bleu专题

python 笔记 geo-bleu
1 介绍 提供了两个针对每个用户ID的评估函数,calc_geobleu() 和 calc_dtw() 这两个函数接受基于用户ID的生成轨迹和参考轨迹作为参数,并分别给出 GEO-BLEU 的相似度值和 DTW 的距离值轨迹是由元组列表组成的,每个元组表示 (d, t, x, y) 或 (uid, d, t, x, y),并且在每个步骤中生成的和参考的日期和时间值必须相同在内部,这两个函数按天评

论文笔记:GEO-BLEU: Similarity Measure for Geospatial Sequences
22 sigspatial 1 intro 提出了一种空间轨迹相似性度量的方法比较了两种传统相似度度量的不足 DTW 基本特征是它完全对齐序列以进行测量,而不考虑它们之间共享的局部特征这适用于完全对齐的序列,但不适用于逐步对齐没有太多意义的序列BLEU 适用于不完全对齐的序列将序列中的地点视为单词,它们的连续组合视为地理空间𝑛-gram,应用这种方法基于局部特征评估地理空间轨迹的相似性然而,

论文阅读:《BLEU: a Method for Automatic Evaluation of Machine Translation》
https://blog.csdn.net/qq_21190081/article/details/53115580 论文地址:http://xueshu.baidu.com/s?wd=paperuri%3A%2888a98dec5bea94cca9f474db30c36319%29&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=
机器翻译常用指标BLEU
诸神缄默不语-个人CSDN博文目录 文章目录 什么是BLEU指标?BLEU指标的原理BLEU的计算公式BLEU指标的Python实现 什么是BLEU指标? BLEU(Bilingual Evaluation Understudy)指标是一种评估机器翻译质量的方法,广泛用于自然语言处理领域,特别是在机器翻译任务中。它通过计算机器翻译输出与人工翻译参考之间的相似度来评估翻译质量。B
【名词解释】ImageCaption任务中的CIDEr、n-gram、TF-IDF、BLEU、METEOR、ROUGE 分别是什么?它们是怎样计算的?
CIDEr CIDEr(Consensus-based Image Description Evaluation)是一种用于自动评估图像描述(image captioning)任务性能的指标。它主要通过计算生成的描述与一组参考描述之间的相似性来评估图像描述的质量。CIDEr的独特之处在于它考虑了人类对图像描述的共识,尝试捕捉描述的自然性和信息量。 CIDEr的计算过程 CIDEr的计算可以分
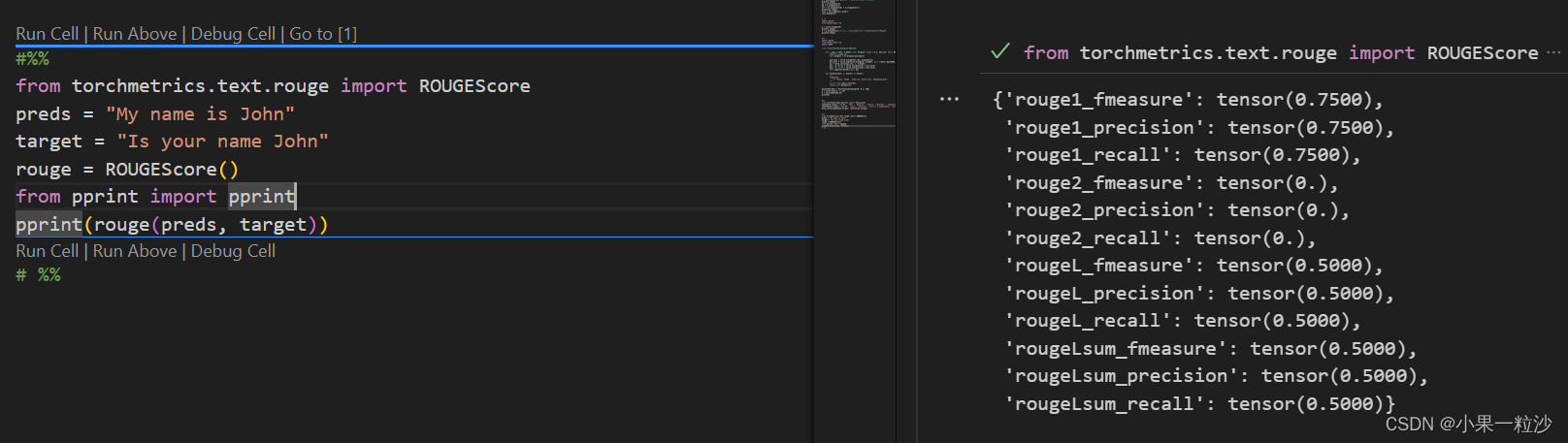
文本生成评估指标简单介绍BLEU+ROUGE+Perplexity+Meteor 代码实现
以下指标主要针对两种:机器翻译和文本生成(文章生成),这里的文本生成并非是总结摘要那类文本生成,仅仅是针对生成句子/词的评价。 首先介绍BLEU,ROUGE, 以及BLEU的改进版本METEOR;后半部分介绍PPL(简单介绍,主要是关于交叉熵的幂,至于这里的为什么要求平均,是因为我们想要计算在一个n-gram的n中,平均每个单词出现需要尝试的次数。 机器翻译(Machine Translatio

NLP 的 Task 和 Metric (Perplexity,BLEU,METOR,ROUGH,CIDEr)
Task 1. 信息检索IR(Information Retrieval) 信息检索(NLU)是指通过在大规模的文本库或数据库中搜索相关信息,将与用户查询匹配的文档或记录返回给用户。信息检索主要涉及到索引构建、查询处理和结果排序等技术,旨在帮助用户快速有效地获取所需的信息。 讲query和documents映射到同一个特征空间,进行相似度计算,避免传统IR中词汇和语义失配的问题。