clusters专题
MapReduce Simplified Data Processing on Large Clusters 论文笔记
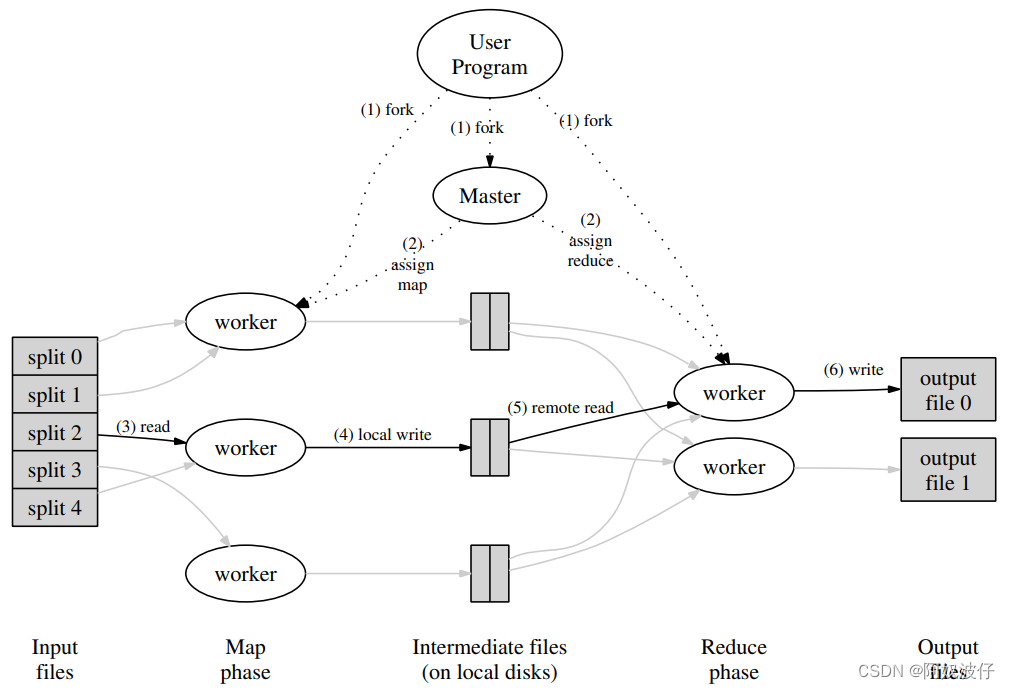
2003年USENIX,出自谷歌,开启分布式大数据时代的三篇论文之一,作者是 Jeffrey 和 Sanjay,两位谷歌巨头。 Abstract MapReduce 是一种变成模型,用于处理和生成大规模数据。用户指定 map 函数处理每一个 key/value 对来产生中间结果的 key/value 对;reduce 函数合并每一个相同中间 key 的 value。 这种编程风格能自动获得并
YOLC: You Only Look Clusters for Tiny Object Detection in Aerial Images
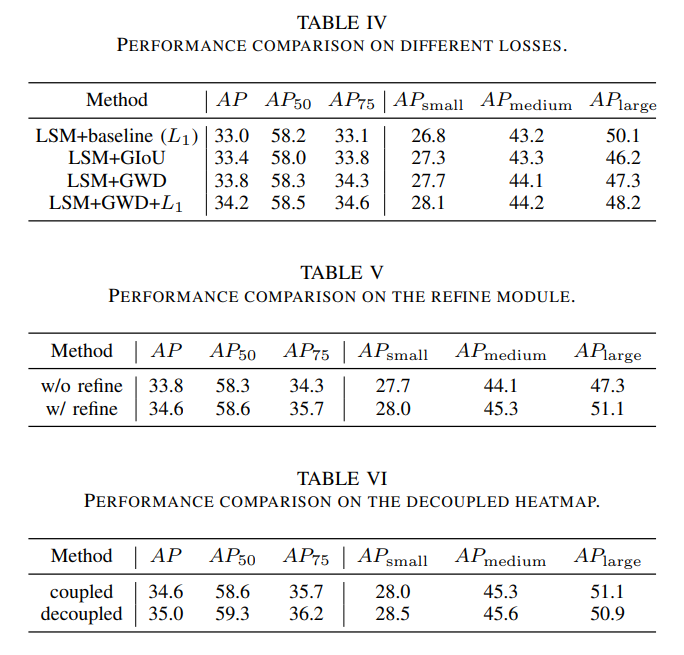
摘要 由于以下因素,从航拍图像中检测物体面临着重大挑战:1)航拍图像通常具有非常大的尺寸,通常有数百万甚至数亿像素,而计算资源有限。2)物体尺寸较小导致有效信息不足,无法进行有效检测。3)物体分布不均匀导致计算资源浪费。为了解决这些问题,我们提出YOLC(You Only Look Clusters),一种基于无锚点目标检测器CenterNet的高效且有效的框架。为了克服大规模图像和非均匀物体分

【PAT】1107. Social Clusters (30)【树的层次遍历】
题目描述 When register on a social network, you are always asked to specify your hobbies in order to find some potential friends with the same hobbies. A social cluster is a set of people who have some o

【论文阅读】Energy Efficient Real-time Task Scheduling on CPU-GPU Hybrid Clusters
Energy Efficient Real-time Task Scheduling on CPU-GPU Hybrid Clusters 出处:2017IEEE Xplore 基于CPU-GPU混合集群的高效实时任务调度 主要工作:通过动态电压和频率缩放研究了新兴CPU-GPU混合集群的节能问题。 首次分析GPU特定的DVFS模型。 设计了一种新的调度算法:1)利用GPU DVFS来节

【课程论文阅读】MapReduce: Simplified Data Processing on Large Clusters
文章目录 paper 中文翻译 MapReduce 论文阅读—不错的博客 该博主其他文章: 6.824 分布式系统课程学习总结
【课程论文阅读】MapReduce: Simplified Data Processing on Large Clusters
文章目录 paper 中文翻译 MapReduce 论文阅读—不错的博客 该博主其他文章: 6.824 分布式系统课程学习总结

sklearn机器学习之Kmeans根据轮廓系数选择参数n_clusters
1.导入相应包 from sklearn.cluster import KMeansfrom sklearn.metrics import silhouette_samples, silhouette_scorefrom matplotlib import pyplot as pltfrom matplotlib import cmimport numpy as npfrom skle

pycharm-ConvergenceWarning: Number of distinct clusters (19) found smaller than n_clusters (20).
ConvergenceWarning: Number of distinct clusters (19) found smaller than n_clusters (20). pycharm利用Kmeans做文本聚类,选择最优k值时,飘红 可以发现,从20开始就飘红了,追溯代码,可能是聚类中心点个数设置太大了,n_features达到20时error已经等于0,后面的也就无需设置太多

对于MapReduce: Simplified Data Processing on Large Clusters 的理解
MapReduce: Simplified Data Processing on Large Clusters这个论文原版的没看,找了几个网上流传的翻译稿,认真看了一遍。因为内容主要为大数据方面,目前自己还没直接接触到这方面的内容,先记录一下收获,不然用到的时候都忘光了(见笑了。。) 先记录一下翻译比较好的文章,我自己看着逻辑上没啥大毛病的翻译稿(个人水平有限,别吐槽,见谅。。。): 第一个是
![PAT甲级1107 Social Clusters (30 分):[C++题解]并查集,爱好、人数](https://img-blog.csdnimg.cn/20210211222153329.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NoaXpoZW5nX0xp,size_16,color_FFFFFF,t_70)
PAT甲级1107 Social Clusters (30 分):[C++题解]并查集,爱好、人数
文章目录 题目分析题目链接 题目分析 来源:acwing 分析: 凭爱好,分人群。注意点:爱好可传递。什么意思?意思是A和B的有共同爱好1, B和C有共同爱好2,那么认为A和C也是同一群人。 按照爱好将人分成几组。使用vector<int> hobby[N];二维数组:<爱好,人> ac代码 #include<bits/stdc++.h>using names
![1107. Social Clusters (30)[并查集]](/front/images/it_default.jpg)
1107. Social Clusters (30)[并查集]
1. 原题: https://www.patest.cn/contests/pat-a-practise/1107 2. 思路: 题意: 根据共同的兴趣找出共有几个圈子。 思路: 并查集问题。 根据题意,很容易知道是关于集合的问题。对于集合问题,并查集是最简单的。 当然可以用bfs,但是没有并查集算法简捷。 并查集其实就两个函数,一个合并,一个查找根。 两个数组s和hobby
1107. Social Clusters 解析
兴趣圈,并查集的问题。 把爱好用并查集来处理,处理完了,再将人按爱好进行分类。统计。 #include <iostream>#include <vector>#include <set>#include <algorithm>#include <cstring>#define MAX 1010using namespace std;int hobbie[MAX];set <
DL2: A Deep Learning-Driven Scheduler for Deep Learning Clusters(论文笔记)
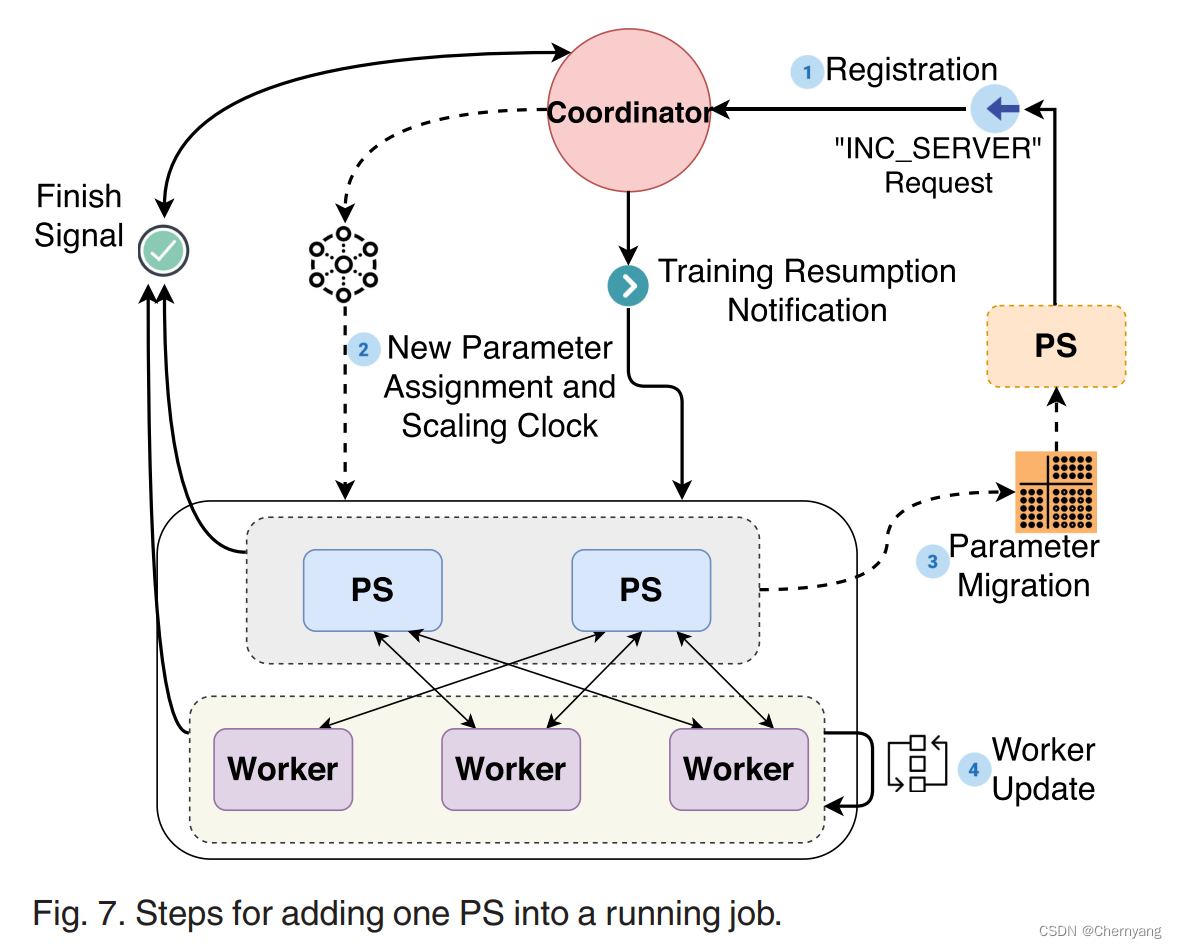
文章目录 问题概述深度学习集群DL2调度器 学习策略神经网络状态State动作ActionNN架构 离线监督学习在线强化学习奖励RewardPolicy Gradient-Based LearningActor-CriticJob-Aware Exporation经历重放 弹性缩放加入PS加入worker 问题 在一个共享深度学习集群中,会有许多训练任务同时执行。此时,为了更
PAT_A 1107. Social Clusters (30)
1107. Social Clusters (30) When register on a social network, you are always asked to specify your hobbies in order to find some potential friends with the same hobbies. A “social cluster” is a set o

Largest Redis Clusters Ever
前言: Tape is Dead,Disk is Tape,Flash is Disk,RAM Locality is King. — Jim Gray Redis不是比较成熟的Memcache或者MySQL的替代品,是对于大型互联网类应用在架构上很好的补充。现在有越来越多的应用也在纷纷基于Redis做架构的改造。 可以简单公布一下Redis平台实际情况 2200+亿 command