本文主要是介绍selenium发展史,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Selenium Core
2004 年,Thoughtworks 的工程师 Jason Huggins 正在负责一个 Web 应用的测试工作,由于这个项目需要频繁回归,这导致他不得不每天做着重复且低效的工作。为了解决这个困境,Jason 开发了一个运行在 JavaScript 沙箱中的 E2E 测试工具,并将其命名为 JavaScript Test Runner 的工具。
后来他的团队在此基础上完善了很多 API,这个工具后来被称为 Selenium Core,也是 Selenium 的雏形。这时的 Selenium Core 只支持 JS 编写的测试脚本,且只能在本地运行。
Selenium 1.0
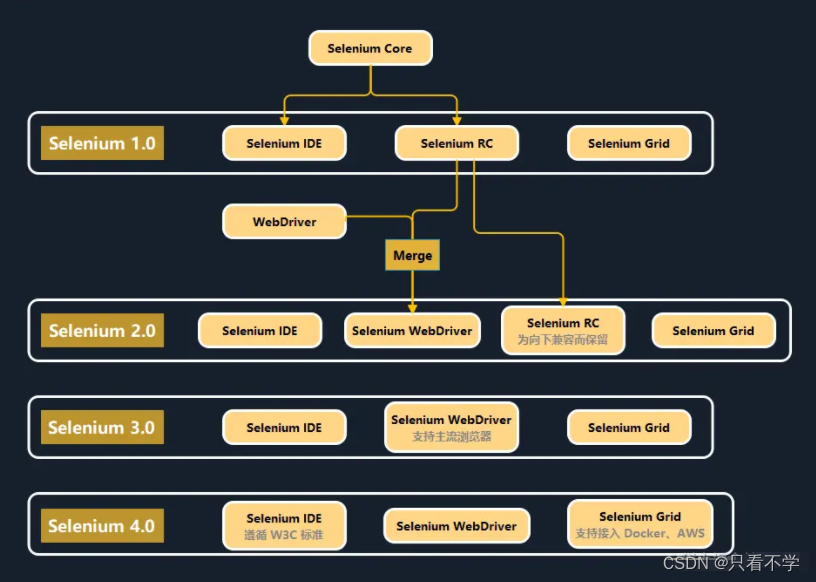
2006年, Selenium Core 团队在之前的基础上,发布了三个新工具:Selenium IDE、Selenium Grid、Selenium RC(RC 是 Remote Control 的简写),这就是第一版 Selenium。所以 Selenium 1.0 指的是这三个工具所组成的系统。Selenium 1 的发布,让多种不同语言的开发者可以控制浏览器,很多之前需要人工完成的工作得以自动化。但 Selenium 1 仍有不少问题,比如它不能捕获本机的键盘和鼠标事件。

- Selenium IDE 用来录制及回放简单的测试用例脚本;
- Selenium Grid 用来支持分布式运行测试脚本;
- Selenium Remote Control (RC) : 等于 Client Libraries + Selenium Serve, Selenium Clinet用于编写测试脚本; Selenium Server用来控制浏览器行为,
- Client Libraries(Selenium Client):你可以将它理解为一个工具库,它是 Selenium Server 提供的 API 的集合,主要用于编写测试脚本。
-
Selenium Server :用来控制浏览器行为,它主要包含三个部分:1.Selenium Launcher 用于启动浏览器,把 Selenium Core 加载到浏览器页面当中,并把浏览器的代理设置为 Selenium Server 的 Http Proxy。 2.Selenium Core :是一个带断言库的 test suite runner,由 Selenium Server 注入到浏览器中,它是 JavaScript 函数的集合,Selenium 通过这些函数对浏览器进行操作。 3.Selenium HTTP Proxy:顾名思义就是个代理服务,接受和处理脚本的 HTTP 请求
WebDriver
在 Selenium 1.0 发布的 2006 年,Google 工程师 Simon Stewart 发起了一个名为 WebDriver 的项目。它也是一个自动化测试工具,彼时刚刚起步,后来它也将成为 Selenium 的竞品之一。
导致 Selenium 1 各种问题的一个主要原因是,Selenium 是通过在浏览器中注入 JavaScript 应用,并通过执行应用中的各种 JS 函数来实现对浏览器的控制。而 Simon 希望 WebDriver 能通过浏览器提供的 API 来直接操作浏览器,借此来规避在 JS 沙箱中的各种限制。
经过几年的发展,WebDriver 通过与各浏览器的集成,成功实现了在外部直接控制浏览器行为的目标,同时 WebDriver 还利用操作系统级的调用,支持模拟用户输入。同时 WebDriver 还针对不同浏览器有着不同的策略,比如当操作 Firefox 浏览器的时候,WebDriver 是用 JavaScripts 来调用 API 的;而当我们操作 IE 浏览器的时候,WebDriver 就用 C++ 了。
直到这时,WebDriver 成为了 Selenium 1 的有力竞争者。
Selenium 2.0
2009 年,在 Google 测试自动化会议上,两个团队的开发人员在沟通后决定合并这两个项目,新项目被命名为 Selenium WebDriver,也就是 Selenium 2.0。
特点:WebDriver 成为默认的工具,而 Selenium RC 被逐渐废弃(还没完全放弃)。
Selenium 3.0
2016 年,Selenium 3 发布。这个版本并没有引入新的工具,主要加强了对浏览器的支持。相较 Selenium 2 的主要的变动有:
- 完全移除了 Selenium RC。
- WebDriver 暴露一个供浏览器接入的 API,通过各浏览器厂商提供的 Driver 来接入。
- 将 Firefox Driver 剔除(之前 Firefox Driver 是内置的)。
- 支持 Firefox 通过 GECKO Driver 来接入 Selenium。
- 通过 Apple 提供的 Safari Driver,Selenium 可以支持 Safari 接入。
- 通过 Edge Driver 支持 IE 接入。
Selenium 4.0
2021 年,Selenium 发布 Selenium 4。 在 Selenium 3 中,与浏览器的通信基于 JSON-wire 协议,因此 Selenium 需要对 API 进行编解码。而 Selenium 4 遵循 W3C 标准协议,Driver 与浏览器之间通信的标准化使得他们可以直接通信。
除此之外,Selenium 4 还做了很多改动。包括:
- 优化了对浏览器的支持。
- 使用新的设计优化了 Selenium Gird。
- 标准化了 Selenium 的文档(你敢信从 Selenium 2.0 开始,文档就没更新过…)。
- IDE 中的 CLI Runner 变更为基于 NodeJS(之前是 HTML Runner)。
- Client 和 Driver 支持了新的元素定位 API。
- 支持屏幕截图。
- 改进了 Chrome Dev Tools。之前 Chrome Driver 直接继承自 Remote Web Driver 类,现在继承自 Chromium Driver 类,这个改动使得 IDE 开发可以使用更多的 API。
演进过程图
selenium工作原理
c/s架构,客户端和服务器通过http请求交换信息(selenium/webdriver/remote/remote_connection.py 里的_request()),通过对应的浏览器driver控制浏览器 (比如谷歌的是chromedriver),每次都有一个对话session和唯一标识 sessionID
工作流程
- 编写测试脚本:用户使用支持的编程语言编写测试脚本,调用 Selenium 提供的 API。
- 调用浏览器驱动:测试脚本通过 WebDriver API 调用相应的浏览器驱动。
- 执行浏览器操作:浏览器驱动接收命令后,控制实际的浏览器执行相应的操作。
- 返回结果:浏览器执行操作后,将结果返回给浏览器驱动,驱动再将结果返回给 WebDriver API,最终返回给用户。
这篇关于selenium发展史的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






