本文主要是介绍Spring Cloud Alibaba-06-Sleuth链路追踪,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Lison <dreamlison@163.com>, v1.0.0, 2024.4.03
Spring Cloud Alibaba-06-Sleuth链路追踪
文章目录
- Spring Cloud Alibaba-06-Sleuth链路追踪
- 为什么使用链路追踪
- 常见链路追踪解决方案
- Sleuth概述
- 概述
- Sleuth术语
- Sleuth + Zipkin 原理
- Sleuth原理简述
- Zipkin 原理简述
- Sleuth快速上手
- Zipkin客户端集成
- Zipkin服务端安装(Docker方式持久化mysql、ES)
- 持久化MySql
- 持久化ES
- 集成
- 应用性能监控:通过 SkyWalking 实施链路追踪
- APM 与 SkyWalking
- Sleuth+Zipkin 与 SkyWalking 对比
- 部署 SkyWalking 服务端
- 安装 SkyWalking Java Agent
- 集成skywalking
- 使用探针方式启动
为什么使用链路追踪
随着业务发展,微服务的数量也会越来越多,某个服务出现问题,问题很难排查
【问题】
1、链路梳理难:无法清晰地看到整个调用链路
2、故障难定位:无法快速定位到故障点、无法快速定位哪个环节比较费时
因此,我们需要链路追踪来梳理链路调用,方便快速定位问题。分布式链路追踪(Distributed Tracing),就是将一次分布式请求还原成调用链路,进行日志记 录,性能监控并将一次分布式请求的调用情况集中展示。比如各个服务节点上的耗时、请求具体到达哪 台机器上、每个服务节点的请求状态等等
常见链路追踪解决方案
常见的有如下几种解决方案,本文讲解跟SpringCloud相关的Sleuth + Zipkin
【Zipkin】
Twitter开源的调用链分析工具,目前基于springcloud sleuth得到了广泛的使用,特点是轻量,使用部署简单
【Pinpoint】
韩国人开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件,U功能强大,接入端无代码侵入。
【SkyWalking】
本土开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件,UI功能较强,接入端无代码侵入。目前已加入Apache孵化器。
【CAT】
是大众点评开源的基于编码和配置的调用链分析,应用监控分析,日志采集,监控报警等一系列的监控平台工具。
Sleuth概述
概述
sleuth是一个链路追踪工具,通过它在日志中打印的信息可以分析出一个服务的调用链条,也可以得出链条中每个服务的耗时,这为我们在实际生产中,分析超时服务,分析服务调用关系,做服务治理提供帮助。
sleuth目前并不是对所有调用访问都可以做链路追踪,它目前支持的有:rxjava、feign、quartz、RestTemplate、zuul、hystrix、grpc、kafka、Opentracing、redis、Reator、circuitbreaker、spring的Scheduled。国内用的比较多的dubbo,sleuth无法对其提供支持。
Sleuth术语
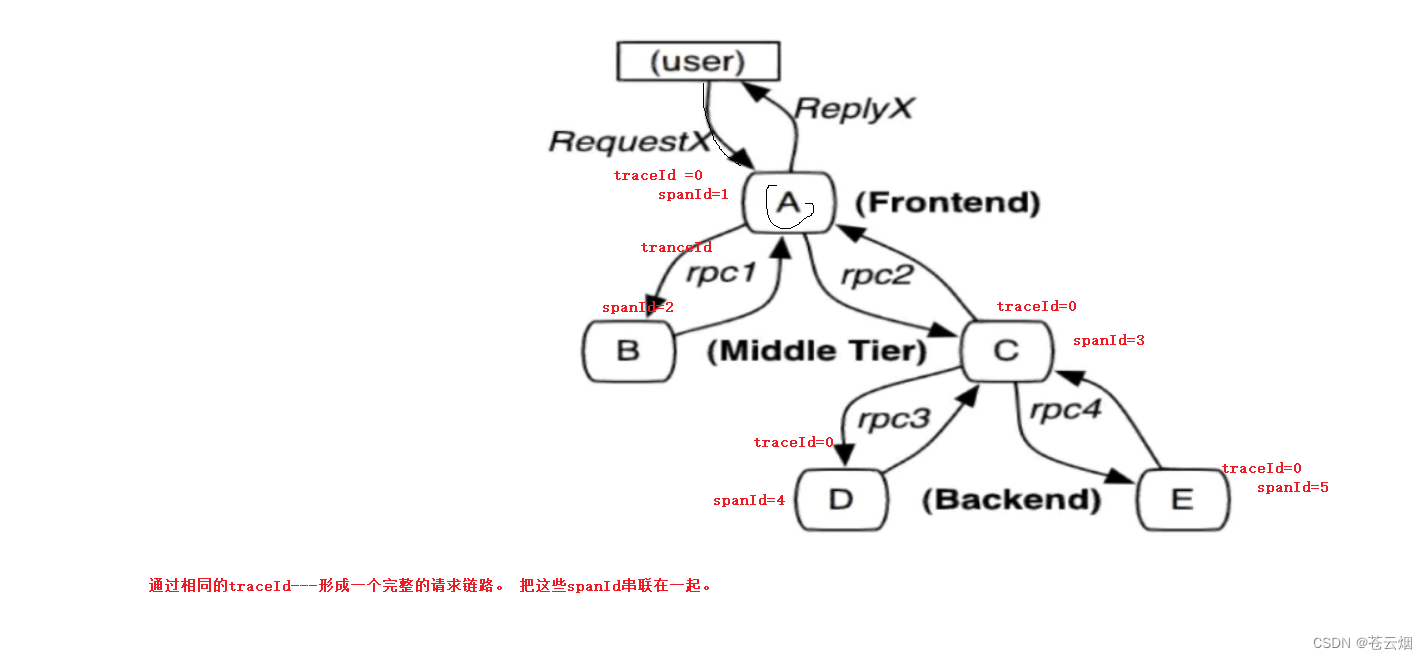
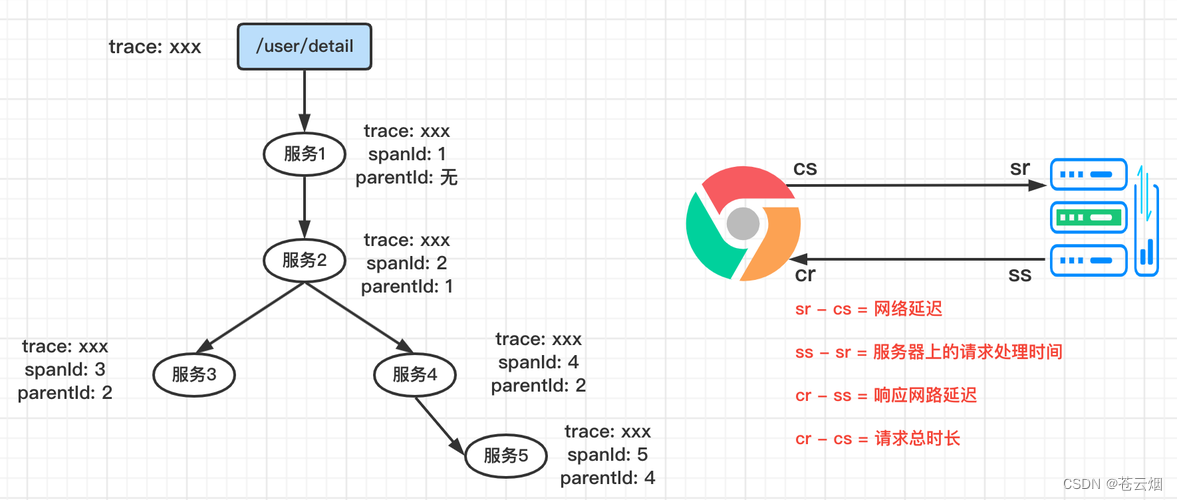
请求一个微服务系统的API接口,这个API接口需要调用多个微服务单元,调用每个微服务单元都会产生一个新的Span,所有由这个请求产生的Span组成了这个Trace。整个过程使用Annotation(cs、sr、ss、cr)统计各个阶段消耗的时长
-
Span
Span是基本工作单位。Span还包含了其他的信息,例如摘要、时间戳事件、Span的ID以及进程ID。SpanId用于唯一标识请求链路到达的各个服务组件。
-
Trace
由一组具有相同TraceId的span组成的树状结构,即一个完整的请求链路
-
Annotation
记录一个请求的4个事件,用于计算各个环节消耗的时长
- cs (Client Sent ):客户端发送一个请求,开始一个请求的生命。
- sr (Server Received ):服务端收到请求开始处理,sr - cs = 网络延迟(服务调用的时间)
- ss(Server Sent ):服务端处理完毕准备发送到客户端,ss - sr = 服务器处理请求所用时间
- cr (Client Received ):客户端接收到服务端的响应,请求结束,cr - cs = 请求的总时间
Sleuth + Zipkin 原理
Sleuth原理简述
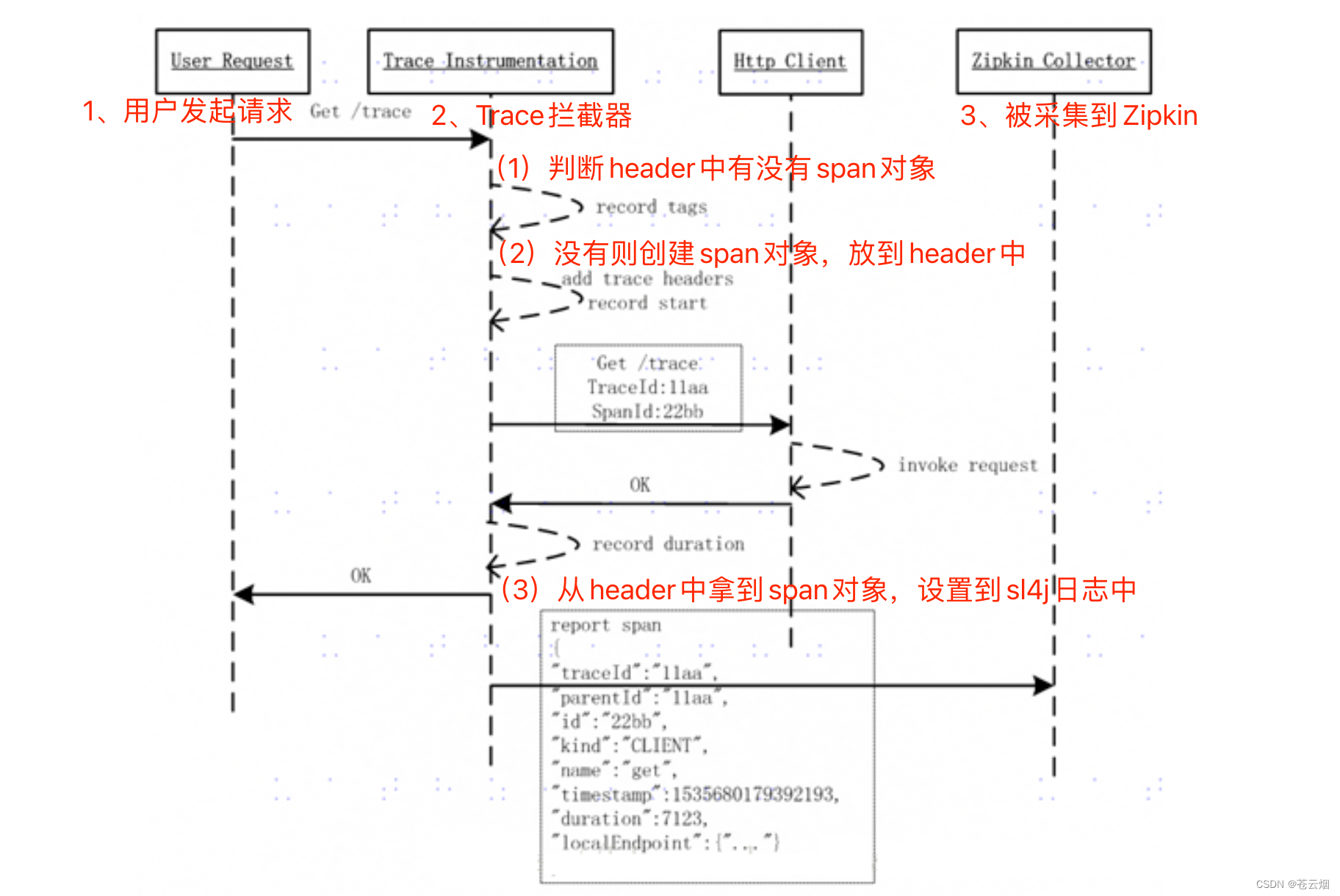
【AOP拦截器的思想】
Sleuth创建TraceFilter,对所有的网络请求进行拦截,如果请求的header中没有span信息,则创建Span对象,生成span id、trace id等当前调用链的Trace信息记录到Http Headers中,如果header中有,则直接使用header中的数据创建Span对象,之后将span id、trace id设置到sl4j的MDC中。这样,我们在日志中就能看到span信息。
我们通过日志看到的信息其实只是sleuth收集信息的一小部分,在运行过程中,sleuth还会收集服务调用时间、接收到请求的时间、发起http请求的方法、http请求的路径,包括请求的IP端口等信息,这些信息都会存入Span对象,然后发送到zipkin中。
Zipkin 原理简述
Zipkin 是 Twitter 的一个开源项目,它基于Google Dapper实现,它致力于收集服务的定时数据, 以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。
我们可以使用它来收集各个服务器上请求链路的跟踪数据,并通过它提供的REST API接口来辅助我 们查询跟踪数据以实现对分布式系统的监控程序,从而及时地发现系统中出现的延迟升高问题并找出系 统性能瓶颈的根源。
除了面向开发的 API 接口之外,它也提供了方便的UI组件来帮助我们直观的搜索跟踪信息和分析请 求链路明细,比如:可以查询某段时间内各用户请求的处理时间等。
Zipkin 提供了可插拔数据存储方式:In-Memory、MySql、Cassandra 以及 Elasticsearch
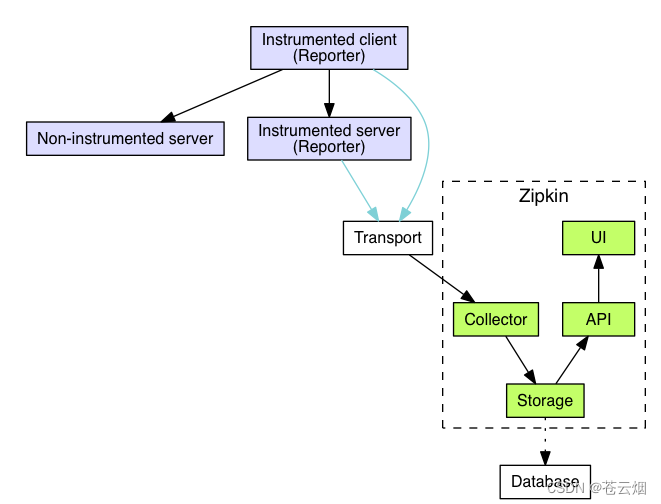
上图展示了 Zipkin 的基础架构,它主要由 4 个核心组件构成:
Collector:收集器组件,它主要用于处理从外部系统发送过来的跟踪信息,将这些信息转换为 Zipkin内部处理的 Span 格式,以支持后续的存储、分析、展示等功能。
Storage:存储组件,它主要对处理收集器接收到的跟踪信息,默认会将这些信息存储在内存中, 我们也可以修改此存储策略,通过使用其他存储组件将跟踪信息存储到数据库中。
RESTful API:API 组件,它主要用来提供外部访问接口。比如给客户端展示跟踪信息,或是外接 系统访问以实现监控等。
Web UI:UI 组件, 基于API组件实现的上层应用。通过UI组件用户可以方便而有直观地查询和分 析跟踪信息。
Zipkin分为两端,一个是 Zipkin服务端,一个是 Zipkin客户端,客户端也就是微服务的应用。 客户端会 配置服务端的 URL 地址,一旦发生服务间的调用的时候,会被配置在微服务里面的 Sleuth 的监听器监 听,并生成相应的 Trace 和 Span 信息发送给服务端。
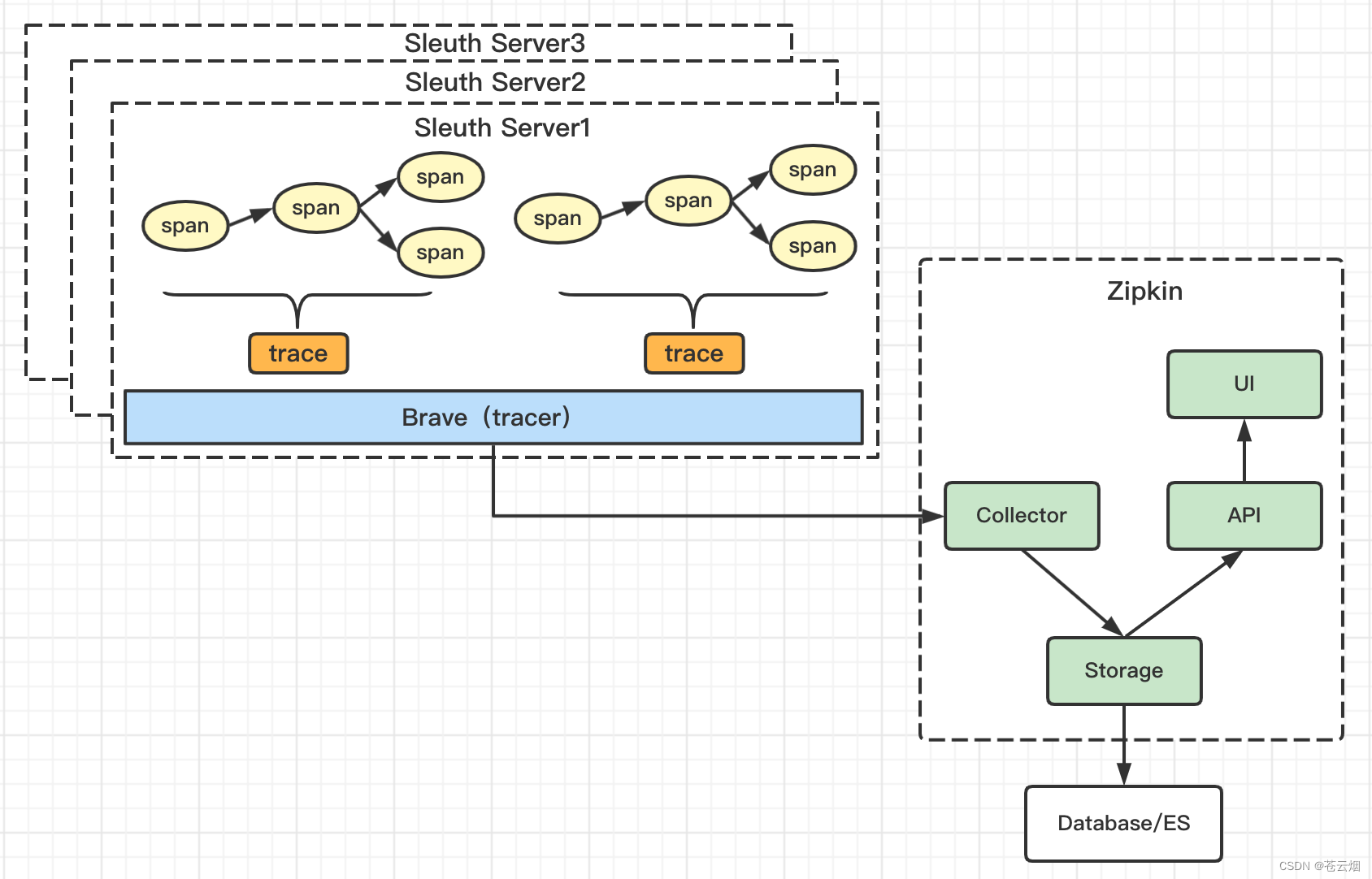
【原理】
1、Sleuth采用Brave(trancer库)追踪采集trace(由一组包含span信息的调用链组成)
2、将信息通过Zipkin的Collector发送给Zipkin
3、zipkin拿到信息后,将数据通过Storage持久化到数据库/es中
3、Zipkin通过API提供数据给UI进行可视化展示
Sleuth快速上手
1、在需要追踪的微服务上添加依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
2、编写配置
sleuth: sampler:rate: 100 # 指定采样比例,默认10%
3、增加测试接口
@RequestMapping("/sentinel/message1")public String message1() {testSentinelMessage3Service.message();log.info("这是message1");return "message1";}
调用接口时,输出以下日志:
2024-01-01 20:23:39.527 INFO [spring-cloud-service,9d701f5350d96c82,9d701f5350d96c82,true] 85218 --- [io-18001-exec-1] c.l.s.controller.TestSentinelController : 这是message1可以看到,日志里出现了[spring-cloud-service,9d701f5350d96c82,9d701f5350d96c82,true]信息,这个就是由Spring Cloud Sleuth生成,用于跟踪微服务请求链路。
这些信息包含了4个部分的值,它们的含义如下:
1、spring-cloud-service 微服务的名称,与spring.application.name对应;
2、9d701f5350d96c82 称为Trace ID,在一条完整的请求链路中,这个值是固定的。观察上面的日志即可证实这一点;
3、9d701f5350d96c82 称为Span ID,它表示一个基本的工作单元;
4、true表示是否要将该信息输出到Zipkin等服务中来收集和展示
Zipkin客户端集成
虽然我们已经可以通过Trace ID来跟踪整体请求链路了,但是我们还是得去各个系统中捞取日志。在并发较高得时候,日志是海量的,这个时候我们可以借助Zipkin来代替我们完成日志获取与分析。Zipkin是Twitter的一个开源项目。
ZipKin客户端和Sleuth的集成非常简单,只需要在微服务中添加其依赖和配置即可。
Zipkin服务端安装(Docker方式持久化mysql、ES)
持久化MySql
1、创建数据库
如zipkin
2、建表
语句参考:https://github.com/openzipkin/zipkin/blob/master/zipkin-storage/mysql-v1/src/main/resources/mysql.sql
或复制以下建表语句
--
-- Copyright The OpenZipkin Authors
-- SPDX-License-Identifier: Apache-2.0
--CREATE TABLE IF NOT EXISTS zipkin_spans (`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',`trace_id` BIGINT NOT NULL,`id` BIGINT NOT NULL,`name` VARCHAR(255) NOT NULL,`remote_service_name` VARCHAR(255),`parent_id` BIGINT,`debug` BIT(1),`start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL',`duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query',PRIMARY KEY (`trace_id_high`, `trace_id`, `id`)
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds';
ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames';
ALTER TABLE zipkin_spans ADD INDEX(`remote_service_name`) COMMENT 'for getTraces and getRemoteServiceNames';
ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range';CREATE TABLE IF NOT EXISTS zipkin_annotations (`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',`trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id',`span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id',`a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1',`a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB',`a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation',`a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp',`endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null',`endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address',`endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null',`endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds';
ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames';
ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces and autocomplete values';
ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces and autocomplete values';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'for dependencies job';CREATE TABLE IF NOT EXISTS zipkin_dependencies (`day` DATE NOT NULL,`parent` VARCHAR(255) NOT NULL,`child` VARCHAR(255) NOT NULL,`call_count` BIGINT,`error_count` BIGINT,PRIMARY KEY (`day`, `parent`, `child`)
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
3、修改启动命令
Zipkin默认端口9411。
docker run \
--name zipkin-server -d \
--restart=always \
-p 9411:9411 \
-e MYSQL_USER=root \
-e MYSQL_PASS=123456 \
-e MYSQL_HOST=127.0.0.1 \
-e STORAGE_TYPE=mysql \
-e MYSQL_DB=zipkin \
-e MYSQL_TCP_PORT=3306 \
openzipkin/zipkin:2.21.7
持久化ES
若连接ES集群,–ES_HOSTS通过逗号分割,如:–ES_HOSTS=[http://192.168.0.1:9200,http://192.168.0.2:9200]
docker run \
--name zipkin-server -d \
-p 9411:9411 \
--restart=always \
-e STORAGE_TYPE=elasticsearch \
-e ES_HOSTS=localhost:9200
openzipkin/zipkin:2.21.7
连接ES参数
| 环境变量 | 描述 |
|---|---|
| ES_HOSTS | 连接ES地址,多个由逗号分隔。默认为http://localhost:9200 |
| ES_PIPELINE | 指定span被索引之前的pipeline |
| ES_TIMEOUT | 连接ES的超时时间,单位ms。默认为10000(10S) |
| ES_INDEX | Zipkin持久化所使用的索引。默认为zipkin |
| ES_DATE_SEPARATOR | Zipkin建立索引的日期分隔符。默认为- |
| ES_INDEX_SHARDS | 分片(shard)个数,默认为5个 |
| ES_INDEX_REPLICAS | 副本(replica)个数,默认为1个 |
| ES_HTTP_LOGGING | ES的日志级别,可选值为BASIC, HEADERS, BODY |
| ES_USERNAME/ES_PASSWORD | 登录ES的用户名和密码 |
集成
1、在需要追踪的微服务上添加依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>2、编写配置
spring:zipkin:base-url: http://127.0.0.1:9411/ #zipkin server的请求地址 discoveryClientEnabled: false #让nacos把它当成一个URL,而不要当做服务名 sleuth: sampler:probability: 1.0 #采样的百分比 3、访问微服务
http://127.0.0.1:18003/spring_building/naocs/consumer
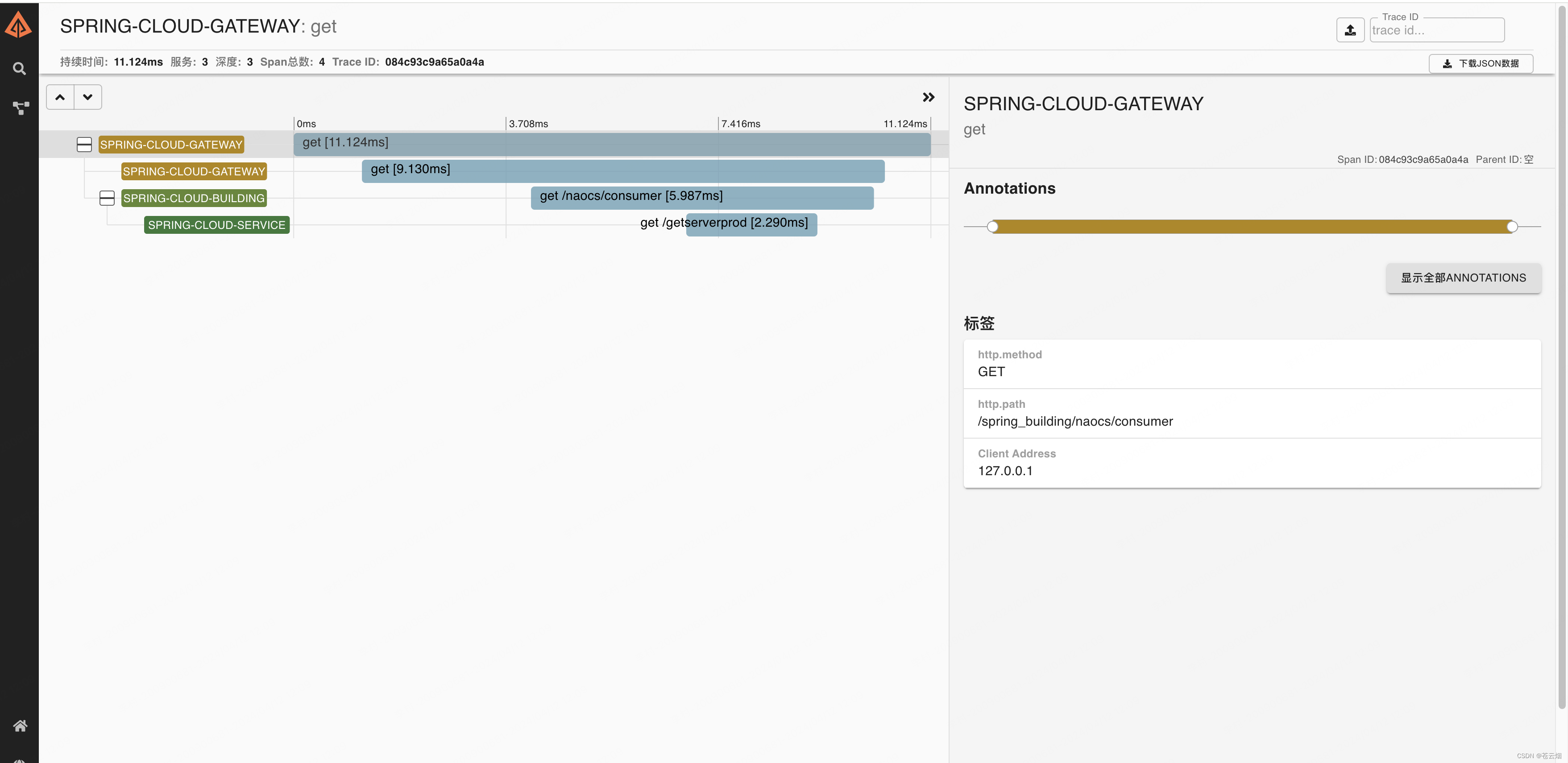
4、访问zipkin的UI界面,观察效果
应用性能监控:通过 SkyWalking 实施链路追踪
我们掌握了基于 Sleuth+Zipkin 对微服务架构实施基于日志的链路追踪,通过 Sleuth 在微服务应用中附加链路数据,再通过 Zipkin 实现链路数据收集与可视化,从而保证开发与运维人员在生产环境了解微服务的执行过程与具体细节,为产品运维提供了有力的保障。
围绕链路追踪这个话题,介绍另一款著名的链路追踪产品 SkyWalking,掌握 SkyWalking 的使用方法。本讲咱们将介绍三方面内容:
APM 与 SkyWalking
Spring Cloud Slueth、Zipkin、阿里鹰眼、大众点评 Cat、SkyWalking,这些产品都有一个共同的名字:APM(Application Performance Management),即应用性能管理系统,SkyWalking 这款 APM 产品,理由很简单,它在简单易用的前提下实现了比 Zipkin 功能更强大的链路追踪、同时拥有更加友好、更详细的监控项,并能自动生成可视化图表。相比 Sleuth+Zipkin 这种不同厂商间混搭组合,SkyWalking 更符合国内软件业的“一站式解决方案”的设计理念。
SkyWalking 是中国人吴晟(华为)开源的应用性能管理系统(APM)工具,使用Java语言开发,后来吴晟将其贡献给 Apache,在 Apache 的背书下 SkyWalking 发展迅速,现在已属于 Apache 旗下顶级开源项目,它的官网:http://skywalking.apache.org/。
SkyWalking 提供了分布式追踪、服务网格遥测分析、度量聚合和可视化一体化解决方案。目前在 GitHub 上 SkyWaking 拥有 23.3K Star,最新版本为:9.7.0
链路追踪视图
指标监控全局视图
Sleuth+Zipkin 与 SkyWalking 对比
| Sleuth+Zipkin | SkyWalking | |
|---|---|---|
| 链路追踪可视化 | 有 | 有 |
| 聚合报表 | 很少 | 丰富 |
| 服务依赖图 | 简单依赖图展示 | 形象直观 |
| 监控埋点方式 | 侵入式,需要修改源码 | 无侵入,采用Java Agent字节码增强 |
| Java VM指标监控 | 不具备 | 具备 |
| 支持报警 | 不支持 | 有,可以自定义报警方式 |
| 存储机制 | 内存、MySQL,ES… | ES、Mysql、H2… |
| 文档支持 | 文档丰富,国外主流 | Apache支持,国内文档更新滞后 |
| 国内案例 | 京东、阿里定制不开源… | 华为、小米、微众银行… |
通过比较我们可以发现,在易用性和使用体验上,SkyWalking 明显好于 Zipkin,功能更丰富的同时也更符合国人习惯,但因为迭代速度较快,社区文档相对陈旧,这也导致很多技术问题需要程序员自己研究解决,因此在解决问题方面需要更多的时间。
部署 SkyWalking 服务端
skyWalkIng 架构图
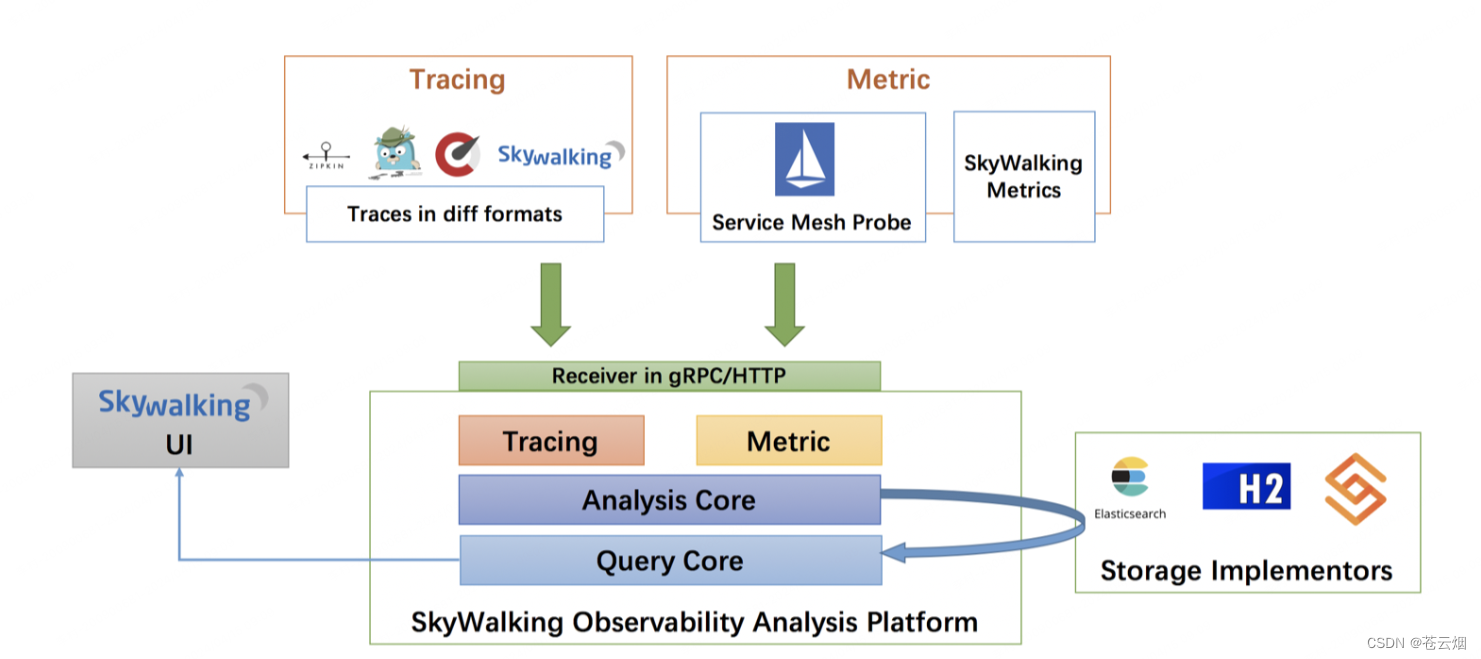
SkyWalking 同样采用客户端与服务端架构模式,SkyWalking 服务端用于接收来自 Java Agent 客户端发来的链路跟踪与指标数据,汇总统计后由 SkyWalking UI 负责展现。SkyWalking 服务端同时支持 gRPC 与 HTTP 两种上报方式。其中 gRPC 默认监听服务器 11800 端口,HTTP 默认监听 12800 端口,而 SKyWalking UI 应用则默认监听 8080 端口,这三个端口在生产环境下要在防火墙做放行配置。在存储层面,SkyWalking 底层支持 ElasticSearch 、MySQL、H2等多种数据源,官方优先推荐使用 ElasticSearch
本初采用Docker的安装方式
version: '3.8'
services:elasticsearch:image: docker.elastic.co/elasticsearch/elasticsearch:7.17.6container_name: elasticsearchrestart: alwaysports:- 9200:9200- 9300:9300environment:- discovery.type=single-node- TZ=Asia/Shanghai- bootstrap.memory_lock=true- "ES_JAVA_OPTS=-Xms1024m -Xmx1024m"volumes:- /opt/data/dockerData/skywalking/elasticsearch/data:/usr/share/elasticsearch/dataulimits:memlock:soft: -1hard: -1oap:image: docker.io/apache/skywalking-oap-server:9.4.0container_name: oapdepends_on:- elasticsearchrestart: alwaysports:- 11800:11800- 12800:12800environment:SW_CORE_RECORD_DATA_TTL: 15SW_CORE_METRICS_DATA_TTL: 15SW_STORAGE: elasticsearchSW_STORAGE_ES_CLUSTER_NODES: elasticsearch:9200SW_ENABLE_UPDATE_UI_TEMPLATE: trueTZ: Asia/ShanghaiJAVA_OPTS: "-Xms2048m -Xmx2048m"ui:image: docker.io/apache/skywalking-ui:9.4.0container_name: uidepends_on:- oaplinks:- oaprestart: alwaysports:- 8080:8080environment:SW_OAP_ADDRESS: http://oap:12800SW_ZIPKIN_ADDRESS: http://oap:9412docker compose up -d
启动后会产生两个 Java 进程:
- Skywalking-Collector 是数据收集服务,默认监听 11800(gRPC)与 12800(HTTP) 端口。
- Skywalking-Webapp 是 SkyWalking UI,用于展示数据,默认监听 8080 端口,上面显示的为8038。
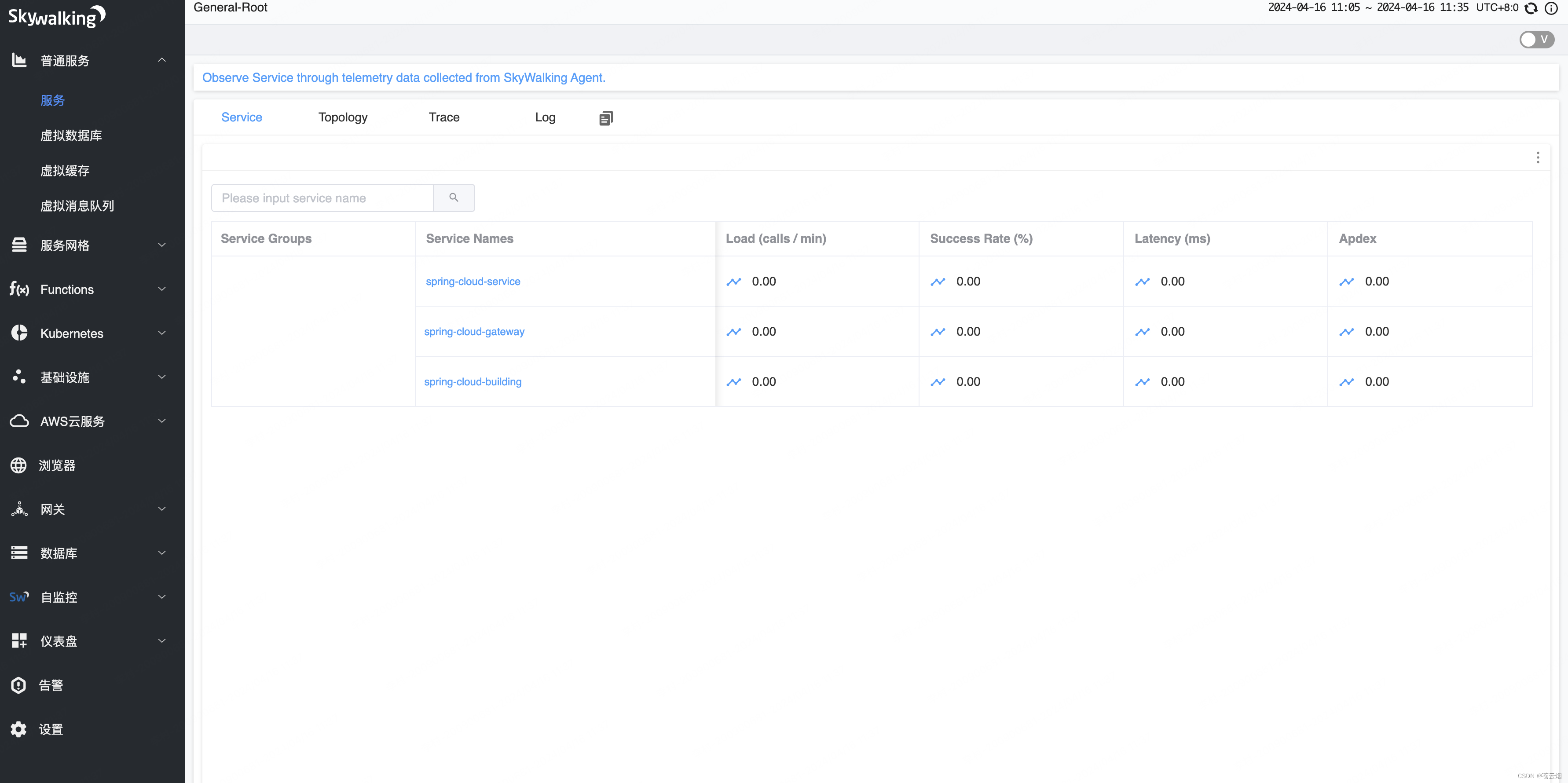
Skywalking 应用已启动
启动成功后,访问[http://127.0.0.1:8088/],如果看到 SkyWalking UI 首页,则说明服务端配置成功。
安装 SkyWalking Java Agent
在前面提到,SkyWalking 可以在不修改应用源码的前提下,无侵入的实现链路追踪与 JVM 指标监控,它是怎么做到的?这里涉及一个 Java1.5 新增的特性,Java Agent 探针技术,想必对于很多工作多年 Java 工程师来说,Java Agent 也是一个陌生的东西。
Java Agent 探针说白了就是 Java 提供的一种“外挂”技术,允许在应用开发的时候在通过启动时增加 javaagent 参数来外挂一些额外的程序。
Java Agent ,其扩展类有这严格的规范,必须创建名为 premain 的方法,该方法将在目标应用 main 方法前执行,下面就是最简单的 Java Agent 扩展类。
public class SimpleAgent {public static void premain(String agentArgs, Instrumentation inst) {System.out.println("=========开始执行premain============");}
}
要完成 Java Agent,还需要提供正确的 MANIFEST.MF,以便 JVM 能够选择正确的类。在 META-INF 目录下找到你的 MANIFEST.MF 文件:
Manifest-Version: 1.0
Premain-Class: com.lison.agent.SimpleAgent
之后我们将这个类打包为 agent.jar,假设原始应用为 test-agent.jar,在 test-agent.jar 启动时需要在额外附加 javaagent 参数,如下所示:
java -javaagent:agent.jar -jar test-agent.jar
在应用启动时 Java 控制台会输出如下日志。
=========开始执行 premain============
正在启动 Agent测试服务...
....
SkyWalking 也是利用 Java Agent 的特性,在 premain 中通过字节码增强技术对目标方法进行扩展,当目标方法执行时自动收集链路追踪及监控数据并发往 SkyWalking 服务端。
SkyWalking Java Agent,我们还是以实例进行讲解,因为 Java Agent 是无侵入的,并不需要源码,这里我就直接给出调用关系图帮助咱们理解。

调用关系图
简单介绍下,用户访问 a 服务的 a 接口,a 服务通过 OpenFeign 远程调用 b 服务的 b 接口,b 服务通过 OpenFeign 调用 c 服务的 c 接口,最后 c 接口通过 JDBC 将业务数据存储到 MySQL 数据库
集成skywalking
1、下载解压 agent
注意:agent版本和oap版本需要适配,版本不适配可能会出现页面无法访问、agent上报不到页面等问题。
下载地址: https://skywalking.apache.org/downloads/
作者用的skywalking版本为9.4.0,下载v9.1.0版本的client没有问题,亲测可用。
需要配置skywalking-agent文件夹下,config/agent.config配置文件,列出最关键的两个配置,其他配置大家可以自行探索。
agent.service_name=${SW_AGENT_NAME:HS}
collector.backend_service=${SW_AGENT_COLLECTOR_BACKEND_SERVICES:192.168.54.53:11800}2、日志对接
在skywalking的UI端有一个日志的模块,用于收集客户端的日志,默认是没有数据的,那么需要如何将日志数据传输到skywalking中呢?
<!--打印skywalking的TraceId到日志--><dependency><groupId>org.apache.skywalking</groupId><artifactId>apm-toolkit-logback-1.x</artifactId><version>9.1.0</version></dependency><dependency><groupId>org.apache.skywalking</groupId><artifactId>apm-toolkit-trace</artifactId><version>9.1.0</version></dependency>
新建一个logback-spring.xml放在resource目录下,配置如下:
<configuration debug="false" scan="false"><springProperty scop="context" name="spring.application.name" source="spring.application.name" defaultValue=""/><property name="log.path" value="logs/${spring.application.name}"/><!-- 彩色日志格式 --><property name="CONSOLE_LOG_PATTERN"value="${CONSOLE_LOG_PATTERN:-%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}}"/><!-- 彩色日志依赖的渲染类 --><conversionRule conversionWord="clr" converterClass="org.springframework.boot.logging.logback.ColorConverter"/><conversionRule conversionWord="wex"converterClass="org.springframework.boot.logging.logback.WhitespaceThrowableProxyConverter"/><conversionRule conversionWord="wEx"converterClass="org.springframework.boot.logging.logback.ExtendedWhitespaceThrowableProxyConverter"/><!-- Console log output --><appender name="console" class="ch.qos.logback.core.ConsoleAppender"><encoder><pattern>${CONSOLE_LOG_PATTERN}</pattern></encoder></appender><!-- Log file debug output --><appender name="debug" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>${log.path}/debug.log</file><rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><fileNamePattern>${log.path}/%d{yyyy-MM, aux}/debug.%d{yyyy-MM-dd}.%i.log.gz</fileNamePattern><maxFileSize>50MB</maxFileSize><maxHistory>30</maxHistory></rollingPolicy><encoder><pattern>%date [%thread] %-5level [%logger{50}] %file:%line - %msg%n</pattern></encoder></appender><!-- Log file error output --><appender name="error" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>${log.path}/error.log</file><rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><fileNamePattern>${log.path}/%d{yyyy-MM}/error.%d{yyyy-MM-dd}.%i.log.gz</fileNamePattern><maxFileSize>50MB</maxFileSize><maxHistory>30</maxHistory></rollingPolicy><encoder><pattern>%date [%thread] %-5level [%logger{50}] %file:%line - %msg%n</pattern></encoder><filter class="ch.qos.logback.classic.filter.ThresholdFilter"><level>ERROR</level></filter></appender><appender name="stdout" class="ch.qos.logback.core.ConsoleAppender"><encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder"><layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.TraceIdPatternLogbackLayout"><Pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%tid] [%thread] %-5level %logger{36} -%msg%n</Pattern></layout></encoder></appender><appender name="grpc" class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.log.GRPCLogClientAppender"><encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder"><layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.mdc.TraceIdMDCPatternLogbackLayout"><Pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%X{tid}] [%thread] %-5level %logger{36} -%msg%n</Pattern></layout></encoder></appender><!--nacos 心跳 INFO 屏蔽--><logger name="com.alibaba.nacos" level="OFF"><appender-ref ref="error"/></logger><!-- Level: FATAL 0 ERROR 3 WARN 4 INFO 6 DEBUG 7 --><root level="INFO"><!-- <appender-ref ref="console"/>--><appender-ref ref="debug"/><appender-ref ref="error"/><appender-ref ref="stdout"/><appender-ref ref="grpc"/></root>
</configuration>3、代码中添加日志
@RequestMapping("/fegin/test")public String feginTest() {iTestService.getServerPort();log.info("这是message1");return "message1";}
使用探针方式启动
(1)使用idea启动
配置VM options
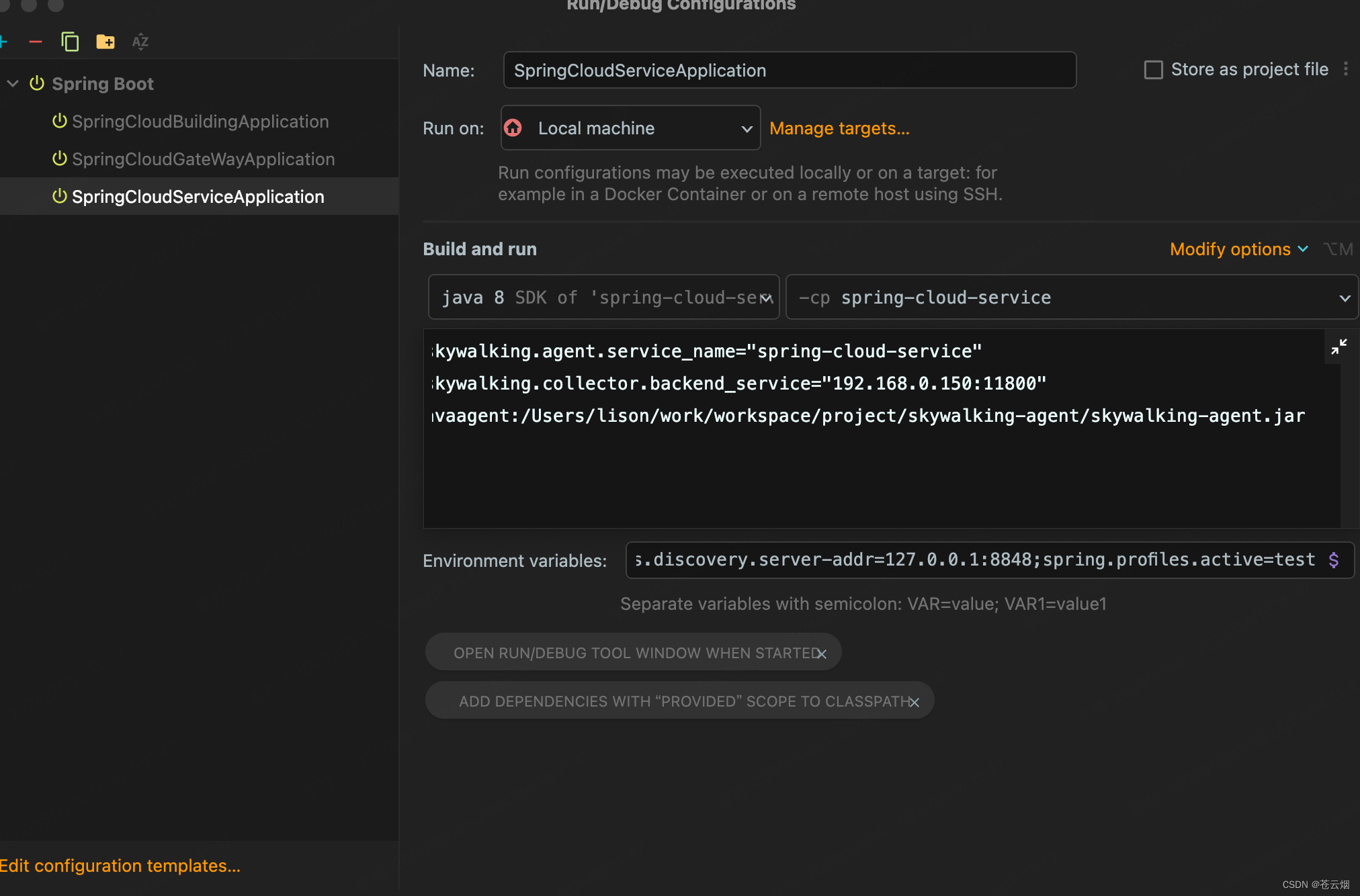
javaagent配置的参数即skywalking-agent的绝对路径。
-Dskywalking.agent.service_name="spring-cloud-service"
-Dskywalking.collector.backend_service="opaip:11800"
-javaagent:/Users/lison/work/workspace/project/skywalking-agent/skywalking-agent.jar
日志:
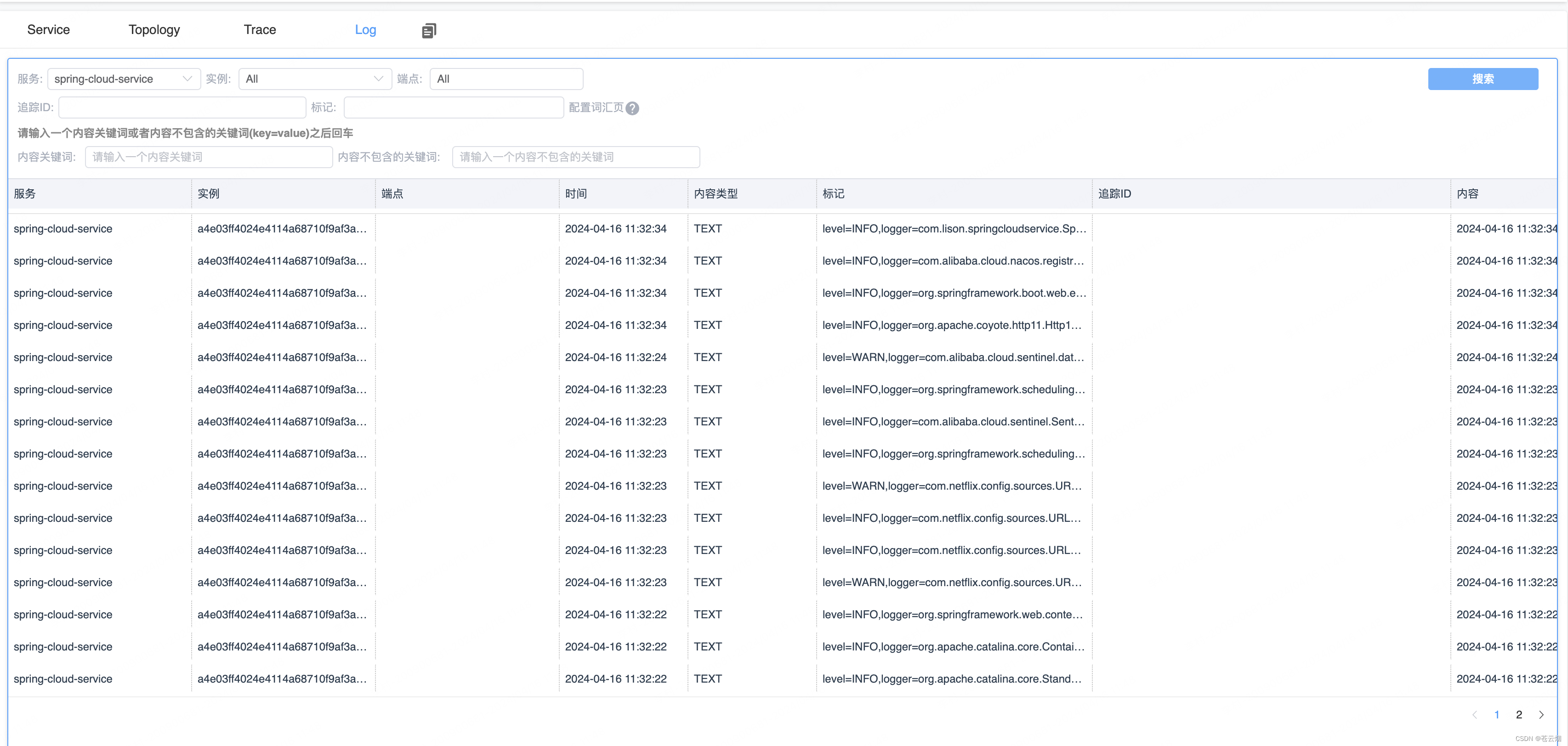
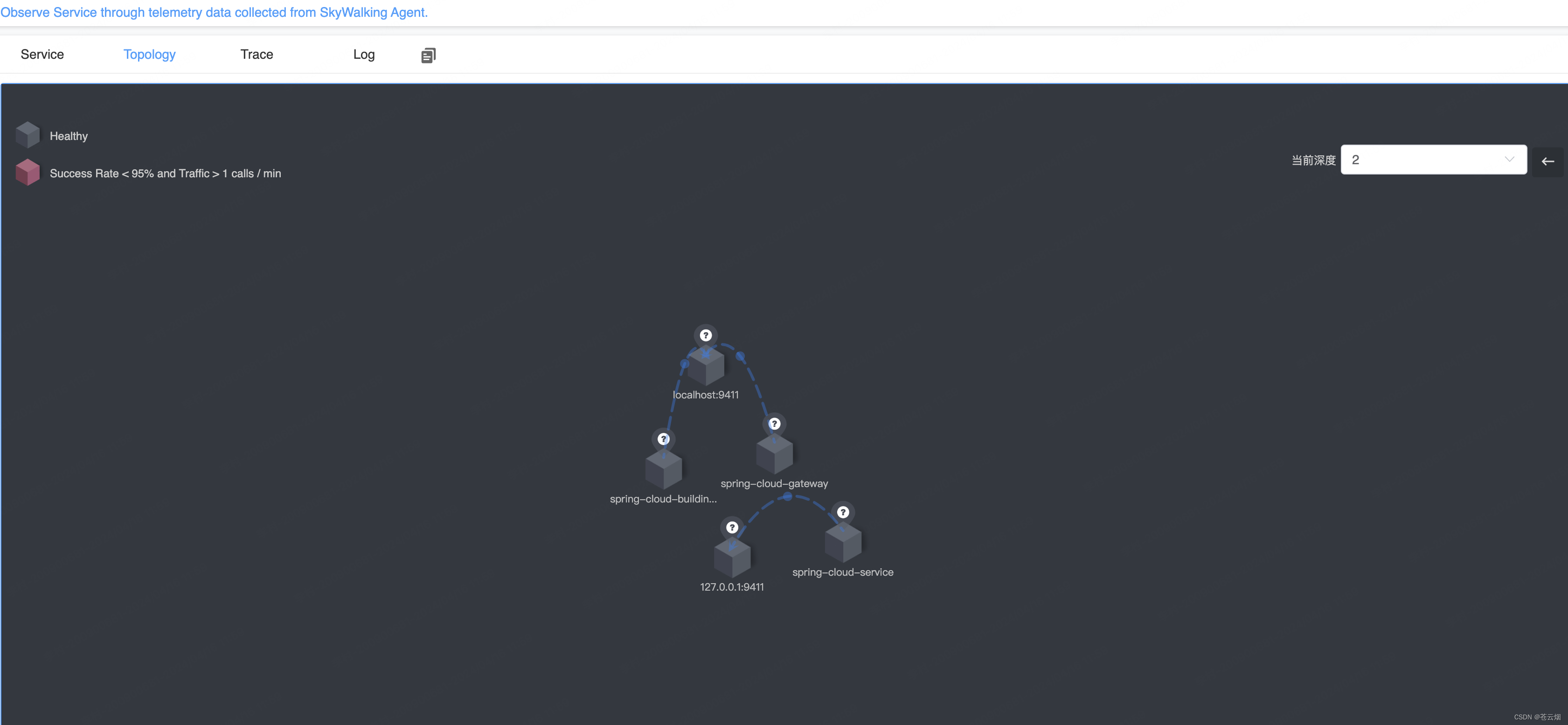
除此之外,链路追踪的展示也非常强大,服务间的 API 调用关系与执行时间、调用状态清晰列出,而且因为 SkyWalking 是方法层面上的扩展,会提供更加详细的方法间的调用过程
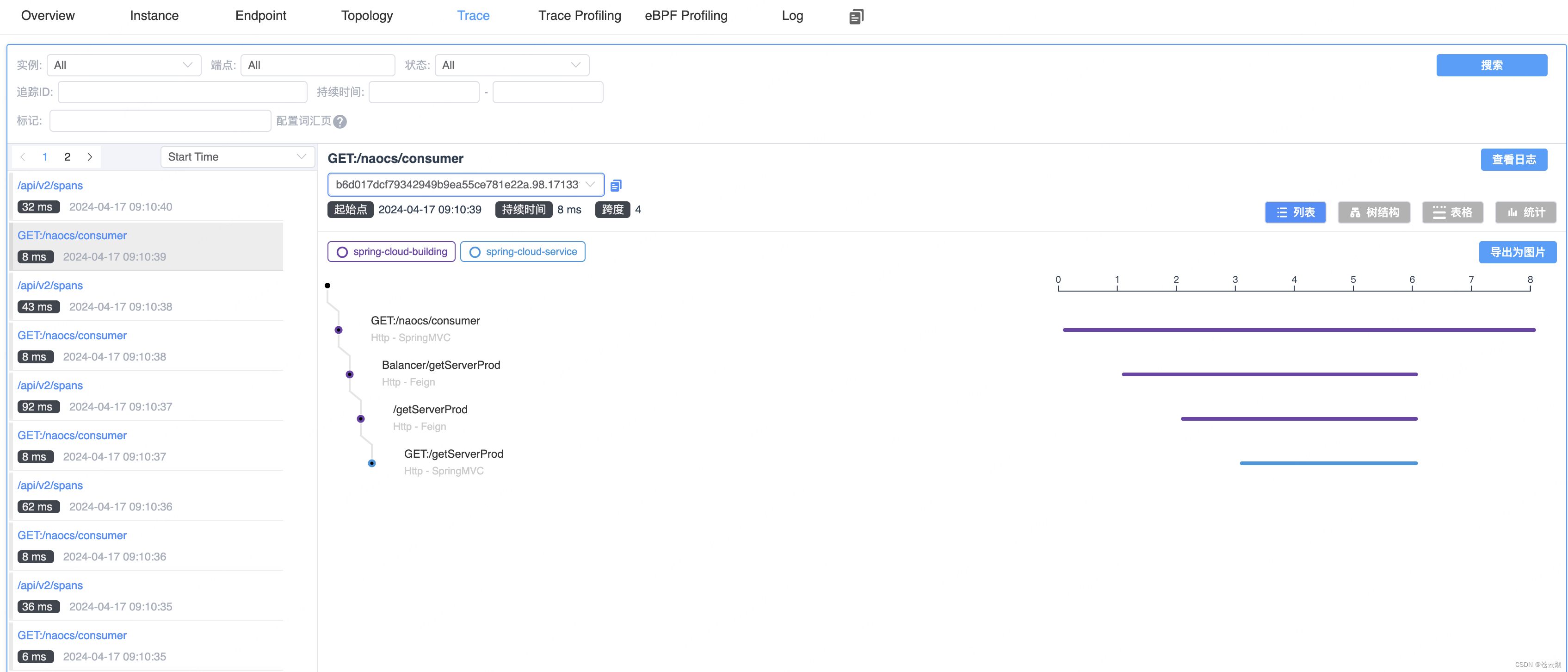
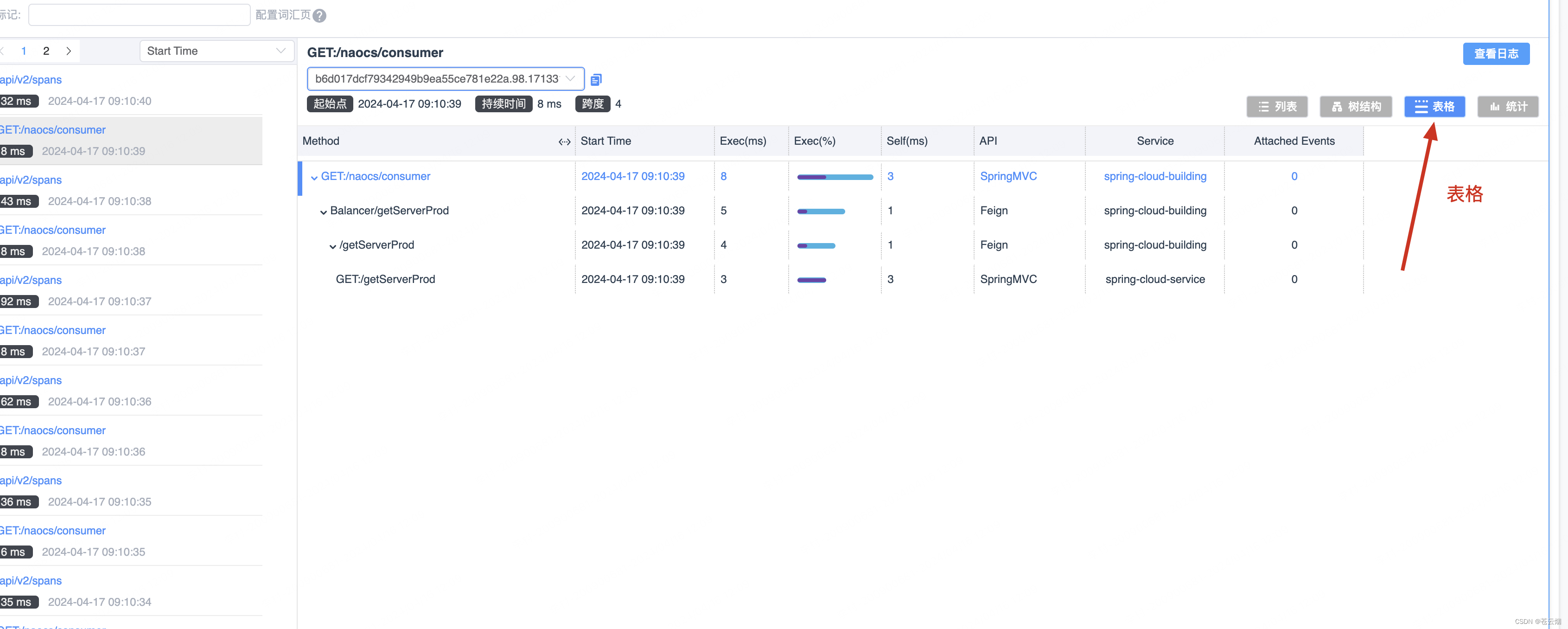
提供不同维度的视图
服务监控JVM
这篇关于Spring Cloud Alibaba-06-Sleuth链路追踪的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





