本文主要是介绍关于Normalizer.normalize()方法的用途,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在工作中,经常在看到Normalizer.normalize()方法的身影,遂了解了下这个方法的作用。
现假设系统对外部输入作校验,如果发现输入中包含"<"或者">"字符,就判定此输入不合法,无法通过校验。但如果输入的是全角形式的字符,判断就会稍微变得麻烦,而且并不方便,一旦有所遗漏,出错之后排查可能会花费较多的时间。
// 包含全角尖括号
String sbcCase = "\uFe64" + ";reboot;" + "\uFe65";
// 包含半角尖括号
String dbcCase = "\u003C" + ";reboot;" + "\u003E";
System.out.println("包含全角尖括号的输入字符串:" + sbcCase + "\n包含半角尖括号的输入字符串:" + dbcCase);
// 虽然可以使用unicode来校验,但是很明显这种方式比较繁琐,并不方便
System.out.println("字符串\"" + sbcCase + "\"中是否包含全角尖括号:" + sbcCase.contains("<"));
System.out.println("字符串\"" + sbcCase + "\"中是否包含全角尖括号:" + sbcCase.contains("\uFe64"));运行结果如下:
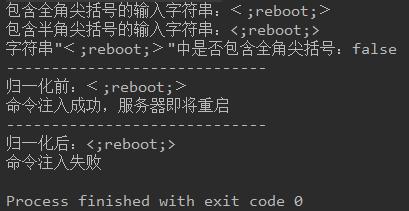
包含全角尖括号的输入字符串:﹤;reboot;﹥
包含半角尖括号的输入字符串:<;reboot;>
字符串"﹤;reboot;﹥"中是否包含全角尖括号:false
字符串"﹤;reboot;﹥"中是否包含全角尖括号:true此时,可以考虑在校验之前使用normalize方法对外部输入字符串做归一化/标准化,确保具有相同意义的字符串具有统一的二进制描述,推荐使用Normalizer.Form.NFKC参数进行归一化/标准化。
以下是一个以包含尖括号的外部输入字符串为例的简单例子:
import java.text.Normalizer;
import java.util.regex.Matcher;
import java.util.regex.Pattern;/*** 以尖括号未为例,有全角(<>)和半角(<>)之分,但是其语义是一样的* 如果未对输入中的此类字符串作归一化处理,可能会使得绕过系统输入限制,对系统造成破坏*/
public class NormalizationTest {public static void main(String[] args) {// 包含全角尖括号String sbcCase = "\uFe64" + ";reboot;" + "\uFe65";// 包含半角尖括号String dbcCase = "\u003C" + ";reboot;" + "\u003E";System.out.println("包含全角尖括号的输入字符串:" + sbcCase + "\n包含半角尖括号的输入字符串:" + dbcCase);// 普通方法无法判断是否包含全角尖括号System.out.println("字符串\"" + sbcCase + "\"中是否包含全角尖括号:" + sbcCase.contains("<"));// 归一化前,无法正确区分全角和半角尖括号,出错校验遗漏,系统受到破坏,服务被重启System.out.println("-----------------------------");System.out.println("归一化前:" + sbcCase);checkInputString(sbcCase);// 归一化后,就可正确校验,系统免受破坏System.out.println("-----------------------------");String normalized = Normalizer.normalize(sbcCase, Normalizer.Form.NFKC);System.out.println("归一化后:" + normalized);checkInputString(normalized);}private static void checkInputString(String str) {Pattern pattern = Pattern.compile("<\\s*;reboot\\s*;>");Matcher matcher = pattern.matcher(str);if (matcher.find()) {System.out.println("命令注入失败");return;}System.out.println("命令注入成功,服务器即将重启");}
}运行结果如下:
当然,本文只是举个例子,表明对外部输入字符串进行归一化后再校验可以避免一些潜在的坑点,实际操作时完全可以只判断黑名单,只要输入中包含了"reboot"这种注入命令就无法通过校验。不过,就业务而言,外部输入中的错误应该尽早拦截,早发现早治疗,越到后面捅出的篓子可能也越大。就这点而言,使用归一化操作还是有一定必要的。
但normalize方法也存在缺点,输入字符串太长的话转换效率会比较低,所以,最好还是结合实际按需使用。
写到最后,突然想起了谷歌浏览器,在输网址时如果将点号(".")误输入成中文的句号("。"),但是点击回车后这些中文句号就会变成正常的英文点号,相信这里面也有类似归一化的操作吧。

这篇关于关于Normalizer.normalize()方法的用途的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



