bulkload专题
HBase bulkload
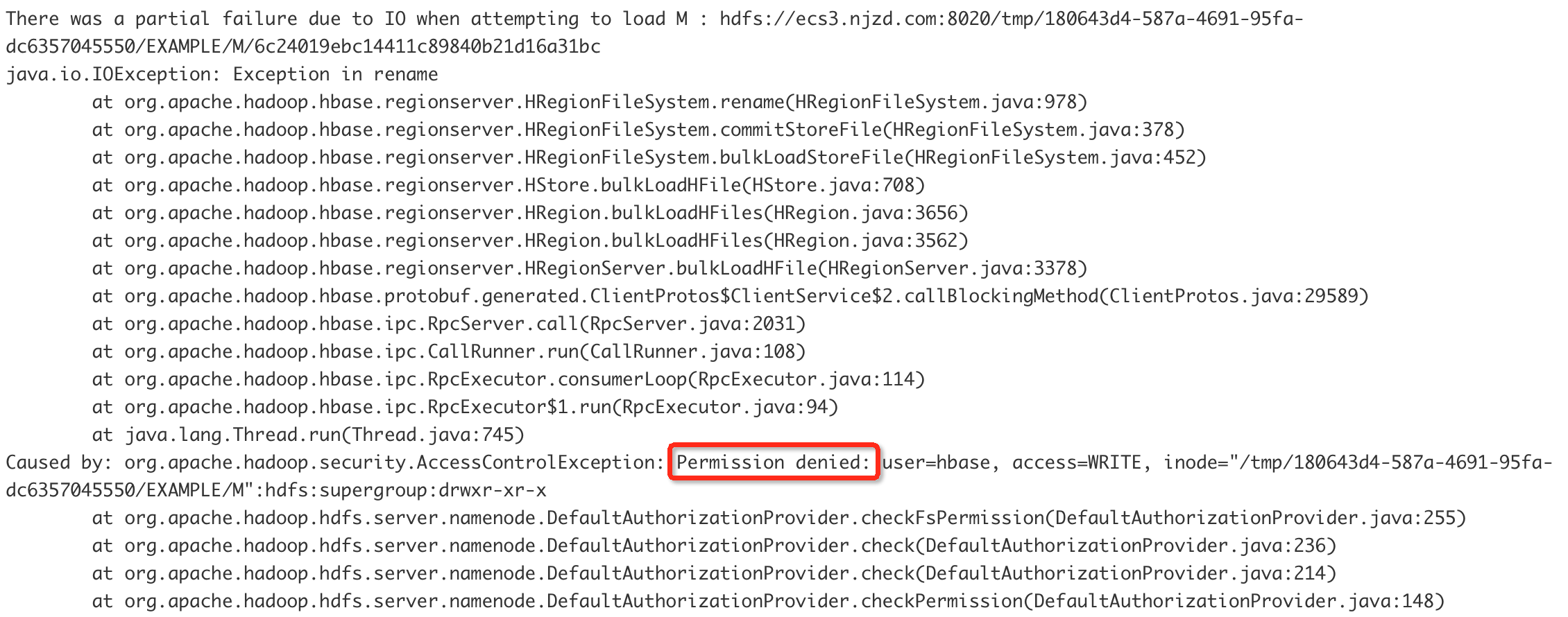
通过直接生成HFile文件,可以将要保存数据bulkload到HBase中,速度比使用HBase API要快很多。 在生成了HFile之后,一般通过HFileOutputFomat这个工具来将其导入到HBase表在HDFS中的目录。 遇到的问题 导入HFile时权限不够 在使用HFileOutputFomat来导入HFile时,很可能会发现导入的过程卡住不动了,如下: 实际上,卡住的
Cassandra数据迁移-BulkLoad离线工具介绍
该工具通过文件流接口快速导入数据到cassandra集群,是最快地将线下数据迁移到线上cassandra集群方法之一,准备工作如下 线上cassandra集群线下数据,sstable格式或者csv格式。同vpc一台独立的ecs,开放安全组,能访问cassandra集群端口 1. 准备同vpc下客户端ecs 建议独立的ecs,不要和线上cassandra集群混用,混用会影响线上服务。

Spark写入HBase(BulkLoad方式)
在使用Spark时经常需要把数据落入HBase中,如果使用普通的Java API,写入会速度很慢。Spark提供了Bulk写入方式的接口。那么Bulk写入与普通写入相比有什么优势呢? BulkLoad不会写WAL,也不会产生flush以及split。如果我们大量调用PUT接口插入数据,可能会导致大量的GC操作。除了影响性能之外,严重时甚至可能会对HBase节点的稳定性造成影响。但是采用Bulk就

HBASE学习九:数据写入 -> BulkLoad
1、功能 在实际生产环境中,有这样一种场景:用户数据位于HDFS中,业务需要定期将这部分海量数据导入HBase系统,以执行随机查询更新操作。这种场景如果调用写入API进行处理,极有可能会给RegionServer带来较大的写入压力: 引起RegionServer频繁f lush,进而不断compact、split,影响集群稳定性。引起RegionServer频繁GC,影响集群稳定性。消耗大量C
Hbase Bulkload 原理|面试必备
当需要大批量的向Hbase导入数据时,我们可以使用Hbase Bulkload的方式,这种方式是先生成Hbase的底层存储文件 HFile,然后直接将这些 HFile 移动到Hbase的存储目录下。它相比调用Hbase 的 put 接口添加数据,处理效率更快并且对Hbase 运行影响更小。 下面假设我们有一个 CSV 文件,是存储用户购买记录的。它一共有三列, order_id,consumer