本文主要是介绍【BSP开发经验】简易文件系统digicapfs实现方式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 背景
- Linux vfs框架介绍
- 数据结构
- 系统调用
- open
- write
- read
- 总体框架
- Linux 磁盘高速缓存机制
- 标准文件访问
- 同步文件访问
- 异步文件访问
- buffer_head
- 如何实现一个简单的文件系统
- blkdevfs
- 注册文件系统
- 产生一个文件
- 让文件变得可读可写
背景
在新的分区升级启动方案中需要分别实现两个简单的文件系统,其中一个文件系统作用是可以将存放digicap的块设备变成可以挂载的设备,挂载后可以直接访问digicap打包的所有文件,命名为digicapfs。另外一个文件系统的作用是可以将任意块设备挂载为一个只有单个文件的文件系统,可以将写入块设备的读写操作转化为对文件的读写。
文件系统是操作系统向用户提供一套存取数据的抽象数据结构,方便用户管理一组数据。文件系统在Linux操作系统)中的位置在下图红框中标出,如Ext2、Ext4等。而在windows中现在常用的文件系统为NTFS、exFAT等,想必大家在格式化U盘、硬盘的时候就经常见到了。
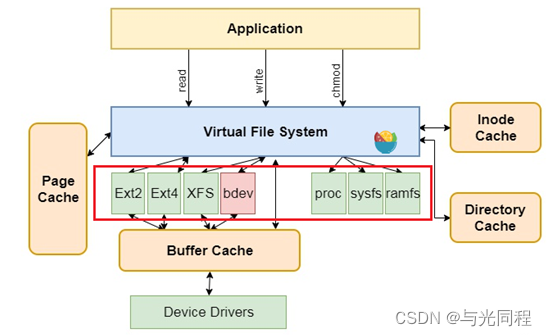
为什么要用文件系统来存取数据呢?是为了图个方便。试想如果没有文件系统,放置在存储介质(硬盘)中的数据将是一个庞大的数据主体,无法分辨一个数据从哪里停止,下一个数据又从哪里开始。通过将数据分为一块一块的,并为每一块都赋予一个名字,数据将会很容易隔离和确定。当然这都是在逻辑上去划分。既然是在逻辑上划分,那总得有个依据,将划分的结果落实下来。这时候我们就需要创建一系列的数据结构(包含数据和对此数据的一系列操作),来表示我们划分的逻辑,这就是文件系统。
Linux vfs框架介绍
数据结构
首先,我们通过进程task_struct结构体中fs成员表示了进程可见根文件系统的根节点及当前工作目录:
task_struct{...struct fs_struct *fs; /进程目录信息/struct files_struct *files; /进程打开文件信息/...
}
fs_struct结构体定义在/include/linux/fs_struct.h头文件:
struct fs_struct {int users; /结构体实例用户数量/spinlock_t lock;seqcount_t seq;int umask;int in_exec;struct path root, pwd; /进程根目录和当前工作目录/
};
path结构体实例,结构体定义如下:
struct path {struct vfsmount *mnt; /目录项所在文件系统挂载信息,vfsmount.mnt/struct dentry *dentry; /目录项指针/
};
root成员表示进程访问内核根文件系统,通常为根文件系统的根节点,但也可以通过chroot()系统调用修改进程根目录。进程以绝对路径搜索文件时,从进程根目录开始。pwd成员表示进程当前工作目录。进程以相对路径访问文件时,将会从当前工作目录开始查找。chdir()系统调用用于改变进程当前工作目录。在前面介绍的VFS初始化中,将创建内核根文件系统,并设置内核线程的根目录、当前工作目录为根文件系统根目录
files成员指向files_struct结构体实例,结构体定义在include/linux/fdtable.h头文件:
struct files_struct {/** read mostly part*/atomic_t count; /*实例引用计数*/bool resize_in_progress;wait_queue_head_t resize_wait; /*进程等待队列*/struct fdtable __rcu *fdt; /*fdtable结构体指针,初始值指向fdtab成员*/struct fdtable fdtab; /*fdtable结构体成员*//** written part on a separate cache line in SMP*/spinlock_t file_lock ____cacheline_aligned_in_smp;/*下一个打开文件的文件描述符,初始值为0,每次分配描述符后设置*/unsigned int next_fd;/*执行execve()系统调用时关闭文件的位图*/unsigned long close_on_exec_init[1];/*打开文件位图*/unsigned long open_fds_init[1];unsigned long full_fds_bits_init[1];/*打开文件file指针数组*/struct file __rcu * fd_array[NR_OPEN_DEFAULT];
};files_struct结构体主要成员简介如下:
open_fds_init[1]:进程打开文件位图,与打开文件file指针数组对应,每个比特位对应数组项是否为空,1表示数组项关联了file实例
fdt:fdtable结构体指针,初始值指向fdtab成员
fd_array[]:file指针数组,数组项指向file实例,指针数组项索引为文件描述符,无符号整数。数组项数NR_OPEN_DEFAULT与整型数比特位数相同。
fdtab:fdtable结构体成员,用于管理文件位图,其定义如下(include/linux/fdtable.h)
struct fdtable {unsigned int max_fds; /fdtable能管理的打开文件最大数量,由位图大小决定/struct file __rcu **fd; /指向file指针数组的指针/unsigned long *close_on_exec; /执行execve()系统调用时关闭文件的位图/unsigned long *open_fds; /进程打开文件位图/unsigned long *full_fds_bits;struct rcu_head rcu;
};
文件位图就是file指针数组对应的位图,每位对应指针数组中一项,比特位位置就是数组项索引,即文件描述符
进程打开的文件由file结构体表示,结构体定义在include/linux/fs.h头文件:
struct file {union {struct llist_node fu_llist; /*单链表成员*/struct rcu_head fu_rcuhead;} f_u;struct path f_path; /*文件路径信息*/struct inode *f_inode; /*指向内核文件inode实例*/const struct file_operations *f_op; /*文件操作结构指针,通常在打开文件时设为inode->i_fop*/ /** Protects f_ep_links, f_flags.* Must not be taken from IRQ context.*/spinlock_t f_lock;atomic_long_t f_count;unsigned int f_flags; /*系统调用传递的flags标记参数*/fmode_t f_mode; /*标记进程以何种模式打开文件*/struct mutex f_pos_lock;loff_t f_pos; /*文件当前读写位置,相对于文件开头处的字节偏移量*/struct fown_struct f_owner;const struct cred *f_cred;struct file_ra_state f_ra;u64 f_version;
#ifdef CONFIG_SECURITYvoid *f_security;
#endif/* needed for tty driver, and maybe others */void *private_data; /*文件私有数据指针,例如设备文件指向驱动程序定义的数据结构*/#ifdef CONFIG_EPOLL/* Used by fs/eventpoll.c to link all the hooks to this file */struct list_head f_ep_links;struct list_head f_tfile_llink;
#endif /* #ifdef CONFIG_EPOLL */struct address_space *f_mapping; /*文件地址空间指针 */
} __attribute__((aligned(4)));系统调用
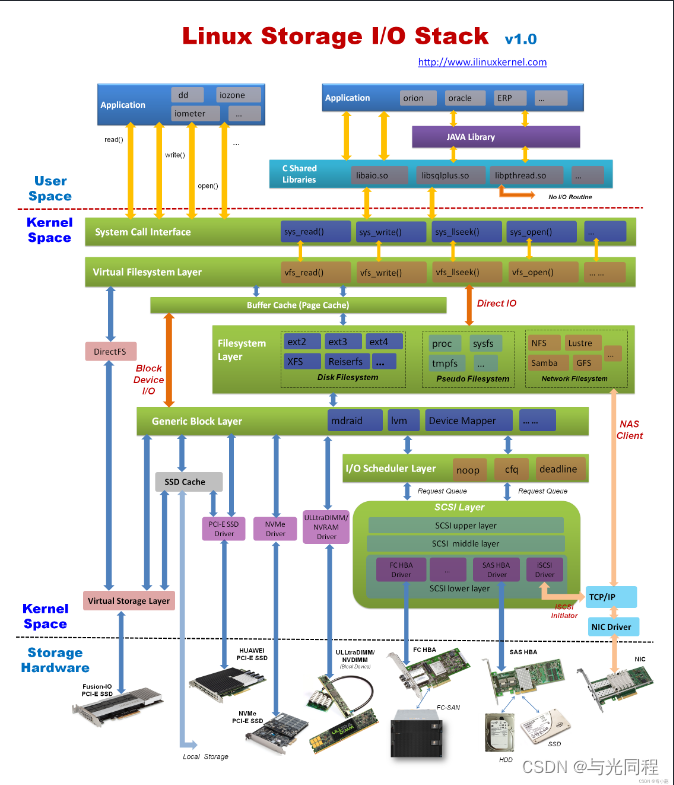
open(), read(), write() 等函数都是以 file descriptor 为对象。而实际上这件事牵扯到 3 个对象:
- 每个进程自己看到的 file descriptor (进程视角)
- open file table (系统视角)
- inode:文件真正的 inode (文件视角)

open
open负责在内核生成与文件相对应的struct file元数据结构,并且与文件系统中该文件的struct inode进行关联,装载对应文件系统的操作回调函数,然后返回一个int fd给用户进程。后续用户对该文件的相关操作,会涉及到其相关的struct file、struct inode、inode->i_op、inode->i_fop和inode->i_mapping->a_ops等。
在读写文件之前,我们必须打开文件,从应用程序的角度来看,这是通过标准库的open函数来完成的,该函数返回一个文件描述符,会调用fs/open.c中的sys_open函数,代码流程如下所示:

- PathWalk找到目标文件
- 构造并初始化inode
- 构造并初始化file
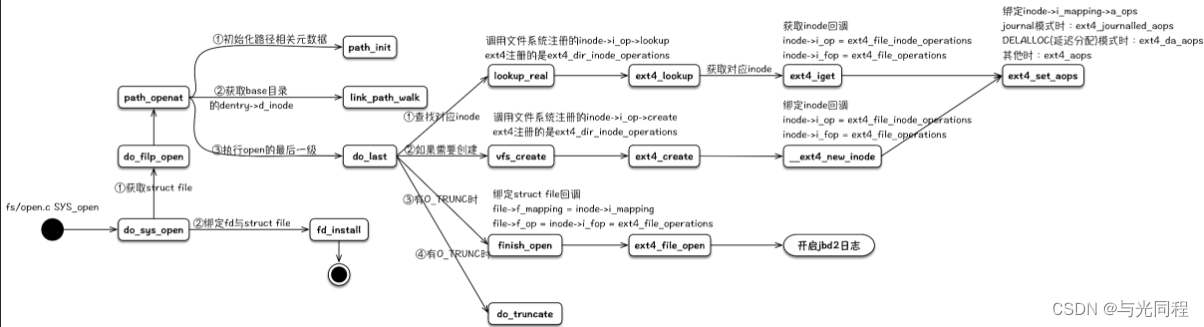
do_filp_open()函数要完成打开文件操作最重要、最繁重的工作,函数内需要创建文件file实例,遍历文件路径中每个分量,在内核根文件系统中搜索/创建对应的dentry和inode结构体实例,当到达最末尾分量时(文件名称),将其inode实例(文件inode)与file实例建立关联。因此,do_filp_open()函数执行的主要工作可概括为从路径到节点,即由文件路径确定文件inode实例,赋予file实例
write
用户进程写文件内容操作的系统调用为write(),其实现与读操作非常相似,系统调用定义如下:
_vfs_write()函数内优先调用file->f_op->write()函数执行写文件操作,如果没有定义此函数则调用通用的同步写函数**new_sync_write()**完成写操作。同步写操作通常是先将数据写入文件内容缓存,然后在适当的时候同步(写入)到介质文件系统
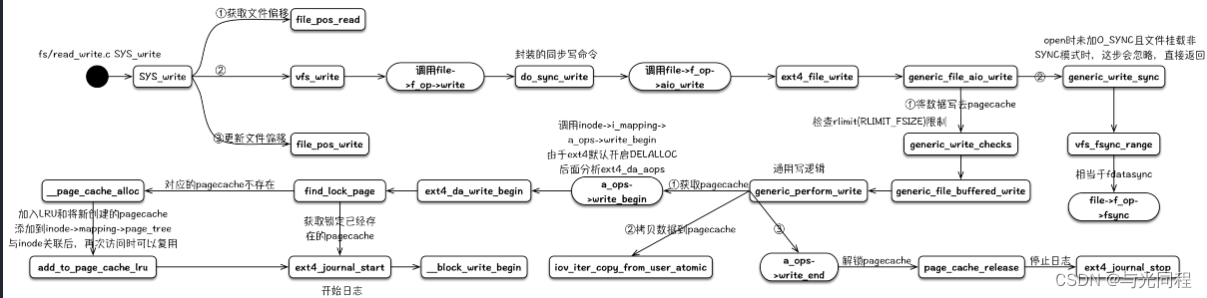
read
read的读逻辑中包含预期readahead的逻辑,其可以通过与fadvise的配合达到文件预取的效果。用户进程读文件内容的read()系统调用定义如下(/fs/read_write.c):
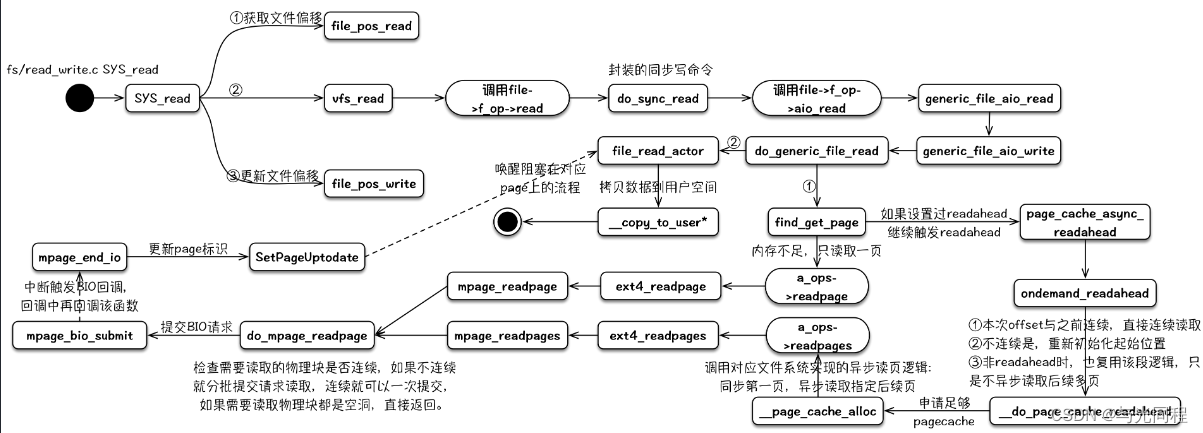
总体框架
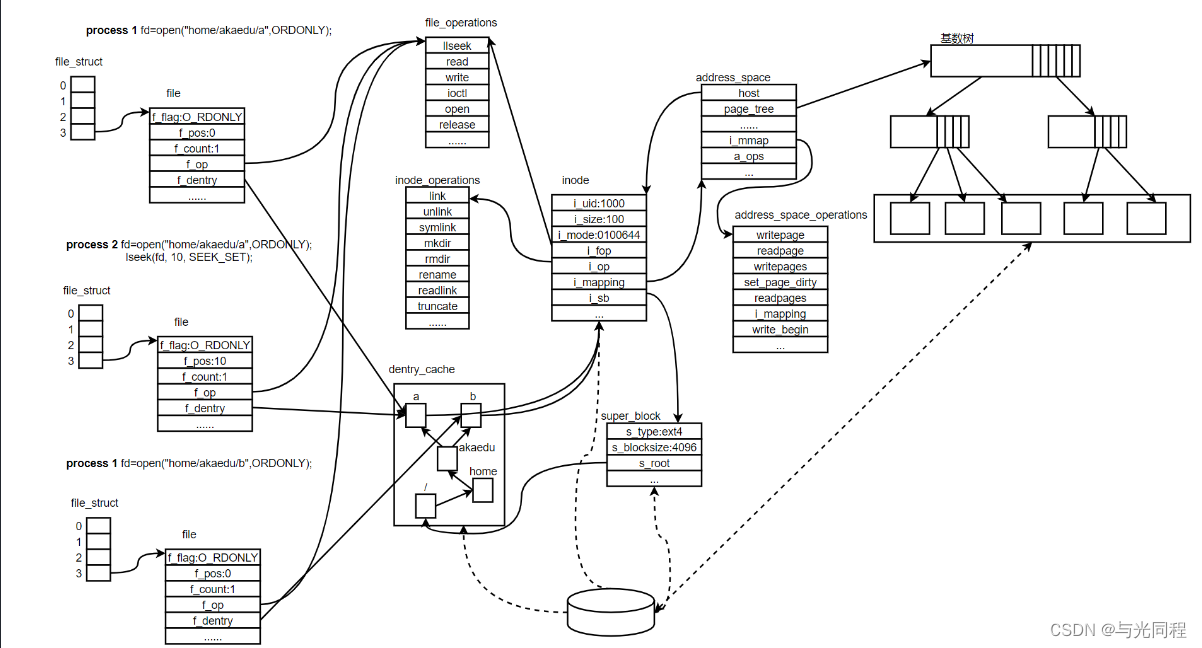
进程1和进程2都打开同一文件,但是对应不同的file 结构体,因此可以有不同的File Status Flag和读写位置。file 结构体中比较重要的成员还有f_count,表示引用计数(Reference Count),如dup 、fork 等系统调用会导致多个文件描述符指向同一 个file 结构体,例如有fd1 和fd2 都引用同一个file 结构体,那么它的引用计数就是2,,当close(fd1) 时并不会释放file 结构体,而只是把引用计数减到1,如果再close(fd2) ,引用计数 就会减到0同时释放file 结构体,这才真的关闭了文件。
每个file 结构体都有一个指向dentry结构体的指针,“dentry”是directory entry(目录项)的缩写。 我们传给open 、stat 等函数的参数的是一个路径,如/home/akaedu/a ,需要根据路径找到文件 的inode。为了减少读盘次数,内核缓存了目录的树状结构,称为dentry cache,其中每个节点是一 个dentry结构体,只要沿着路径各部分的dentry搜索即可,从根目录/找到home 目录,然后找 到akaedu目录,然后找到文件a。dentry cache只保存最近访问过的目录项,如果要找的目录项 在cache中没有,就要从磁盘读到内存中。
每个dentry结构体都有一个指针指向inode 结构体。inode 结构体保存着从磁盘inode读上来的信 息。在上图的例子中,有两个dentry,分别表示/home/akaedu/a 和/home/akaedu/b ,它们都指向同 一个inode,说明这两个文件互为硬链接。inode 结构体中保存着从磁盘分区的inode读上来信息,,例如所有者、文件大小、文件类型和权限位等。每个inode 结构体都有一个指向inode_operations结 构体的指针,后者也是一组函数指针指向一些完成文件目录操作的内核函数。
和file_operations 不同,inode_operations所指向的不是针对某一个文件进行操作的函数,而是影响文件和目录布局的函数,例如添加删除文件和目录、跟踪符号链接等等,属于同一文件系统的 各inode 结构体可以指向同一个inode_operations结构体。 inode 结构体有一个指向super_block结构体的指针。super_block结构体保存着从磁盘分区的超级块 读上来的信息,例如文件系统类型、块大小等。super_block结构体的s_root成员是一个指 向dentry的指针,表示这个文件系统的根目录被mount 到哪里,在上图的例子中这个分区 被mount 到/home 目录下。
address_space结构体,一个address_space管理了一个文件在内存中缓存的所有pages。address_space 结构其中的一个作用就是用于存储文件的 页缓存,一个inode对应一个page cache对象,一个page cache对象包含多个物理page。详细的可以参考Linux内核学习笔记(八)Page Cache与Page回写
host:指向当前 address_space 对象所属的文件 inode 对象(每个文件都使用一个 inode 对象表示)。
page_tree:用于存储当前文件的 页缓存。
tree_lock:用于防止并发访问 page_tree 导致的资源竞争问题。
其对应详细的数据结构如下图所示
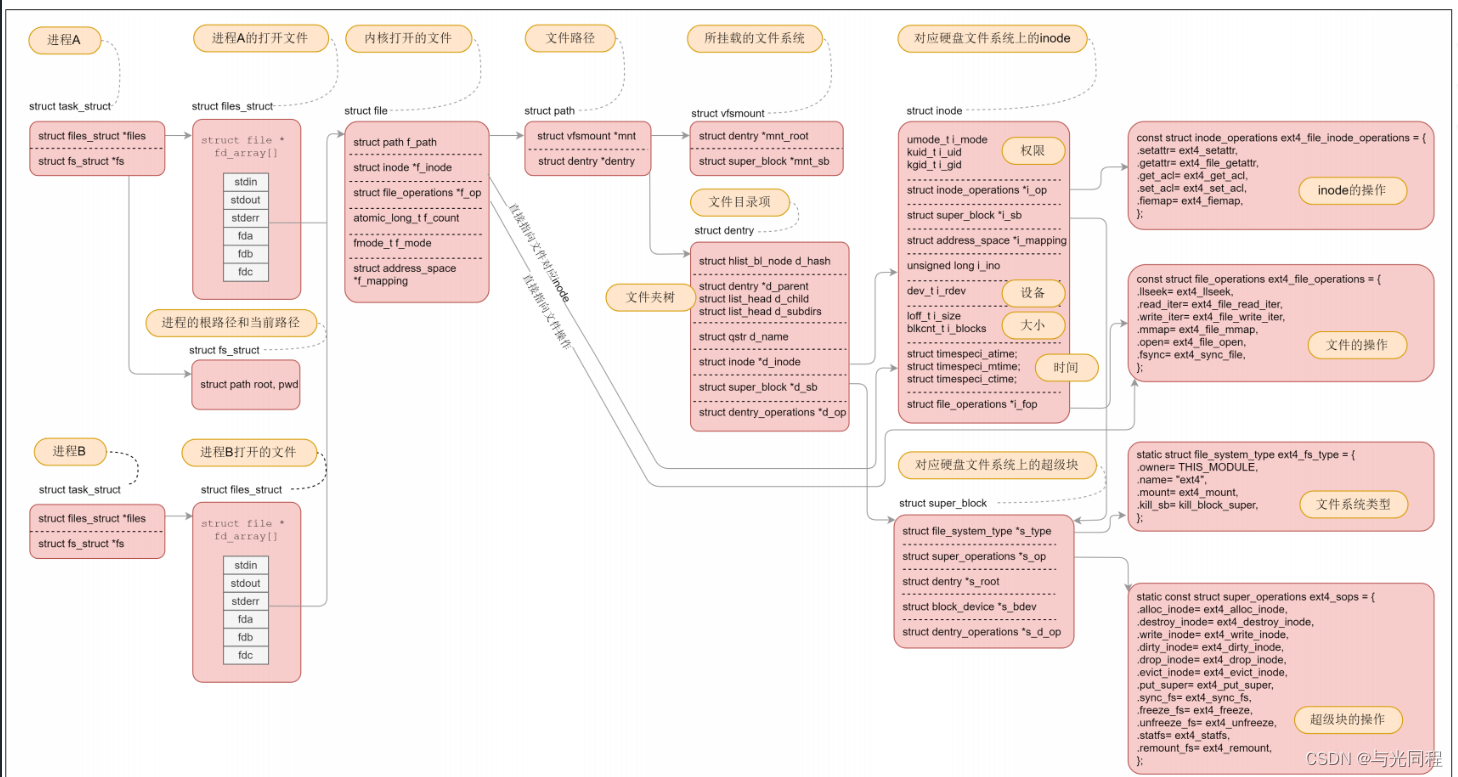
Linux 磁盘高速缓存机制
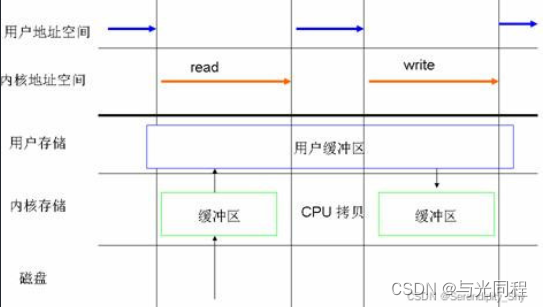
缓存I/O又被称作标准I/O,目前大多数操作系统中的文件系统的默认I/O操作都是缓存I/O。在Linux的缓存I/O机制中,数据先从磁盘复制到内核空间的缓冲区,然后从内核空间缓冲区复制到应用程序的地址空间。缓存I/O使用操作系统内核缓冲区,在一定程度上分离了应用程序空间与实际的物理设备,它能够减少读取磁盘的次数,进而提高I/O效率。
读操作:操作系统检查内核的缓冲区有没有需要的数据,如果已经缓存了,那么就直接从缓存中返回;否则从磁盘中读取,然后缓存在操作系统的缓存中。
读取: 硬盘 ->内核缓冲区 -> 用户缓冲区
写操作:将数据从用户空间复制到内核空间的缓存中。这时对用户程序来说写操作就已经完成,至于什么时候再写到磁盘中由操作系统决定,除非显示地调用了sync同步命令。
写入: 用户缓冲区->内核缓冲区 ->硬盘
正常的系统调用read/write的流程如下:
read: 硬盘 ->内核缓冲区 -> 用户缓冲区
write: 数据会从用户地址空间拷贝到操作系统内核地址空间的page cache中,这时write就会直接返回,操作系统会在恰当的时候将其刷至磁盘。
缓存I/O的缺点:数据在传输过程中需要在应用程序地址空间和缓存之间进行多次数据拷贝操作,这些数据拷贝操作所带来的CPU以及内存开销是非常大的。
标准文件访问
在 Linux 操作系统中中,通过两个系统调用( read() 和 write())来实现文件访问。。当应用程序调用 read() 系统调用读取一块数据的时候,如果该块数据已经在内存中了,那么就直接从内存中读出该数据并返回给应用程序;如果该块数据不在内存中,那么数据会被从磁盘 上读到页高缓存中去,然后再从页缓存中拷贝到用户地址空间中去。如果一个进程读取某个文件,那么其他进程就都不可以读取或者更改该文件;对于写数据操作来 说,当一个进程调用了 write() 系统调用往某个文件中写数据的时候,数据会先从用户地址空间拷贝到操作系统内核地址空间的页缓存中去,然后才被写到磁盘上(图1)。但是对于这种标准的访问文件的 方式来说,在数据被写到页缓存中的时候,write() 系统调用就算执行完成,并不会等数据完全写入到磁盘上。在Linux 中称为延迟写机制( deferred writes )。
同步文件访问
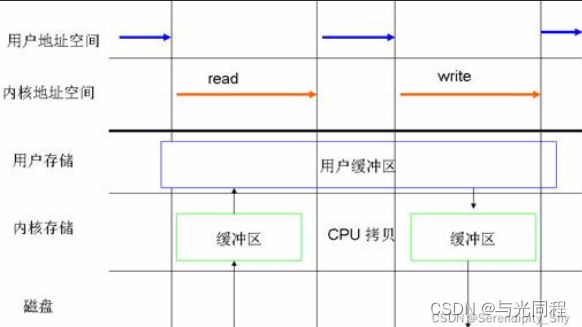
同步访问文件的方式与上述标准访问文件方式相类似,这两种方法最大区别就是:同步访问文件的时候,写数据的操作是在数据完全被写回磁盘上才算完成的(图2);而标准访问文件方式的写数据操作是在数据被写到页高速缓冲存储器中的时候就算执行完成了。
异步文件访问
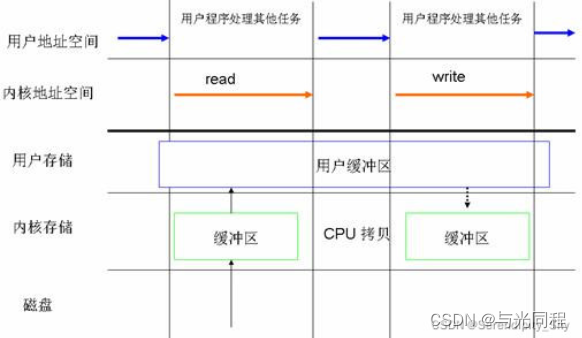
Linux 异步访问文件其本质思想:进程发出数据传输请求之后,进程不会被阻塞,也不用等待任何操作完成,进程可以在数据传输的时候继续执行其他的操作(图5)。相比于同步访问文件的方式来说,异步访问文件的方式可以提高应用程序的效率,并且提高系统资源利用率。
buffer_head
正常的文件访问都是先写入内存缓存并不会直接落盘,buffer_head就是实现这个操作的关键。
buffer_head是磁盘块的一个抽象,一个buffer_head对应一个磁盘块,buffer_head中保存对应的磁盘号
buffer_head把page与磁盘块联系起来,由于page和磁盘块的大小可能不一样,所以一个page可能管理多个buffer_head
这里假设page大小4K,块大小为1K, buffer_head,page和磁盘块关系如下:

如何实现一个简单的文件系统
blkdevfs
以blkdevfs为例 先看一下如何实现一个简单的文件系统
编写文件系统涉及一些基本数据结构。需要建立一个结构,4个操作表,如下所示。
文件系统类型结构(file_system_type);
超级块操作表(super_operations);
索引结点操作表(inode_operations);
页缓冲区表(address_space_operations);
文件操作表(file_operations)。
以上基本数据结构和操作函数,贯穿了整个文件系统的主要过程,下面具体分析这几个结构和文件系统实现的要点。
一个通常意义上的文件系统驱动可以单独被编译成模块动态加载,也可以被直接编译到内核中,为了调试的方便,本文中的文件系统采用动态加载的方式实现。实现一个文件系统必须遵照内核的一些“规则”,以下我将以递进的顺序阐述文件系统的实现过程。
文件系统既然基于可加载内核模块,自然也需要实现module_init以及mocule_exit,就从module_init函数开始入手。
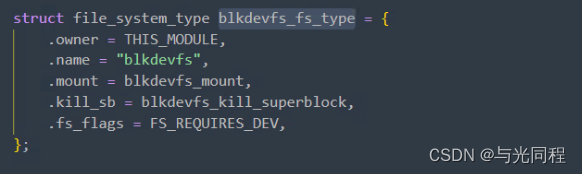
首先,必须建立一个文件系统类型(file_system_type)来描述文件系统,它含有文件系统的名称、类型标志以及get_sb()等操作。当安装文件系统时,系统会对该文件系统进行注册,即填充file_system_type结构,然后调用get_sb()函数来建立该文件系统的超级块。
对于特定的文件系统, 该文件系统的所有的superblock 都存在于file_sytem_type中的fs_supers链表中,而所有的文件系统,都存在于file_systems链表中。通过调用register_filesystem接口来注册文件系统,将一个新的文件系统类型加入到链表中。
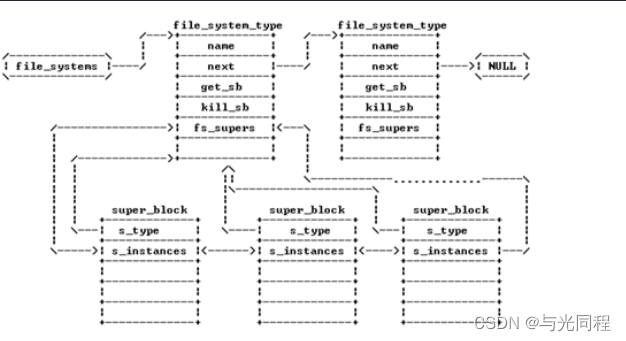
注册文件系统
int register_filesystem(struct file_system_type * fs)
注册成功以后,需要对文件系统进行挂载,因为是基于内存的文件系统,没有实际的磁盘,无法使用命令进行挂载,所以在模块初始化的时候使用内核函数kern_mount进行挂载。挂载主要完成的任务是调用file_system_type中的 mount方法,通过该方法获取该文件系统的根目录dentry,同时也获取super_block.。file_system_type的mount方法kernel也提供了已经实现的函数:mount_single,mount_pseudo等。
接下来创建若干文件和目录,用于后面进行读写操作。创建文件和目录会在向内核申请inode、dentry结构体,并且对其中的主要成员变量进行初始化。
当实现完成这个数据结构之后,就可以直接mount一个块设备了。
在mount的时候 blkdevfs具有这样的调用流程
.mount
->blkdevfs_mount
->blkdevfs_fill_supper
在blkdevfs_fill_supper中必须要填充一个全局的supper_block,和一个象征着挂载第一级目录的root_inode。
上图是blkdevfs_fill_supper 的具体实现。
产生一个文件
完成上面的步骤之后因为对于根目录的inode和file_inde_operations都还没有实现,所以虽然文件系统可以成功挂载但是还是无法进行任何操作,ls看不到任何文件。
所以下一步需要产生一个文件。
需要填充两个结构体。

这两个结构体就是目录的主要操作接口
其中
blkdevfs_iterate的作用主要就是查找该目录下存在的文件
blkdevfs_lookup的作用在于查找每一个文件的基本信息,如果该文件对应的inode还没有生成则需要生成该文件对应的inode
因为只会实现一个单文件的文件系统所以这两个函数的实现就变得非常简单
当你在目录中第一次运行ls的时候,就会先后调用iterate和lookup,之后再调用ls就只会调用iterate。
让文件变得可读可写
通过上面的实现我们可以发现当运行ls的时候你挂载的文件系统就可以显示出一个文件就像这样:

但是仅仅是这样这个文件系统还是没有作用的我们需要让这个文件系统变得可读可写。
和目录的操作一样 为了让你的文件变得具有作用也要实现两个结构体分别是:
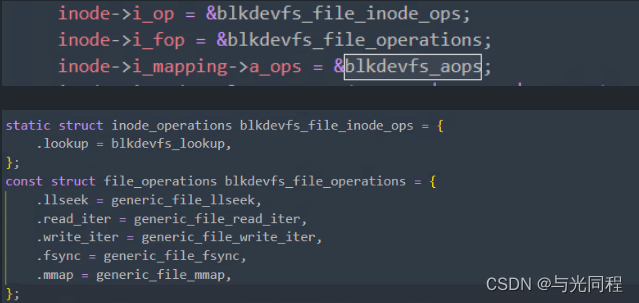
这两个结构体需要在第一次创建inode的时候完成填充。其中file_operations中填充的函数都是通用的,系统已经完成了具体实现,那么我们需要做些什么呢。
我们需要实现aops接口
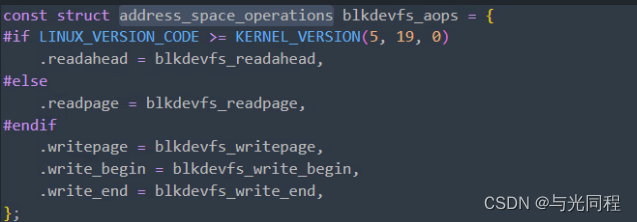
这个结构体也是在lookup 第一次创建Inode的时候进行填充,它是用于管理文件(struct inode)映射到内存的页面(struct page)的,其实就是每个file都有这么一个结构,将文件系统中这个file对应的数据与这个file对应的内存绑定到一起;与之对应,address_space_operations 就是用来操作该文件映射到内存的页面,比如把内存中的修改写回文件、从文件中读入数据到页面缓冲等。
在read 这个文件的时候 blkdevfs具有这样的调用流程

mpage_readpage是系统实现的一个通用的读取一个page的接口,而readpage会调用文件系统提供的函数指针。
这个函数实现的功能十分简单,就是将想要访问的page进行map操作。
如此这个简单的文件系统就可以读了,写也是类似的。
这篇关于【BSP开发经验】简易文件系统digicapfs实现方式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








