filtered专题

scrapy 爬网站 显示 Filtered offsite request to 错误.
爬取zol 网站图片,无法抓取. 在 setting.py 文件中 设置 日志 记录等级 LOG_LEVEL= 'DEBUG' LOG_FILE ='log.txt' 查看日志 发现报 2015-11-07 14:43:43+0800 [meizitu] DEBUG: Filtered offsite request to 'bbs.zol.com.cn': <GET h
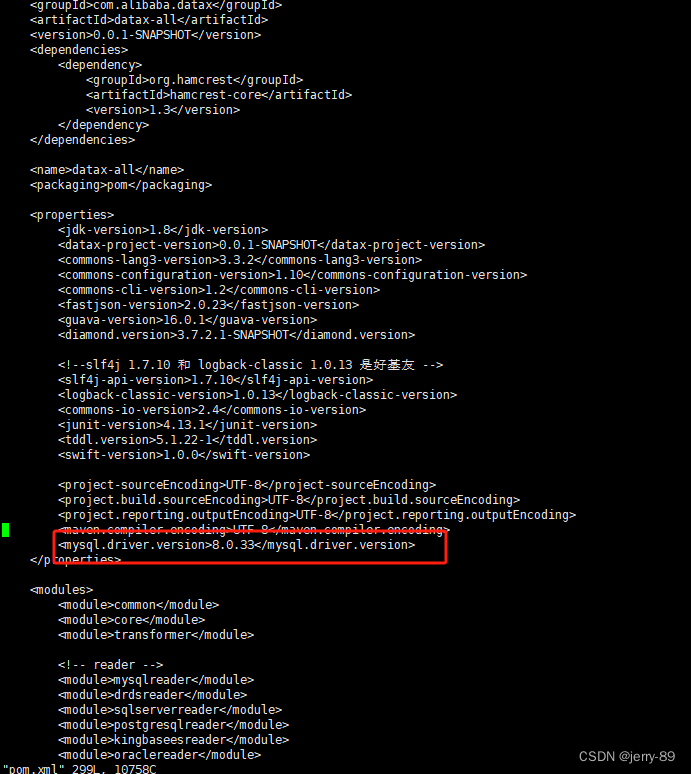
导入失败,报错:“too many filtered rows xxx, “ErrorURL“:“
一、问题: 注:前面能正常写入,突然就报错,导入失败,报错:“too many filtered rows xxx, "ErrorURL":" {"TxnId":769494,"Label":"datax_doris_writer_bf176078-15d7-414f-8923-b0eb5f6d5da1","TwoPhaseCommit":"false","Status":"Fail","

第 0012 题: 敏感词文本文件 filtered_words.txt,里面的内容 和 0011题一样,当用户输入敏感词语,则用 星号 * 替换,
import redef get_filters(path):if path is None:returnfilters = ["北京", "程序员", "公务员", "领导", "牛比", "牛逼", "你娘", "你妈", "love", "sex", "jiangge"]with open(path,encoding="utf-8") as f:line = f.read()# for l
阅读资料 第 0011 题: 敏感词文本文件 filtered_words.txt,
阅读资料 第 0011 题: 敏感词文本文件 filtered_words.txt,里面的内容为以下内容,当用户输入敏感词语时,则打印出 Freedom,否则打印出 Human Rights。 北京 程序员 公务员 领导 牛比 牛逼 你娘 你妈 love sex jiangge def get_filters(path):if path is None:returnfilters = ["北
flink 写入 starrocks 报错 too many filtered rows attachment
把你starrocks中DDL里的varchar(...) 先修改为STRING. 一般是因为字段超出定义的长度.
![运行moveit_rviz报错 Tried to advertise on topic [/move_group/filtered_cloud] with md5sum [060021388200f](https://img-blog.csdnimg.cn/bab2a6a0d200473a9f027c6dc9adb65b.png)
运行moveit_rviz报错 Tried to advertise on topic [/move_group/filtered_cloud] with md5sum [060021388200f
运行moveit_rviz报错 [ERROR] [1656070551.111682083, 1948.582000000]: Tried to advertise on topic [/move_group/filtered_cloud] with md5sum [060021388200f6f0f447d0fcd9c64743] and datatype [sensor_msgs/Image
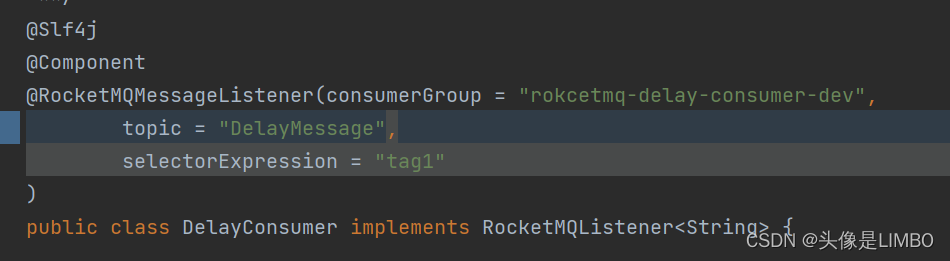
记录一次RocketMQ消息不能正常消费的情况CONSUMED_BUT_FILTERED
RocketMQMessageListener整个注解默认selectorExpression为* 因为配置消费者时 在@RocketMQMessageListener标签内配置了selectorExpression所以在消费消息时会根据selector的内容进行筛选 被筛选掉的消息状态为CONSUMED_BUT_FILTERED 不配置则不会筛选

Explain执行计划字段解释说明---possible_keys、key、key_len、ref、rows、filtered字段说明
1、 possible_keys 显示可能应用在这张表中的索引,一个或多个。 查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用。 2、 key (1)实际使用的索引。如果为NULL,则没有使用索引。 (2)查询中若使用了覆盖索引,则该索引和查询的select字段重叠。 3、 key_len 表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。 key_l