ddp专题

多进程并行(如 PyTorch 的 DistributedDataParallel,DDP)和多 GPU 并行(如 DataParallel)的对比
多进程并行(如 PyTorch 的 DistributedDataParallel,DDP)和多 GPU 并行(如 DataParallel)确实有很大的区别,但并不能简单地说多 GPU 并行效果一定更好。让我们比较一下这两种方法: 多进程并行(DistributedDataParallel): 每个 GPU 对应一个独立的 Python 进程。每个进程有自己的模型副本和优化器。梯度同步是通过

DDP、FDDP、BOXDDP算法概要
DDP、FDDP、BOXDDP算法 DDP:适用于一般的最优控制问题,具有较好的数值稳定性。FDDP:改进了可行性,适用于需要严格满足动力学和约束条件的控制问题。BOXDDP:引入了控制输入约束,适用于存在物理限制的控制问题。 1. DDP(Differential Dynamic Programming) 基本原理 DDP是一种递归的最优控制算法,基于动态规划原理。它在给定初始条件和目标
yolov8 ultralytics库实现多机多卡DDP训练
参考: https://github.com/ultralytics/ultralytics/issues/6286 ddp训练报错,问题修改: https://blog.csdn.net/weixin_41012399/article/details/134379417 RuntimeError: CUDA error: invalid device ordinal CUDA kernel

yolov8 ultralytics库进行多机多卡DDP训练
参考: https://github.com/ultralytics/ultralytics/issues/6286 ddp训练报错,问题修改: https://blog.csdn.net/weixin_41012399/article/details/134379417 RuntimeError: CUDA error: invalid device ordinal CUDA kernel

Pytorch DDP分布式细节分享
自动微分和autograde 自动微分 机器学习/深度学习关键部分之一:反向传播,通过计算微分更新参数值。 自动微分的精髓在于它发现了微分计算的本质:微分计算就是一系列有限的可微算子的组合。 自动微分以链式法则为基础,依据运算逻辑把公式整理出一张有向无环图(DAG) 自动微分将一个复杂的数学运算过程分解为一系列简单的基本运算, 其中每一项基本运算都可以通过查表得出来。 自动微分法被认为是对计算
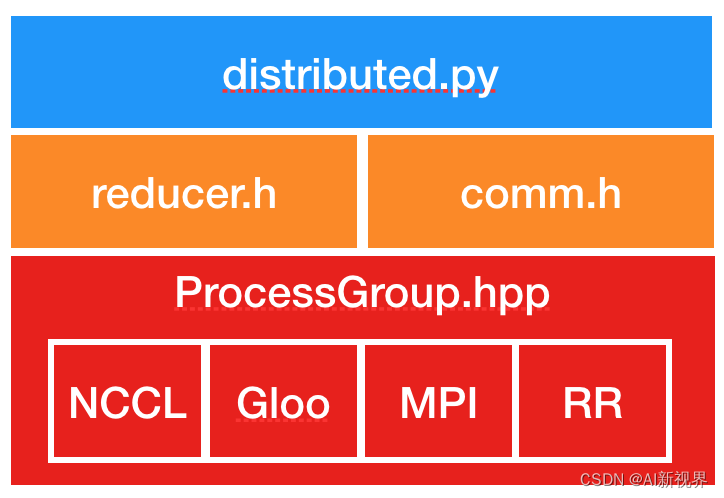
『PyTorch学习笔记』分布式深度学习训练中的数据并行(DP/DDP) VS 模型并行
分布式深度学习训练中的数据并行(DP/DDP) VS 模型并行 文章目录 一. 介绍二. 并行数据加载2.1. 加载数据步骤2.2. PyTorch 1.0 中的数据加载器(Dataloader) 三. 数据并行3.1. DP(DataParallel)的基本原理3.1.1. 从流程上理解3.1.2. 从模式角度理解3.1.3. 从操作系统角度看3.1.4. 低效率 3.2. DDP(D
Pytorch采坑记录:DDP 损失和精度比 DP 差,多卡GPU比单卡GPU效果差
结论:调大学习率或者调小多卡GPU的batch_size 转换DDP模型后模型的整体学习率和batch_size都要变。 当前配置::1GPU:学习率=0.1,batch_size=64 如果8GPU还按之前1GPU配置:8GPU:学习率=0.1,batch_size=64 那么此时对于8GPU而言,效果几乎等于::1GPU:学习率=0.1,batch_size=64 * 8=512 这种

pytorch单精度、半精度、混合精度、单卡、多卡(DP / DDP)、FSDP、DeepSpeed模型训练
pytorch单精度、半精度、混合精度、单卡、多卡(DP / DDP)、FSDP、DeepSpeed模型训练、模型保存、模型推理、onnx导出、onnxruntime推理等示例代码,并对比不同方法的训练速度以及GPU内存的使用。 代码:pytorch_model_train FairScale(你真的需要FSDP、DeepSpeed吗?) 在了解各种训练方式之前,先来看一下 FairSc
Pytorch采坑记录:DDP 损失和精度比 DP 差,多卡GPU比单卡GPU效果差
结论:调大学习率或者调小多卡GPU的batch_size 转换DDP模型后模型的整体学习率和batch_size都要变。 当前配置::1GPU:学习率=0.1,batch_size=64 如果8GPU还按之前1GPU配置:8GPU:学习率=0.1,batch_size=64 那么此时对于8GPU而言,效果几乎等于::1GPU:学习率=0.1,batch_size=64 * 8=512 这种

AI分布式训练:DDP (数据并行)技术详解与实战
编者按: 如今传统的单机单卡模式已经无法满足超大模型进行训练的要求,如何更好地、更轻松地利用多个 GPU 资源进行模型训练成为了人工智能领域的热门话题。 我们今天为大家带来的这篇文章详细介绍了一种名为 DDP(Distributed Data Parallel)的并行训练技术,作者认为这项技术既高效又易于实现。 文章要点如下: (1)DDP 的核心思想是将模型和数据复制到多个 GPU 上并行训练
单机多卡训练-DDP
DDP原理: 为什么快? DDP通过Ring-Reduce(梯度合并)的数据交换方法提高了通讯效率,并通过启动多个进程的方式减轻Python GIL的限制,从而提高训练速度。 神经网络中的并行有以下三种形式: Data Parallelism 这是最常见的形式,通俗来讲,就是增大batch size提高并行度。 平时我们看到的多卡并行就属于这种。比如DP、DDP都是。这能让我们方便地利
『PyTorch学习笔记』分布式深度学习训练中的数据并行(DP/DDP) VS 模型并行
分布式深度学习训练中的数据并行(DP/DDP) VS 模型并行 文章目录 一. 介绍二. 并行数据加载2.1. 加载数据步骤2.2. PyTorch 1.0 中的数据加载器(Dataloader) 三. 数据并行3.1. DP(DataParallel)的基本原理3.1.1. 从流程上理解3.1.2. 从模式角度理解3.1.3. 从操作系统角度看3.1.4. 低效率 3.2. DDP(D

『PyTorch学习笔记』分布式深度学习训练中的数据并行(DP/DDP) VS 模型并行
分布式深度学习训练中的数据并行(DP/DDP) VS 模型并行 文章目录 一. 介绍二. 并行数据加载2.1. 加载数据步骤2.2. PyTorch 1.0 中的数据加载器(Dataloader) 二. 数据并行2.1. DP(DataParallel)的基本原理2.1.1. 从流程上理解2.1.2. 从模式角度理解2.1.3. 从操作系统角度看2.1.4. 低效率 2.2. DDP(D
Pytorch ddp切换forward函数 验证ddp是否生效
DDP及其在pytorch中应用 ddp默认调用forward函数,有些模型无法使用forward函数,可以对模型包装一下。 class modelWraper(nn.Module):def __init__(self, model):super().__init__()self.model = modeldef forward(self, *args, **kwargs):return se
解决DDP的参数未参与梯度计算
将find_unused_parameters改成False之后,如果出现模型有些参数未参与loss计算等错误。 可以用环境变量来debug查看log。 export TORCH_DISTRIBUTED_DEBUG=DETAIL 代码上可以用以下方法查看。 # check parameters with no gradfor n, p in model.named_paramet