failover专题

Dubbo 的集群容错模式:Failover Cluster
集群容错系列文章: Failover Cluster 失败自动切换 Failfast Cluster 快速失败,抛出异常 Failsafe Cluster 快速失败,不抛出异常 Failback Cluster 失败后定时重试 Forking Cluster 并行调用多个实例,只要一个成功就返回 Broadcast Cluster 广播调用所有实例,有一个报错则抛出异常 Availa

Flume之使用Failover Sink Processor实现sink故障转移
前言 Failover Sink Processor 维护着Sink组中Sinks的优先级表,根据优先级尝试将Event传输给不同的Sink直到Event成功发送。当优先级高的Sink不可用时,会将Event传输给下一优先级Sink,以此来确保每个Event都能被投递。当Sink不可用时,Failover Sink Processor和Load balancing Sink Processo
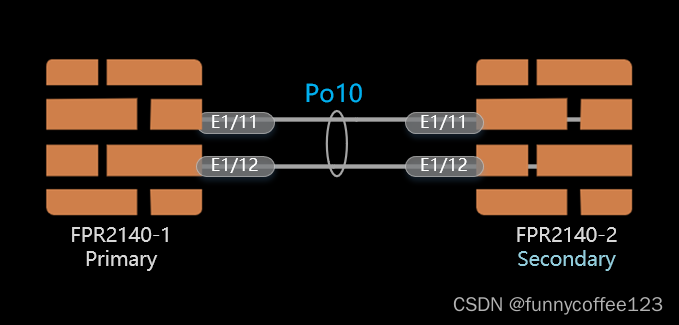
Cisco firepower 2140 run ASA and config failover
1 背景 here we got 2 cisco firepower 2140 hardware appliance we’re planning to run ASA on it. and config failover for Primary Unit and Secondary Unit
oracle11g dataguard完全手册3-failover active dataguard(完)
一般情况下执行failover都是主库已经game over。故障转移将备库转换为主库,但不把原主库(有故障,无法正常工作)切换为备库。当故障转移发生后,你必须重建主库,或者使用闪回数据库功能将主库回退到故障发生前,然后转换其为备库并启用日志应用。 执行failover有几个前提条件如下 1.执行failover的前提 (1)检查归档文件是否连续 查询待转换
Oracle dataguard failover实战
Oracle dataguard failover实战 操作步骤 备库: SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE FINISH FORCE; SQL> ALTER DATABASE COMMIT TO SWITCHOVER TO PRIMARY; SQL> SHUTDOWN IMMEDIATE;

nginx upstream failover 容错机制
1. 摘要 (1) 结论 详细描述了nginx记录失效节点的6种状态(time out、connect refuse、500、502、503、504,后四项5XX需要配置proxy_next_upstream中的状态才可以生效)、失效节点的触发条件和节点的恢复条件、所有节点失效后nginx会进行恢复并进行重新监听。 (2) Nginx 负载均衡方式介绍 Ngin
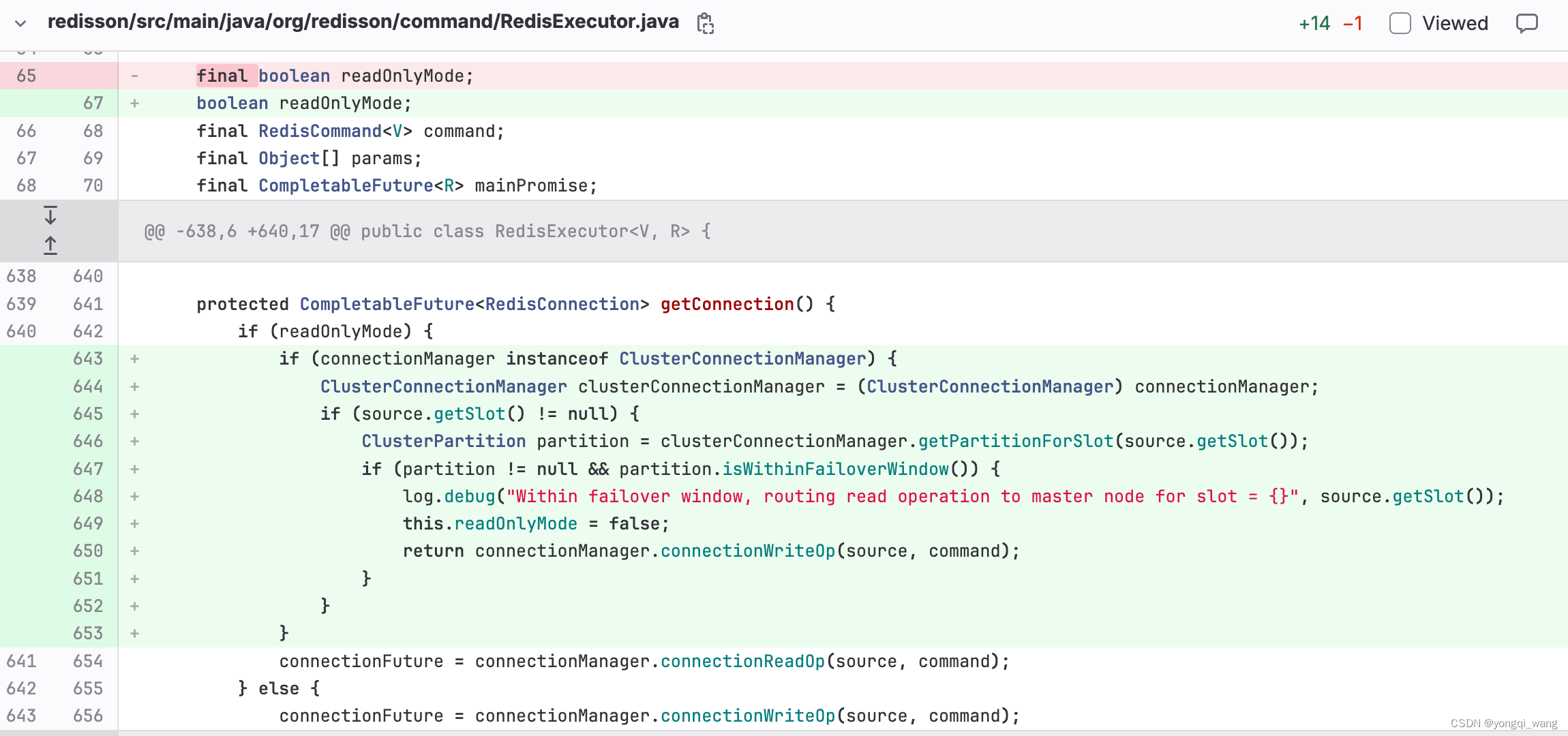
Redisson 3.18.0版本解决failover相关问题
前言 Redisson 在历史多个版本都出现了failover期间报错的问题并且目前没有一个版本可以完全解决这个问题,所以在当前使用版本3.18.0基础上做了二次开发,达到降低业务由于redis遇到问题导致不可用。 背景 Redisson 作为业务线使用的Redis 客户端,在处理 Redis 高可用架构中的故障转移(failover)时面临着特定的挑战。 特别是当 Redis 新的 sl
Oracle10gR2 主备自动切换之客户端Failover配置
http://hi.baidu.com/edeed/item/f4b78096d3ebaaba83d295b5 1. 主库检查和设置 假设新增的服务名为ORCL_TAF.LK. SQL> exec dbms_service.create_service(service_name=>'ORCL_TAF.LK', network_name=>'ORCL_TAF.LK'); SQL> exe

简单了解Cisco ASA Failover技术-ielab
+9Failover特性是Cisco安全产品高可用性的一个解决方案,目的是为了提供不间断的服务,需要两台完全一样的设备,通过一个连接,连接到对方(这个连接也叫心跳线)。该技术用到的两台设备分为 主用和备用,备用处于待机状态。当主用设备故障后,备用设备可启用,并设置为主用,运行自主用设备复制过来的配置(配置是跟随主用设备移动的)。 Failover配置要求两个进行Failover的设备通过专用的f

Redis 4集群failover后客户端未感知拓扑变化排查
排查结论 23:18分,30.1这台机器出现异常,其在30.2上的Slave Redis服务检测到后提出升主请求并获得通过,成为Master;23:18至23:34之间,Redis client端对于Redis Server的连接检测并未异常,没有触发拓扑更新,因而对于Redis Server访问异常;23:34,SRE重启30.1,此时 Redis Client检测到连接断开,触发拓扑更新
Oracle DG failover 后恢复
以pkssk2g01/ pkssk2g02 上SHSKDBG1为例: SHSKDBG1 已经failover切换到原来的备库,现在pkssk2g02是主库, pkssk2g01为备库,现在要把pkssk2g01 上的备库开起来具体步骤如下: 1. 在新主库上(pkssk2g02) 查出failover时的SCN: Select standby_became_primary_scn f
hacmp failover 测试
最近,客户的 hacmp 的两个server 的failover 的切换测试: HACMP for AIX Move cursor to desired item and press Enter. Initialization and Standard Configuration Extended Configurat

pg_auto_failover 之二 postgresql 1 master 1 slave
os: ubuntu 16.04 db: postgresql 10.9 pg_auto_failover 是 citus 开源的一款 postgresql 高可用软件,目前只支持 postgresql 10 及以上. pg_auto_failover is an extension and service for PostgreSQL that monitors and manages au

Mysql 搭建MHA高可用架构,实现自动failover,完成主从切换
目录 自动failover MHA: MHA 服务 项目:搭建Mysql主从复制、MHA高可用架构 实验项目IP地址配置: MHA下载地址 项目步骤: 一、修改主机名 二、编写一键安装mha node脚本和一键安装mha mangaer脚本,并执行安装 三、搭建Mysql主从复制集群(注意所有的Mysql主从复制机器都需要打开二进制日志,可以实现自动故障切换) 四、将安装包
oracle 10g failover,oracle 10g rac failover(service-side TAF)
1,Server-Side TAF具有TAF的所有特点 2,Client-Side TAF 是在客户端修改tnsnames.ora 文件来配置的,如果有很多客户端使用这个数据库,那么每次微调整都需要把所有的客户端修改一遍,既低效又容易出错。而Service-Side TAF 通过结合Service,在数据库里保存FAIL_MODE的配置,把所有的TAF配置保存在数据字典中,从而省去了客户端的配置

mha mysql 坑_MHA-Failover可能遇到的坑
一、主从数据一致性 1.1、如何保证主从数据一致性 在MySQL中,一次事务提交后,需要写undo、写redo、写binlog,写数据文件等等。在这个过程中,可能在某个步骤发生crash,就有可能导致主从数据的不一致。为了避免这种情况,我们需要调整主从上面相关选项配置,确保即便发生crash了,也不能发生主从复制的数据丢失。 MASTER上修改配置 innodb_flush_log_at_trx