dataparallel专题

多进程并行(如 PyTorch 的 DistributedDataParallel,DDP)和多 GPU 并行(如 DataParallel)的对比
多进程并行(如 PyTorch 的 DistributedDataParallel,DDP)和多 GPU 并行(如 DataParallel)确实有很大的区别,但并不能简单地说多 GPU 并行效果一定更好。让我们比较一下这两种方法: 多进程并行(DistributedDataParallel): 每个 GPU 对应一个独立的 Python 进程。每个进程有自己的模型副本和优化器。梯度同步是通过

pytorch使用DataParallel并行化保存和加载模型(单卡、多卡各种情况讲解)
话不多说,直接进入正题。 !!!不过要注意一点,本文保存模型采用的都是只保存模型参数的情况,而不是保存整个模型的情况。一定要看清楚再用啊! 1 单卡训练,单卡加载 #保存模型torch.save(model.state_dict(),'model.pt')#加载模型model=MyModel()#MyModel()是你定义的创建模型的函数,就是先初始化得到一个模型实例,之后再将模型参数加
nn.DataParallel
nn.DataParallel 是 PyTorch 中的一个模块,用于在多个 GPU 上并行运行模型。当有多个 GPU 并且想要利用它们来加速训练或推理时,这个模块会非常有用。nn.DataParallel 通过对模型中的每个子模块进行复制,并将输入数据分割成多个部分,然后在每个 GPU 上并行处理这些部分来实现并行化。 使用 nn.DataParallel 的基本步骤是: 初始化模型:首先,

'dataparallel' object has no attribute问题的解决(分布式预训练模型加载)
在一些预训练模型的加载过程中,发现在进行forward的过程中,会碰到dataparallel' object has no attribute的问题。打印model信息,可以看到其为DataParallel对象,即在训练的过程中,采用了分布式训练的方法所得到的预训练模型。而model真正内容则包含在里面。 因此需要去掉DataParallel这一层,具体做法如下: 通过这样的方法就只可以
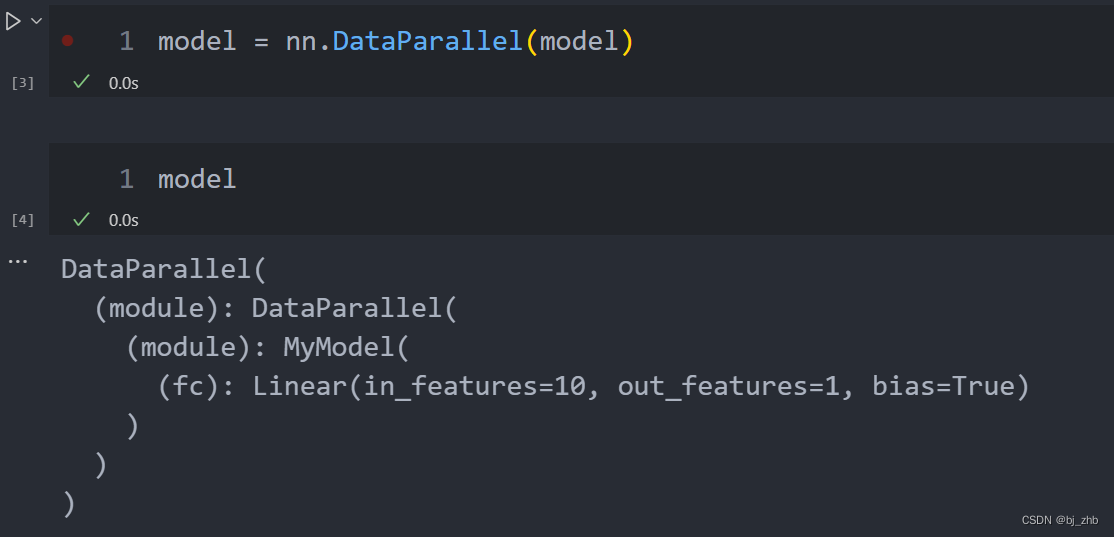
pytorch中nn.DataParallel多次使用
pytorch中nn.DataParallel多次使用 import torchimport torch.nn as nnimport torch.optim as optimfrom torch.utils.data import DataLoader# 定义模型class MyModel(nn.Module):def __init__(self):super(MyModel, sel