本文主要是介绍力扣652. 寻找重复的子树,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Problem: 652. 寻找重复的子树
文章目录
- 题目描述
- 思路
- 复杂度
- Code
题目描述
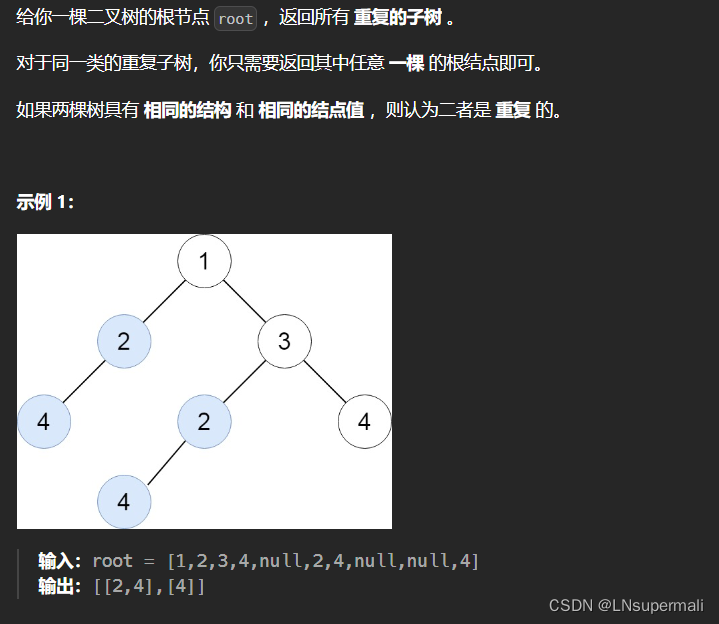
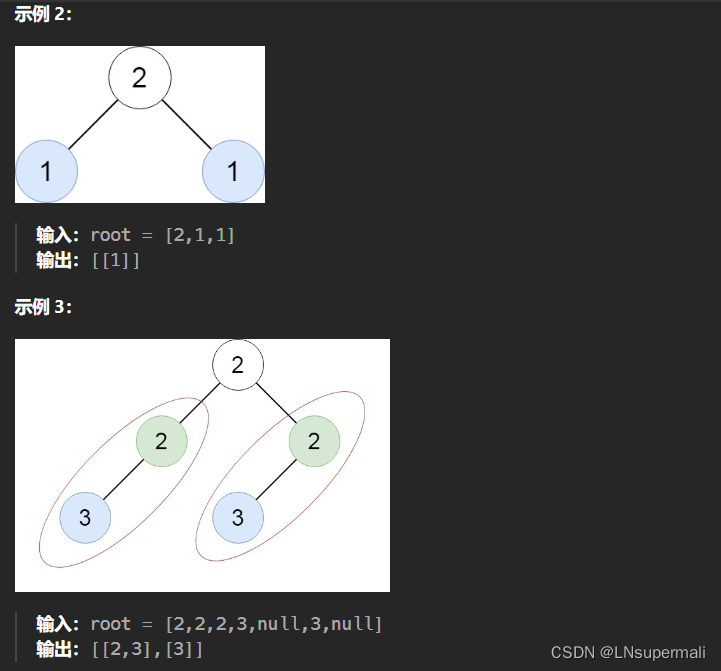

思路
1.利用二叉树的后序遍历将原始的二叉树序列化(之所以利用后序遍历是因为其在归的过程中是会携带左右子树的节点信息,而这些节点信息正是该解法要利用的东西);
2.在一个哈希表中存储每一个序列化后子树和其出现的次数(初始时设为出现0次,每当有一次重复就将其次数加一);
3.将哈希表中出现次数大于等于1的子树的节点添加到一个结果集合中
复杂度
时间复杂度:
O ( n ) O(n) O(n);其中 n n n二叉树中节点的个数
空间复杂度:
O ( n ) O(n) O(n)
Code
/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val = val; }* TreeNode(int val, TreeNode left, TreeNode right) {* this.val = val;* this.left = left;* this.right = right;* }* }*/
class Solution {// Record all subtrees and the number of occurrencesMap<String, Integer> memo = new HashMap<>();// Record duplicate child root nodesList<TreeNode> res = new LinkedList<>();/*** Find Duplicate Subtrees** @param root The root of binary tree* @return List<TreeNode>*/public List<TreeNode> findDuplicateSubtrees(TreeNode root) {traverse(root);return res;}/*** Find Duplicate Subtrees(Implementation function)** @param root The root of binary tree* @return String*/private String traverse(TreeNode root) {if (root == null) {return "#";}String left = traverse(root.left);String right = traverse(root.right);String subTree = left + "," + right + "," + root.val;int freq = memo.getOrDefault(subTree, 0);// Multiple repetitions will only be added to the result set onceif (freq == 1) {res.add(root);}// Add one to the number of// occurrences corresponding to the subtreememo.put(subTree, freq + 1);return subTree;}
}
这篇关于力扣652. 寻找重复的子树的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







