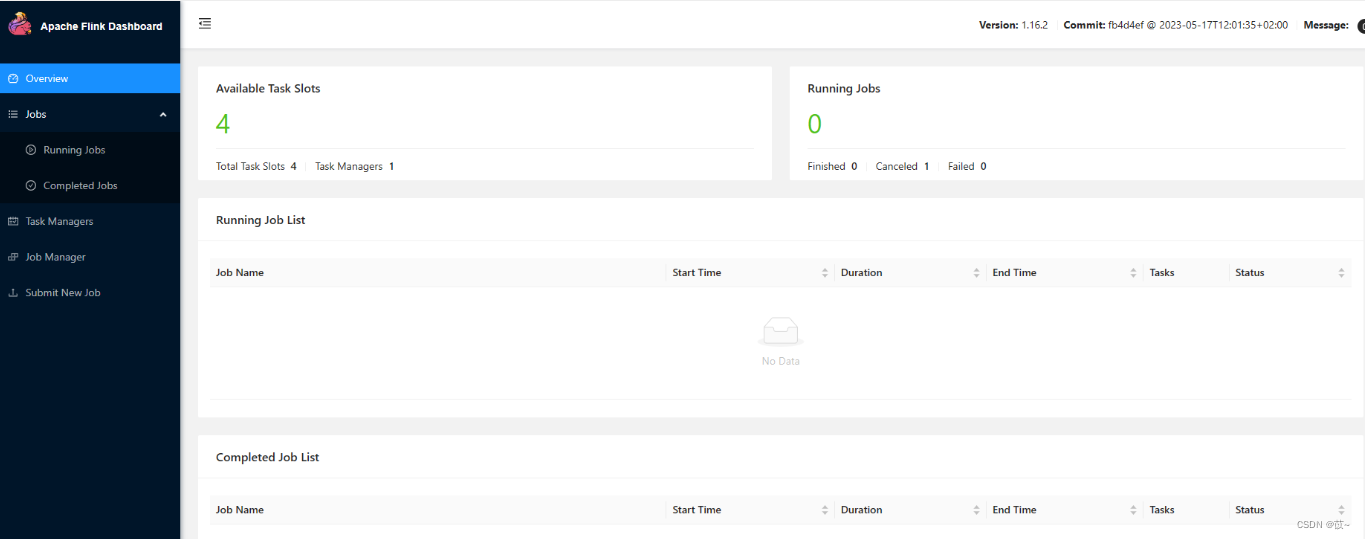
Fink CDC数据同步(一)环境部署
1 背景介绍 Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。 Flink CDC 是 Apache Flink 的一组源连接器,基于数据库日志的 Change Data Caputre 技术,实现了全量和增量的一体化读取能力,并借助 Flink 优秀的管道能力和丰富的
Fink CDC数据同步(三)Flink集成Hive
1 目的 持久化元数据 Flink利用Hive的MetaStore作为持久化的Catalog,我们可通过HiveCatalog将不同会话中的 Flink元数据存储到Hive Metastore 中。 利用 Flink 来读写 Hive 的表 Flink打通了与Hive的集成,如同使用SparkSQL或者Impala操作Hive中的数据一样,我们可以使用Flink直接读写Hive中的表。
Fink Data Sink
Flink Sink 一、Data Sinks 在使用 Flink 进行数据处理时,数据经 Data Source 流入,然后通过系列 Transformations 的转化,最终可以通过 Sink 将计算结果进行输出,Flink Data Sinks 就是用于定义数据流最终的输出位置。Flink 提供了几个较为简单的 Sink API 用于日常的开发,具体如下: 1.1 writeAsTe