dom4j专题

javaweb-day02-2(00:40:06 XML 解析 - Dom4j解析开发包)
导入dom4j开发包:dom4j-1.6.1.jar 在工程下建一个文件夹lib,将dom4j-1.6.1.jar拷到里边。右键add to build path。 dom4j-1.6.1\lib文件夹下还有一些jar包,是开发过程中dom4j所需要依赖的jar包,如开发过程中报错,则需导入。 用dom4j怎么做呢? 只要是开源jar包提供给你的时候,它会在开源包里面提供
XML-dom4j实战
dom4j是一个用来读取XML的工具包,它是采用DOM思想来读取的,也就是把XML组织成一个文档树,然后根据相应的节点来读取。 import java.io.File;import java.util.ArrayList;import java.util.Iterator;import java.util.List;import org.dom4j.Attribute;import
Dom4j 写文件不全
今天用dom4j 写文件,要么写文件不全,要么文件为空。 刚开始有问题的是: package com.zhangyue.translate;import org.dom4j.Document;import org.dom4j.DocumentException;import org.dom4j.Element;import org.dom4j.io.SAXReader;import ja

dom4j-dom-sax解析
<?xml version="1.0" encoding="UTF-8"?><web-app xmlns="http://www.example.org/web-app_2_5" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://www.example.org/web-app_2_5 w

利用dom4j解析xml
引言 最近有个项目需要解析xml 文件,获取其中的节点内容, 小编选择了一个编码简单又高效的dom4j来完成。 1、xml内容 <?xml version="1.0" encoding="UTF-8"?><RecognizeResult><Speech Uri="/Sub/2019-12-03.3/file/5149-15892322607-20191202141010-rJKTcXfpB
DOM4J学习笔记 --- Node与Element区别
Node是节点,一个属性、一段文字、一个注释等都是节点,而Element是元素, 是比较完整的一个xml的元素(可以由多个Node组成), 比如说<div id="ss"></div>其中它由元素节点、属性节点和文本节点组成,但是它是一个div元素, 我们平时在开发中经常大都使用的是Element,我们怎样把Node转为Element呢,
DOM4J学习笔记 --- Elements 与 Attributers区别
这几天在写Dom4j代码的时候发现了实现一个功能,可以使用Elements与Attributes这两种。 区别可以根据以下两段代码来区分: The first example sex in an attribute: <person sex="female"><firstname>Anna</firstname><lastname>Smith</lastname></
DOM4J学习笔记 --- Java简单解析XML数据
文本格式: <note><to>George</to><from>John</from><heading>Reminder</heading><body>Don't forget the meeting!</body></note> 利用SAXReader读取,解析: package zetyun;import org.dom4j.Document;imp
DOM4J学习笔记 --- Java遍历解析XML
首先准备的文本是: <!-- Edited with XML Spy v2007 (http://www.altova.com)--><CATALOG><CD><TITLE>Empire Burlesque</TITLE><ARTIST>Bob Dylan</ARTIST><COUNTRY>USA</COUNTRY><COMPANY>Columbia</COMPANY><PRICE>
dom4j DocumentException处理
在myeclipse环境下 用dom4j 操作xml时,读取xml文件时遇到的 DocumentException 异常, 处理方式:myeclipse环境下的保存编码、xml的设置编码、与类中的编码统一,避免出现DocumentException 异常出现。 通过OutputFormat format=OutputFormat.createPrettyPrint();format.se

dom4j与xpath
DOM4J与Xpath~ (2007-06-18 17:05:20) 转载▼ 标签: dom4j xpath 分类: 学习 今天的笔记: 要从 XML 文档中提取信息,最快捷简单的办法就是在程序中嵌入 XPath 表达式。XPath是一种为查询 XML 文档而设计的查询语言(其他查询语言还包括结构化查询语言——SQL针对查询特定
使用Dom4j创建XML文件
public void CreateXMLByDOM4J() {// 创建Document对象Document document = DocumentHelper.createDocument();// 创建根节点Element rss = document.addElement("rss");//为rss根节点添加属性rss.addAttribute("version", "2.0");// 创

xml(3)--dom4j实现crud操作
1.XML解析技术概述 (1)XML解析方式分为两种:dom和sax dom:(Document Object Model, 即文档对象模型) 是 W3C 组织推荐的处理 XML 的一种标准方式。 sax: (Simple API for XML) 不是官方标准,但它是 XML 社区事实上的标准,几乎所有的 XML 解析器都支持它。 (2)XML解析器(软件/实现类) C
xml(2)--dom4j解析xml文件
今天学习了xml解析中的dom4j技术,感觉很好用,而且还不难。在网上看到这个哥们写的真好,所以借鉴过来。参考的位置为:http://blog.163.com/kewangwu@126/blog/static/8672847120126261033594/ 1、DOM4J简介 DOM4J是 dom4j.org 出品的一个开源 XML 解析包。DOM4J应用于 Java 平台,采用了 Ja
dom4j中Xpath的应用
定义:XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。 此语言比较容易理解,仅举例: public voidbar(Document document) { //所有foo节点下的bar节点 List list =do
使用dom4j解析指定节点下的信息
需要的 jar 包: dom4j-1.6.1.jar jaxen-1.1.1.jar log4j-1.2.8.jar sql.xml <?xml version="1.0" encoding="UTF-8"?><config><sql><user><queryList>select * from t_user</queryList></user></sql></confi
dom4j解析和生成XML文件
转化XML import org.dom4j.Document;import org.dom4j.DocumentException;import org.dom4j.io.SAXReader;public class Foo {public Document parse(URL url) throws DocumentException {SAXReader reader = new SA
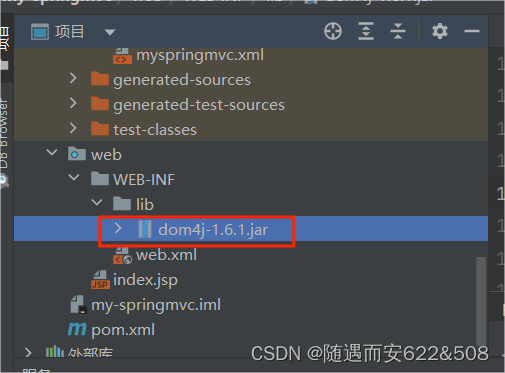
java.lang.NoClassDefFoundError: org/dom4j/io/SAXReader
问题描述:在maven项目中,给SAXReader创建实例,启动tomcat服务器后报异常java.lang.NoClassDefFoundError: org/dom4j/io/SAXReader。我在pom文件中是引入了dom4j依赖得,但是不知道为什么在上传到web时就找不到了 解决办法: 在WEB-INF目录下新建lib目录,手动将dom4j的jar包导入(该jar包可在文章顶部获取)
XML-JDOM和DOM4J比较
1、JDOM JDOM的目的是成为 Java 特定文档模型,它简化与 XML 的交互并且比使用 DOM 实现更快。由于是第一个 Java 特定模型,JDOM 一直得到大力推广和促进。正在考虑通过“Java 规范请求 JSR-102”将它最终用作“Java 标准扩展”。从 2000 年初就已经开始了 JDOM 开发。 JDOM 与 DOM 主要有两方面不同。首先,JDOM 仅使
Eclipse java.lang.NoClassDefFoundError: org/dom4j/io/SAXReade 错误解决方法
为什么我明明在Eclipse的项目中导入了dom4j的jar包,但是在实例化SAXReader类还是失败了? 原因:没有正确地导入jar包。 正确导入jar包的方法之一: 1.将jar包直接拖到工程的WebRoot / WEB-INF / lib目录下: 弹出对话框后选择Copy或Link均可(如果你有一个固定的Jar目录,那么可以用Link方式,如果你希望项目无论迁移到
Java——采用DOM4J+单例模式实现XML文件的读取
大家对XML并不陌生,它是一种可扩展标记语言,常常在项目中作为配置文件被使用。XML具有高度扩展性,只要遵循一定的规则,XML的可扩展性几乎是无限的,而且这种扩展并不以结构混乱或影响基础配置为代价。项目中合理的使用配置文件可以大大提高系统的可扩展性,在不改变核心代码的情况下,只需要改变配置文件就可以实现功能变更,这样也符合编程开闭原则。 但是我们把数据或者信息写到配置文件中,其他类或者模
Dom4j解析【开发中常用】
需要导包:dom4j-1.6.1.jar jaxen-1.1-beta-6.jar ------读取--------- package com . atguigu . xml . dom4j ; import java . util . Iterator ; import java . util . List ; import or
dom4j处理xml在linux环境下中文乱码
最近在搞一个webservice 的soap接口数据同步,接口提供方就是个鸟人,两个接口来来回回写了2个月才调通,我也真是服了 ———**——– 好了吐槽到此结束,下面说说乱码的问题 dom4j 解析xml 就是一个把字符串、文件、输入流转换成文本(Document )再处理的过程;下面附上代码 InputStream in = new ByteArrayInputStream(fyxx.
使用dom4j最简单的读取一个xml文件的内容
用之前不要忘了导入dom4j的jar包哦! test.xml <?xml version="1.0" ?><HD><disk name="C"><Size>500</Size></disk><disk name="D"><Size>200</Size></disk></HD> Test.java package com.bandc.spring.dao;import
java操作xml之dom4j中的xpath实现用户登陆验证
直接上代码 xml文档:user.xml <?xml version="1.0" encoding="UTF-8"?><db><users username="aaa" password="123" age="25"></users><users username="bbb" password="123" age="25"></users><users username="ccc" pass
java操作xml之dom4j的增删改查
注意,保存的时候一定要注意编码问题,你的xml文档的编码类型是什么就在format那里设置一样的,否则就会乱码的。 XML测试文档: <?xml version="1.0" encoding="UTF-8"?><商店> <商品> <名称 name="hhhh">手机</名称> <价格>1290</价格> <数量>90部</数量> </商品> <商品> <名称>电脑</名称> <价格>1