cvpr2018专题
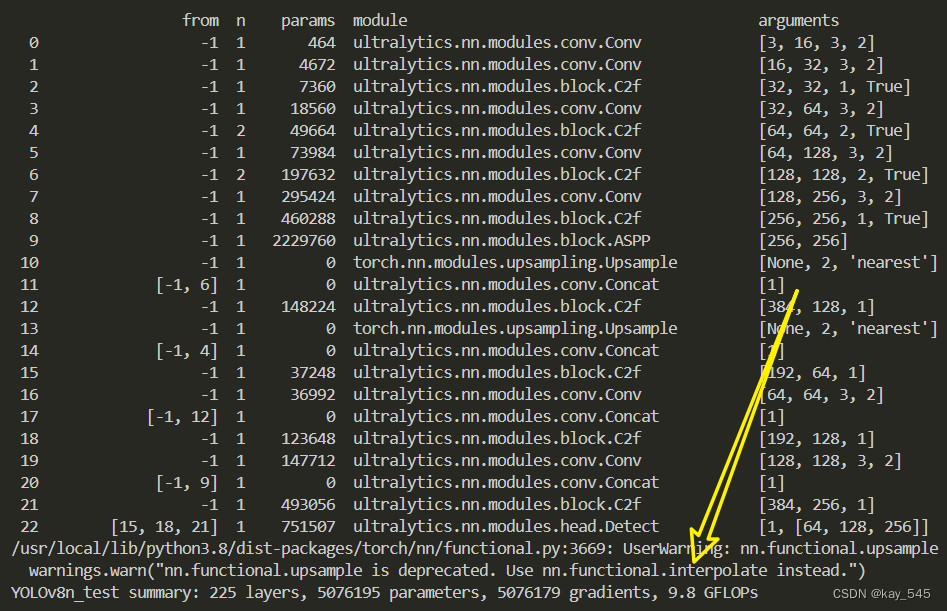
YOLOv8改进 | SPPF | 具有多尺度带孔卷积层的ASPP【CVPR2018】
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡 专栏目录 :《YOLOv8改进有效涨点》专栏介绍 & 专栏目录 | 目前已有40+篇内容,内含各种Head检测头、损失函数Loss、Backbone、Neck、NMS等创新点改进——点击即可跳转 Atrous Spatial Pyramid Pooling (ASPP) 是一种在深度学习框架中用于语义分割的网络结构,它旨

【CVPR2018】DeepMind最新演讲:VAEs and GANs
导读:在CVPR2018会议上,DeepMInd科学家分享了结合GANs和VAEs各自优势的GAN hybrids模型,两者不仅可以提高VAE的采样质量和改善表示学习,另一方面也可提高GAN的稳定性和丰富度。 参考:作者主页: http://elarosca.net

论文阅读(【CVPR2018】Jinshan Pan - Learning Dual Convolutional Neural Networks for Low-Level Vision)
论文阅读(【CVPR2018】Jinshan Pan - Learning Dual Convolutional Neural Networks for Low-Level Vision) 目录 论文和作者 论文 作者 方法概述 网络结构 损失函数 网络参数 实验 图像去雾 实验结果 图像超分辨率重建 实验结果 图像去雨 实验结果 图像保边滤波
![论文分享[cvpr2018]Non-local Neural Networks非局部神经网络](https://img-blog.csdnimg.cn/direct/690a833bf8324c1f943891fa2c0c00d4.png)
论文分享[cvpr2018]Non-local Neural Networks非局部神经网络
论文 https://arxiv.org/abs/1711.07971 代码https://github.com/facebookresearch/video-nonlocal-net 非局部神经网络 motivation:受计算机视觉中经典的非局部均值方法[4]的启发,非局部操作将位置的响应计算为所有位置的特征的加权和。 非局部均值方法 NLM(Non-local Means)滤

CVPR2018 | CMU谷歌Spotlight论文:超越卷积的视觉推理框架
人类在看到图像时可以进行合理的推理与预测,而目前的神经网络系统却还难以做到。近日,来自卡耐基梅隆大学(CMU)的陈鑫磊(现 Facbook 研究科学家)、Abhinav Gupta,谷歌的李佳、李飞飞等人提出了一种新型推理框架,其探索空间和语义关系的推理性能大大超过了普通卷积神经网络。目前该工作已被评为 CVPR 2018 大会 Spotlight 论文。 近年来,我们在图像分类 [ 16
![[TRACA(CVPR2018)]论文阅读笔记](https://img-blog.csdnimg.cn/20190403160249408.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NpbmF0XzMxMTg0OTYx,size_16,color_FFFFFF,t_70)
[TRACA(CVPR2018)]论文阅读笔记
Context-aware Deep Feature Compression for High-speed Visual Tracking 论文地址 写在前面 这是韩国首尔大学2018年CVPR上的一个工作,利用深度特征+相关滤波的形式做的,其中比较新的地方就是设计了一系列encoder来更好编码目标的特征,更加注重目标本身的一些context的信息,论文里面用了很多操作来提升精度。 Mot

【FlowTrack(CVPR2018)】:目标跟踪论文阅读
End-to-end Flow Correlation Tracking with Spatial-temporal Attention 论文地址 写在前面 这是中科院大大朱政在商汤实习的时候做的,发表在2018年的CVPR上,文中提到这是第一篇将光流法和深度跟踪端到端训练的方法,他们使用的光流法就是2015年提出的FlowNet,文章只是将其拿过来重新训练了一下,没有太多讲其中的结构,而且朱

Learning a Single Convolutional Super-Resolution Network for Multiple Degradations(CVPR2018) 阅读理解
我们提出了一个简单但有效且可扩展的deep CNN框架为SISR。该模型超越了广泛使用的双三次退化假设,适用于多种甚至是空间变化的退化,为开发一种实际应用的基于cnn的超解析器迈出了实质性的一步; 针对LR输入图像、模糊核和噪声之间的维数不匹配问题,提出了一种新的维数拉伸策略。虽然这个策略是为SISR提出的,但它是通用的,可以扩展到其他任务,如去模糊。如下图,感觉这个

读书笔记21:MiCT: Mixed 3D/2D Convolutional Tube for Human Action Recognition(CVPR2018)
http://openaccess.thecvf.com/content_cvpr_2018/papers/Zhou_MiCT_Mixed_3D2D_CVPR_2018_paper.pdf 本文考虑到在识别人体动作的时候,3D CNN的水平不及2D CNN在识别静态图片时的水平,认为这是由于3D CNN消耗的计算资源和存储资源过大导致不能很好的训练,因此在本文中提出了一个2D和3D CNN结合的