factuality专题

论文笔记:LONG-FORM FACTUALITY IN LARGE LANGUAGE MODELS
Abstract 当前存在问题,大模型在生成关于开放主题的事实寻求问题的时候经常存在事实性错误。 LongFact 创建了LongFact用于对各种主题的长形式事实性问题进行基准测试。LongFact是一个prompt集包含38个领域的数千条提示词,使用GPT-4生成。 Search-Augmented Factuality Evaluator(SAFE) SAFE利用大模型将一个相应拆
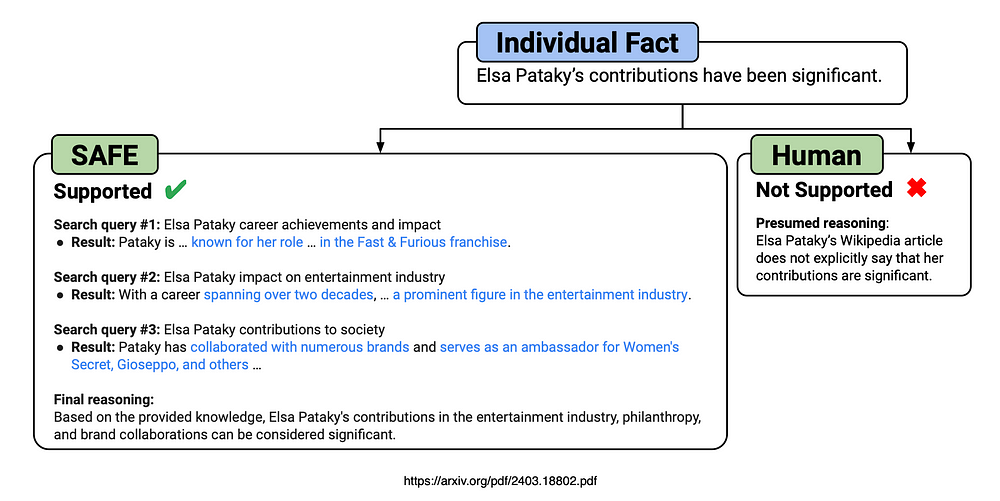
适用于LLM的代理搜索增强事实评估器 (Search-Augmented Factuality Evaluator,SAFE)
原文地址:agentic-search-augmented-factuality-evaluator-safe-for-llms 2024 年 4 月 6 日 介绍 SAFE作为事实性评估代理,其评估结果在72%的情况下与人类众包注释者观点一致。 在随机选取的100个存在分歧的案例中,SAFE的判断结果有76%是正确的。 SAFE的成本比人类注释者低20倍以上。 利用GPT-4生成了Lon