buckets专题

Elasticsearch超强聚合函数(四) buckets的嵌套使用
Elasticsearch超强聚合函数(四) buckets的嵌套使用 案例:构建聚合以便按季度展示所有汽车品牌总销售额。同时按季度、按每个汽车品牌计算销售总额,以便可以找出哪种品牌最赚钱: http代码java-api返回结果 原始数据还是引用第一篇中的数据:ElasticSearch超强聚合查询(一) 案例:构建聚合以便按季度展示所有汽车品牌总销售额。同时按季度、按每个汽车品

Hive之分区(Partitions)和桶(Buckets)
hive引入partition和bucket的概念,中文翻译分别为分区和桶(我觉的不是很合适,但是网上基本都是这么翻译,暂时用这个吧),这两个概念都是把数据划分成块,分区是粗粒度的划分桶是细粒度的划分,这样做为了可以让查询发生在小范围的数据上以提高效率。 首先介绍分区的概念,还是先来个例子看下如果创建分区表: [code lang=”sql”] create table logs_parti
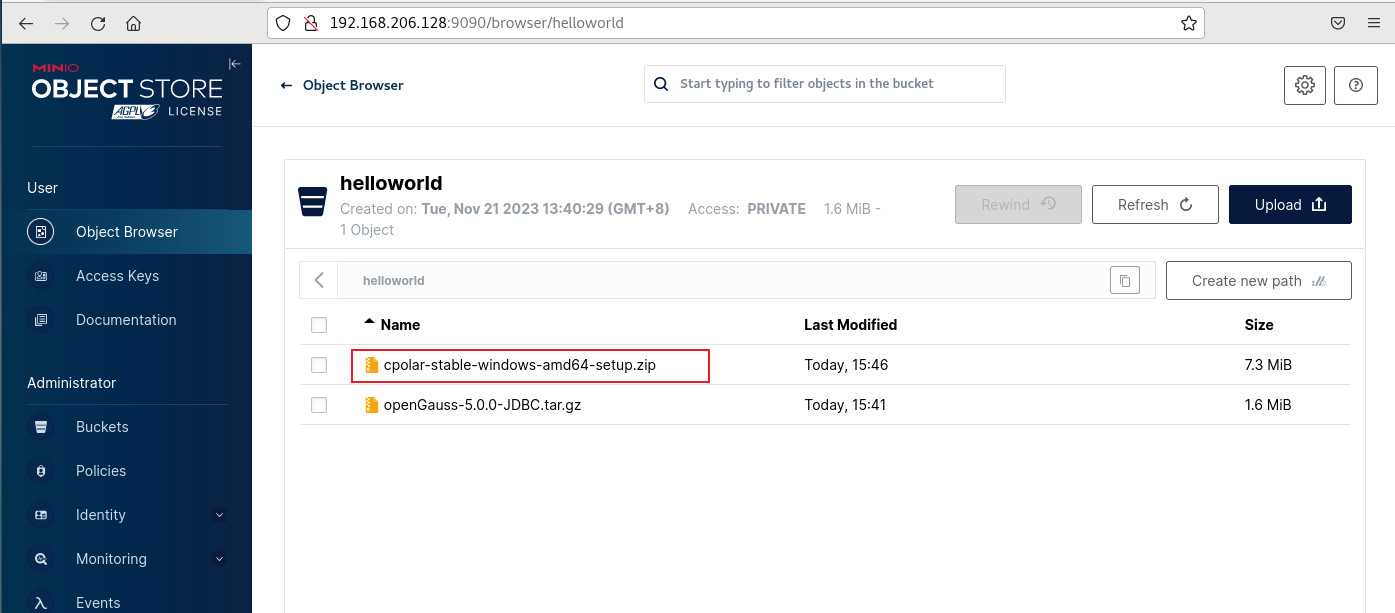
如何在MinIO存储服务中通过Buckets实现远程访问管理界面上传文件
文章目录 前言1. 创建Buckets和Access Keys2. Linux 安装Cpolar3. 创建连接MinIO服务公网地址4. 远程调用MinIO服务小结5. 固定连接TCP公网地址6. 固定地址连接测试 前言 MinIO是一款高性能、分布式的对象存储系统,它可以100%的运行在标准硬件上,即X86等低成本机器也能够很好的运行MinIO。它的优点包括高性能、高可用性、
本地MinIO存储服务如何创建Buckets并实现公网访问上传文件
文章目录 前言1. 创建Buckets和Access Keys2. Linux 安装Cpolar3. 创建连接MinIO服务公网地址4. 远程调用MinIO服务小结5. 固定连接TCP公网地址6. 固定地址连接测试 前言 MinIO是一款高性能、分布式的对象存储系统,它可以100%的运行在标准硬件上,即X86等低成本机器也能够很好的运行MinIO。它的优点包括高性能、高可用性、