本文主要是介绍理解 Hologres 和 MaxCompute 的关系,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
理解了 Hologres 和 MaxCompute 的关系,就理解了数据仓库(DW)和数据服务(Serving)之间的关系,也有助于理解实时数仓和离线数仓之间的关系。
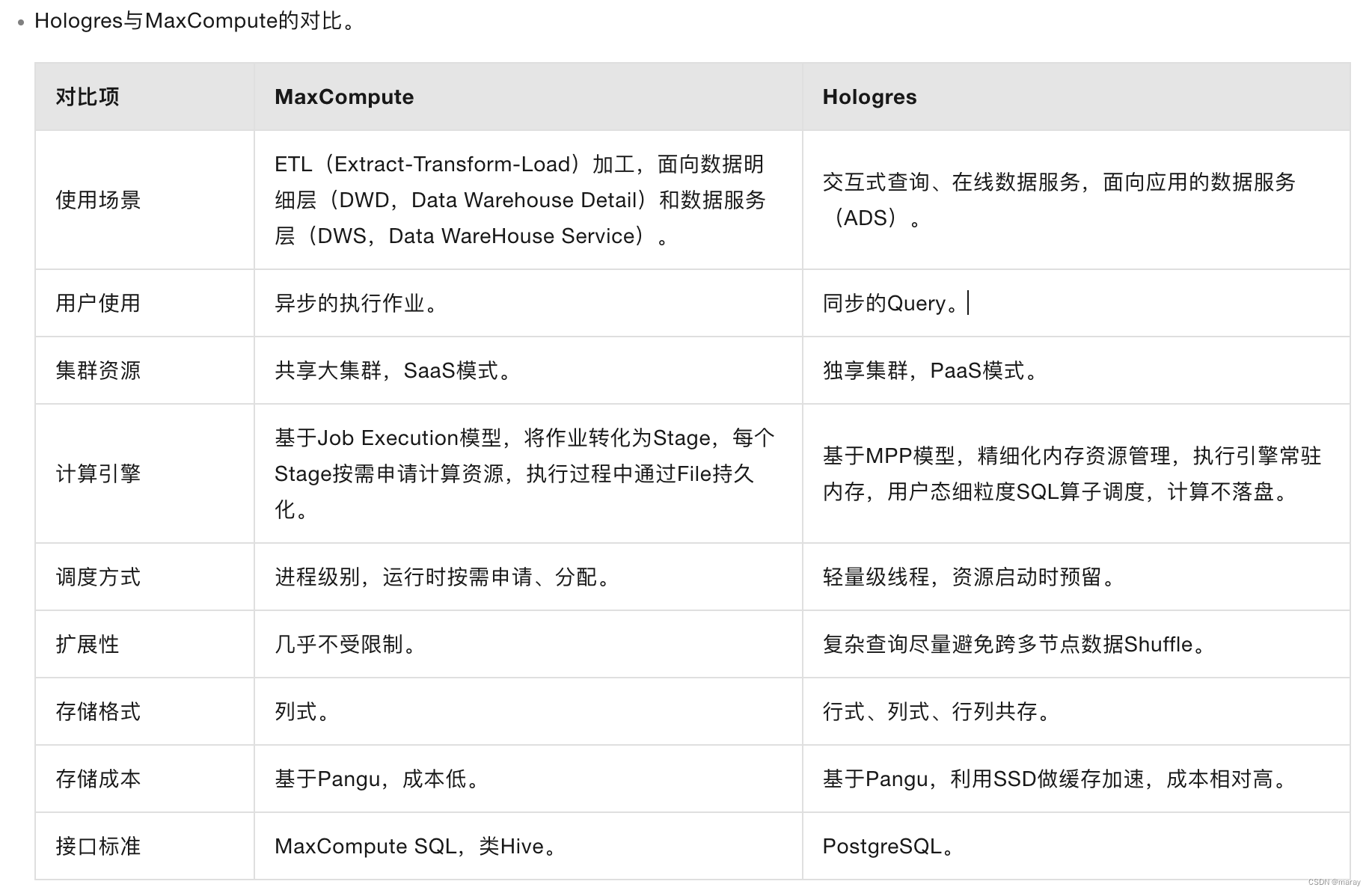
图片来源:阿里云官方帮助文档
可以看到,MaxCompute 和 Hologres 是一种互补的关系:
- MaxCompute 负责做超重的 ETL 操作,大数据进、大数据出的场景。
- Hologres 基于MaxCompute 的结果做在线服务,大数据进,小数据出的场景。例如在线聚合查询、点查、简单的在线 join 等。MaxCompute 的结果数据,既可以是直接导出给 Hologres,也可以是以外表的形式直接提供给 Hologres 读取。
为什么要引入 MaxCompute 和 Hologres 两套系统配合来做 OLAP 呢?能否一套数据库就搞定所有?比如用 OceanBase。
回答这个问题之前,我们再看 MaxCompute 和 Hologres 的一个区别:存储成本。
- MaxCompute 基于 Pangu 存储(Pangu 1.0 用的是 HDD磁盘,2.0 用的是ESSD)
- Hologres 标准存储即全SSD热存储,是Hologres的默认存储,满足低延时、高性能访问数据需求,对于大多数使用场景而言,标准存储是最有效且最具成本效益的选择,简称为热存。低频访问存储即全HDD冷存,满足低频访问数据的低成本存储需求,适用于对延迟不敏感或不常访问的超大型数据集,简称为冷存。
可以看到,MaxCompute 可以拥有更低的存储成本,适合海量数据存储。
再看 MaxCompute 和 Hologres 的另一个区别:计算资源利用方式
- MaxCompute 的资源是池化的,理论上,既可以动用无限的资源来计算一个任务,以降低这个任务的延迟,也可以把多余资源分给更多的任务并发使用。
- Hologres 的资源是固定分配的,无论有无计算任务,这些资源都无法发挥出额外的效用,忙时排队,闲时浪费。
可以看到,MaxCompute 可以拥有更低的计算成本,适合海量数据计算。
低存储成本,低计算成本,这正好满足海量数据的数仓的成本需求。
那么,Hologres 的优势是什么呢?实时性。它可以让小规模的计算延迟更小,这正是 Serving 的性能需求。
所以,二者组合起来使用,充分发挥各自优势,能给用户创造最大化的价值。
再回到 OceanBase 的问题上来:
- 对于 OceanBase 4.3,OceanBase MPP 架构适合做 Serving 和小规模数据量的数仓,但并不适合处理 PB 级别以上的数据,没有成本优势。
- 对于 OceanBase 4.4,OceanBase 支持使用共享存储(S3/OSS)来存储数据,同时支持高性能的数据缓存,此时,存储成本会大幅度降低,能够存储 PB 级以上的数据了。但是,这个版本里,计算资源的扩展还会受到限制,计算成本依然没有优势。
- 对于 OceanBase 5.0,OceanBase 支持彻底的存算分离,存储和计算都支持独立地扩展,此时计算资源也具备池化的能力,计算成本可以降低。此时,OceanBase 开始具备挑战 MaxCompute + Hologres 的能力。
这篇关于理解 Hologres 和 MaxCompute 的关系的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






