distilbert专题

第13章:DistilBERT:smaller, faster, cheaper and lighter的轻量级BERT架构剖析及完整源码实现
1,基于pretraining阶段的Knowledge distillation 2,Distillation loss数学原理详解 3,综合使用MLM loss、distillation loss、cosine embedding loss 4,BERT Student architecture解析及工程实践 5,抛弃了BERT的token_type_ids的DistilBERT 6,
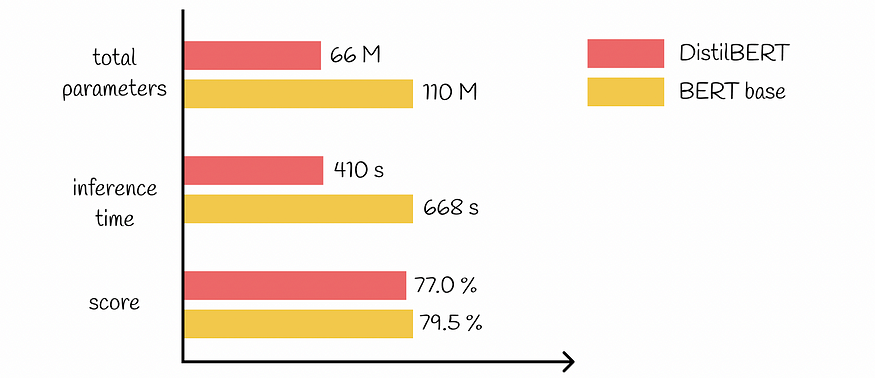
大型语言模型:DistilBERT — 更小、更快、更便宜、更轻
一、介绍 近年来,大型语言模型的演进速度飞速发展。BERT成为最流行和最有效的模型之一,可以高精度地解决各种NLP任务。在BERT之后,一组其他模型随后出现在现场,也展示了出色的结果。 很容易观察到的明显趋势是,随着时间的推移,大型语言模型(LLM)往往会通过成倍增加它们所训练的参数和数据的数量而变得更加复杂。深度学习的研究表明,这种技术通常会

论文阅读——DistilBERT
ArXiv:https://arxiv.org/abs/1910.01108 Train Loss: DistilBERT: DistilBERT具有与BERT相同的一般结构,层数减少2倍,移除token类型嵌入和pooler。从老师那里取一层来初始化学生。 The token-type embeddings and the pooler are removed while t
大型语言模型:DistilBERT — 更小、更快、更便宜、更轻
一、介绍 近年来,大型语言模型的演进速度飞速发展。BERT成为最流行和最有效的模型之一,可以高精度地解决各种NLP任务。在BERT之后,一组其他模型随后出现在现场,也展示了出色的结果。 很容易观察到的明显趋势是,随着时间的推移,大型语言模型(LLM)往往会通过成倍增加它们所训练的参数和数据的数量而变得更加复杂。深度学习的研究表明,这种技术通常会