beeline专题
Hive两代命令行客户端(Hive、Beeline)
Hive命令行客户端 Hive有两个主要的客户端工具,分别是旧版的Hive CLI(Command Line Interface)和新版的Beeline。 Hive CLI: Hive CLI 是 Hive 最早期的命令行客户端工具,它使用 JDBC 连接到 Hive 服务器,并提供了一个交互式的 shell 界面。在使用 Hive CLI 时,你可以直接在命令行中输入 HiveQL

hive启动beeline报错
问题一在zpark启动集群报错 出现上面的问题执行以下代码 chmod 777 /opt/apps/hadoop-3.2.1/logs 问题二启动beeline报错 执行 cd /opt/apps/hadoop-3.2.1 bin/hadoop dfsadmin -safemode leave 问题三执行查询语句报错 执行 set hive.exec.mode.loc


Ubuntu16.04 Docker安装Hive(使用mysql作为元数据库),以及beeline连接
本篇要做的事:基于上一篇使用docker搭建的spark集群安装一个hive。 Hive下载: wget https://mirrors.tuna.tsinghua.edu.cn/apache/hive/stable-2/apache-hive-2.3.3-bin.tar.gz Hive镜像创建 写一个dockerfile来安装hive: # 引用镜像FROM spark:v1#设置
1.8.5 大数据-Spark-SparkSql与Hive集成(spark-shell/spark-sql/beeline)
一、需要配置的项目 1.拷贝hive的配置文件hive-site.xml到spark的conf目录 记得检查hive-site.xml中metastore的url的 配置 <property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://bigdata-pro01.kfk.com/metastore?createD

用beeline连接SparkSQL
1. 在$SPARK_HOME/conf/hive-site.xml文件中添加下面的属性 vi $SPARK_HOME/conf/hive-site.xml <configuration> <property> <name>hive.metastore.uris</name> <value>thrift://master:9083</value>

使用beeline命令行访问Impala集群
Impala本身提供了两种接口进行访问:beeswax和hs2,其中beeswax是impala自己开发的api,而hs2是兼容hive的。由于beesswax的连接方式需要使用impala自己提供的python脚本,而且不支持HA,因此这里就不再多做介绍。本文主要介绍如何使用hive的beeline客户端来连接impala集群。目前我们内部的Impala集群都支持zk的高可用,来解决单点故障的问

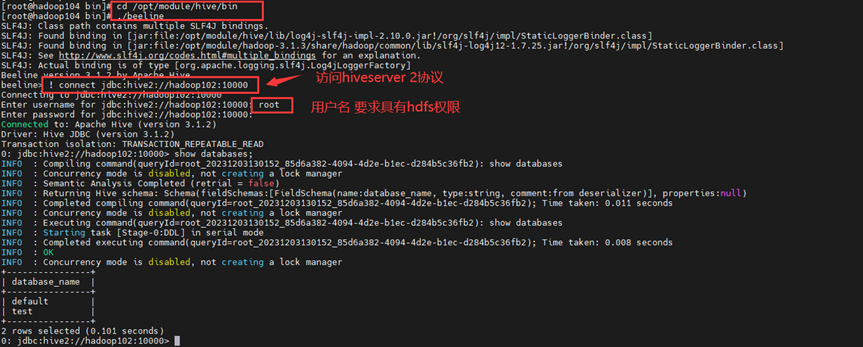
用 beeline -u jdbc:hive2://localhost:10000 连接hive 时候,其中数据库的表格里有中文的话会乱码(即是?),怎么解决这一问题?
首先需要找到hive-env.sh 其次vi hive-env.sh文件,进去之后在最后加上以下编码格式: export HADOOP_OPTS="$HADOOP_OPTS -Dfile.encoding=UTF-8" 最后重新启动hive 再连接测试即可 beeline -u jdbc:hive2://localhost:10000 发现再次查询表的时候就会出现中文了:
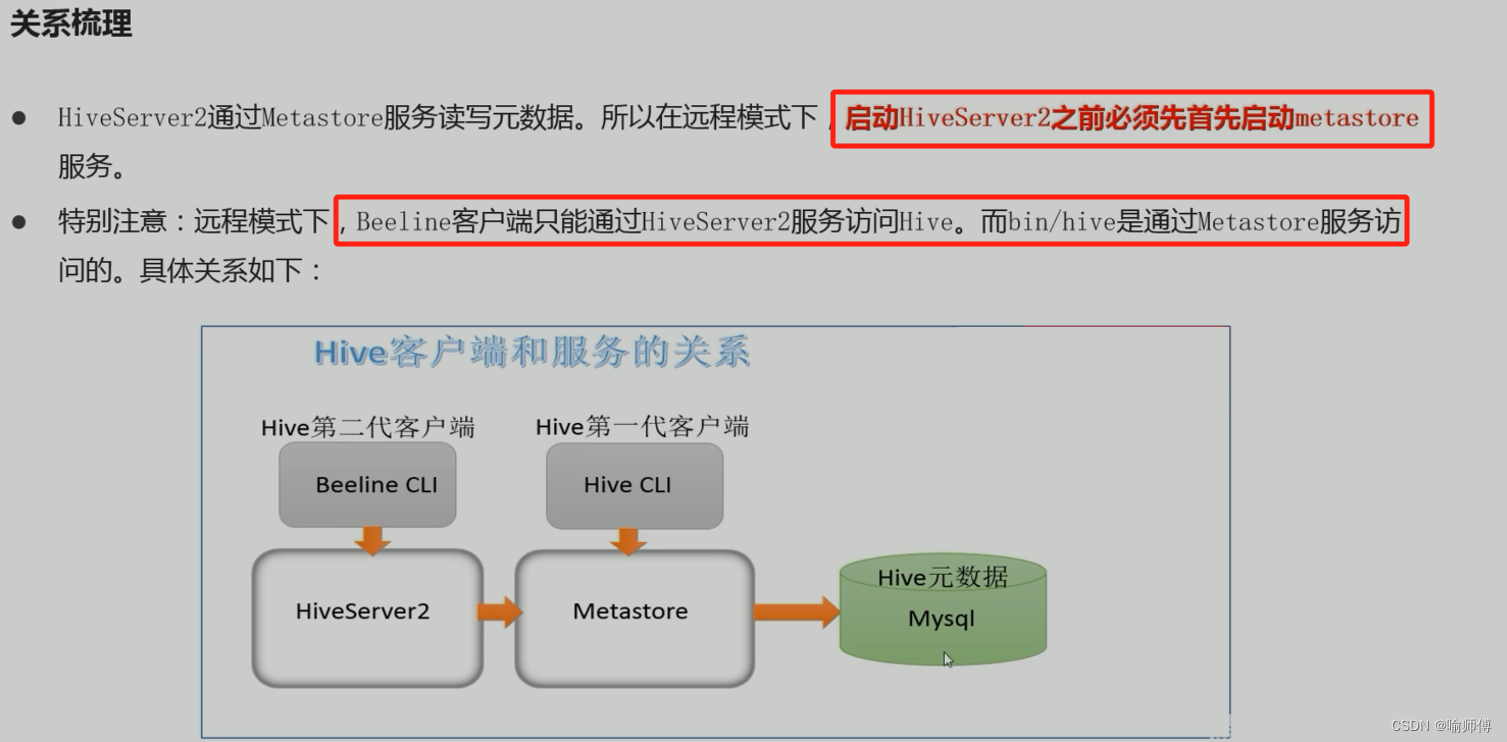
【Hive】——CLI客户端(bin/beeline,bin/hive)
1 HiveServer、HiveServer2 2 bin/hive 、bin/beeline 区别 3 bin/hive 客户端 hive-site.xml 配置远程 MateStore 地址 XML<?xml version="1.0" encoding="UTF-8" standalone="no"?><?xml-stylesheet type="text/xs
Hive数据类型支持以及Hive CLI、Beeline CLI使用
Hive数据类型支持以及Hive CLI、Beeline CLI使用 1 Hive的数据单元 Hive中的数据单元有: Databases 、Tables 、Partitions、Clusters(Buckets) Databases用来管理、区分不同的数据; Tables用来存放不同表的数据; Partition可以对Table中的数据进行分区; Cluster可以将不同的分区数据划分到
![[spark]解决beeline连接thrift-server加载数据权限问题](/front/images/it_default.jpg)
[spark]解决beeline连接thrift-server加载数据权限问题
1.如果期望spark的表存放到hive的hdfs中 需要在环境变量及conf/spark-env.sh中配置 HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop 2.如果期望用beeline连接thrift-server时不报权限错误 需要在环境变量及conf/spark-env.sh中配置 HADOOP_USER_NAME=有hdf

hivecontex释放mysql连接_通过beeline连接到hive时,自动关闭连接了
这个server2的log ... 41 more 2016-05-05 08:36:02,911 WARN [main]: hive.metastore (HiveMetaStoreClient.java:open(439)) - set_ugi() not successful, Likely cause: new client talking to old server. Continu