bca0a4127a4128a4141专题
spider小案例~https://industry.cfi.cn/BCA0A4127A4128A4141.html
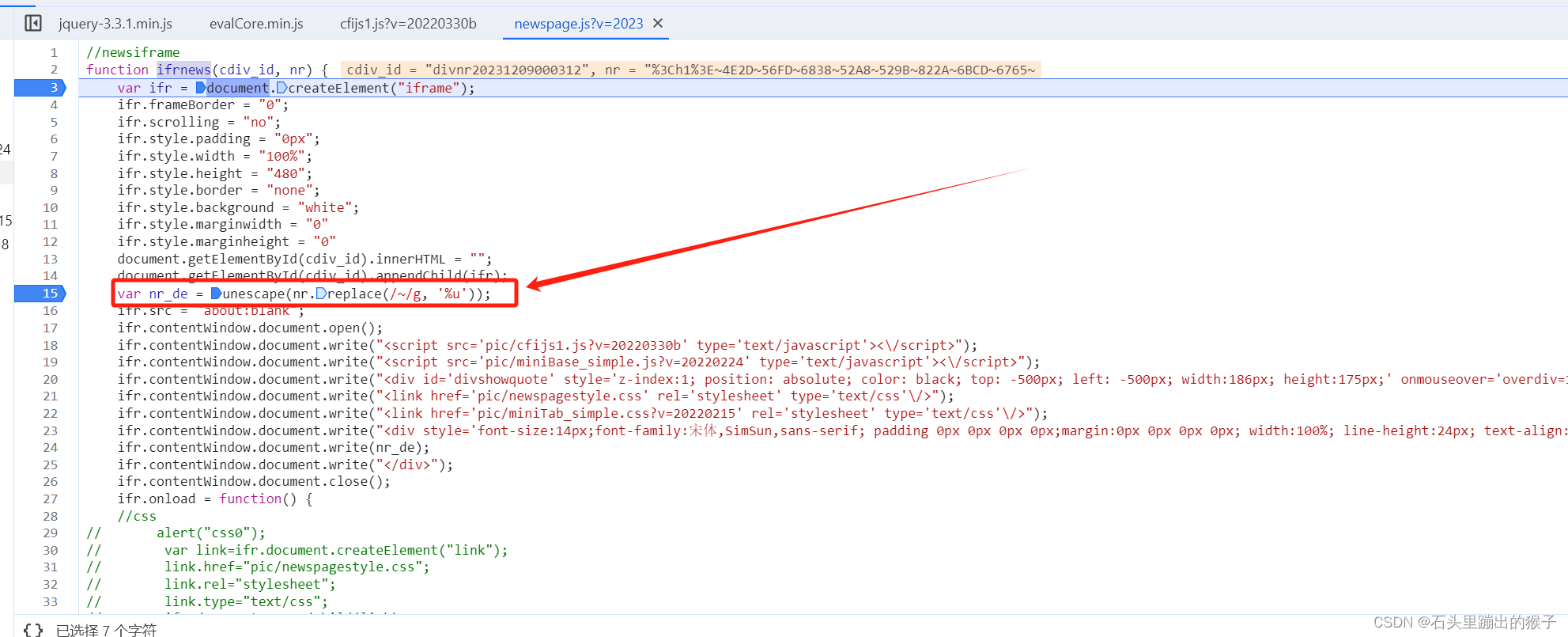
一、获取列表页信息 通过抓包发现列表页信息非正常返回,列表信息如下图: 通过观察发现列表页信息是通过unes函数进行处理的,我们接下来去看下该函数 该函数是对列表页的信息先全局替换"~"为"%u",然后再通过unescape函数对替换后的字符串进行解码,到此我们就可以获取到列表页的信息了,我们用Python来还原一下 import refrom urllib.parse