canopy专题
win7下安装Canopy(EPD) 及 Pandas进行python数据分析
先安装好canopy,具体安装版本看自己需要那种,我本来是打算安装win764位的,却发现下载总是出现错误,无奈只能下载了32位的! https://store.enthought.com/downloads/#default 安装好之后,参考如下连接,进行检验: 之后再根据下面提供的连接进行操作,一般是没问题的! http://jingyan.baidu.com/article/5d6

使用canopy生成和k-means聚类对新闻进行聚类
<strong><span style="font-size:18px;">/***** @author YangXin* @info 使用canopy生成和k-means聚类对新闻进行聚类*/package unitNine;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileSystem;

基于Kmeans+Canopy聚类的协同过滤算法代码实现(输出聚类计算过程,分布图展示)
基于Kmeans+Canopy聚类的协同过滤算法代码实现(输出聚类计算过程,分布图展示) 聚类(Clustering)就是将数据对象分组成为多个类或者簇 (Cluster),它的目标是:在同一个簇中的对象之间具有较高的相似度,而不同簇中的对象差别较大。所以,在很多应用中,一个簇中的数据对象可以被作为一个整体来对待,从而减少计算量或者提高计算质量。 一、Kmeans+Canopy聚类算法实现原理
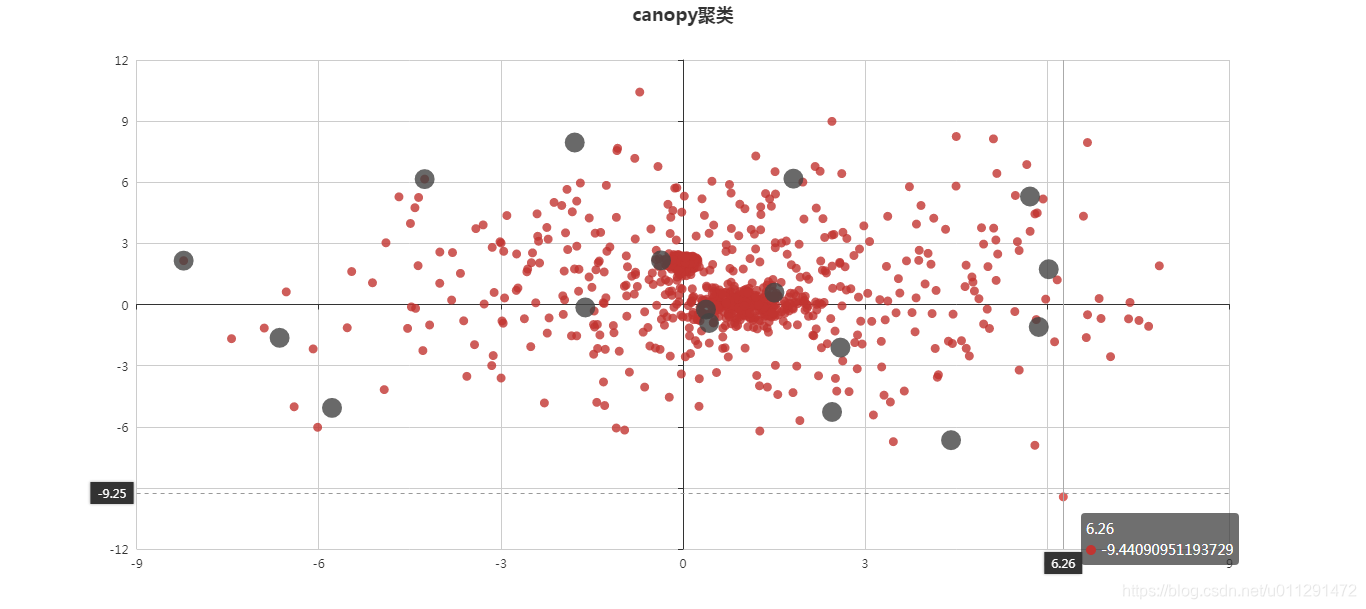
基于Canopy聚类的协同过滤算法代码实现(输出聚类计算过程,分布图展示)
基于Canopy聚类的协同过滤算法代码实现(输出聚类计算过程,分布图展示) 聚类(Clustering)就是将数据对象分组成为多个类或者簇 (Cluster),它的目标是:在同一个簇中的对象之间具有较高的相似度,而不同簇中的对象差别较大。所以,在很多应用中,一个簇中的数据对象可以被作为一个整体来对待,从而减少计算量或者提高计算质量。 一、Canopy聚类算法实现原理 Canopy聚类算法的基
准备工作Canopy安装Day1
说明:本文章为Python数据处理学习日志,主要内容来自书本《利用Python进行数据分析》,Wes McKinney著,机械工业出版社。 安装和设置 作者推荐Python安装包为ENthought Python Distribution(现更名Enthought Canopy),译本发行时间距现在有2年时间,所以期间有版本更新,译者建议下载书中提到的安装包版本epd_free_7.3-1-w
Mahout clustering Canopy+K-means 源码分析
聚类分析 聚类(Clustering)可以简单的理解为将数据对象分为多个簇(Cluster),每个簇里的所有数据对象具有一定的相似性,这样一个簇可以看作一个整体,以此可以提高计算质量或减少计算量。而数据对象间相似性的衡量通常是通过坐标系中空间距离的大小来判断;常见的有 欧几里得距离算法、余弦距离算法、皮尔逊相关系数算法等,Mahout对此都提供了实现,并且你可以在实现自己的