本文主要是介绍python文件操作常用方法(读写txt、xlsx、CSV、和json文件),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言
用代码做分析的时候经常需要保存中间成果,保存文件格式各不相同,在这里好好总结一下关于python文件操作的方法和注意事项
Python 提供了丰富的文件操作功能,允许我们创建、读取、更新和删除文件。允许程序与外部世界进行交互。
文章目录
- 引言
- 一、txt文件操作:open()函数,seek()函数, tell() 函数,flush()函数
- 二、CSV文件(.csv)
- 1.使用csv模块读写CSV文件
- 2.使用pandas库读写CSV文件
- 三、Excel文件(.xlsx)
- 四、 JSON文件(.json)
- 五、总结
一、txt文件操作:open()函数,seek()函数, tell() 函数,flush()函数
Python 的内置 open() 函数可以打开几乎任何类型的文件,只要它们位于你的文件系统中,并且你有适当的权限去访问它们。这里的 “类型” ,通常不是指文件的内容类型(如文本、图像、音频等),而是指文件的存储和访问方式。
- open() 函数打开文件,返回一个文件对象。用于后续的文件操作-读、写
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
file:必需,表示要打开的文件名(可以是相对路径或绝对路径)。
mode:可选,指定文件打开模式。默认为 ‘r’,即只读模式。常用的模式包括:
'r':只读模式(默认)。
'w':只写模式,如果文件不存在则创建它;如果文件已存在,则覆盖它。
'x':创建写模式,如果文件已存在则失败。
'a':追加模式,如果文件不存在则创建它;如果文件已存在,则在文件的末尾写入。
'b':二进制模式(可以与上述模式组合使用,如 ‘rb’、‘wb’ 等)。
'+':更新模式,可以读取也可以写入(如 ‘r+’、‘w+’、‘a+’)。
buffering:可选,设置缓冲策略。默认为 -1,表示使用默认缓冲策略(对于二进制文件和文本文件不同)。其他可选值有 0(无缓冲)、1(行缓冲)、一个大于 1 的整数(缓冲区大小)。
encoding:可选,用于指定文本文件的字符编码,如 ‘utf-8’。默认为 None,表示使用系统默认编码。
errors:可选,指定在读取或写入文件时遇到编码错误时的处理方式。默认为 None,表示使用默认的错误处理方式。
newline:可选,控制文本文件中的换行符。默认为 None,表示使用系统默认的换行符(对于不同系统可能是 \n 或 \r\n)。
closefd:可选,在 os.open() 打开的文件描述符上是否应该关闭。默认为 True。
opener:可选,一个可调用对象,用于打开文件描述符。默认为 None,表示使用内置的 os.open() 函数。
- 文件操作完成后,应使用 close() 方法关闭文件,或者使用 with 语句来自动管理文件的打开和关闭。
在打开文件时,可以使用相对路径(当前文件夹下’filename.txt’)或绝对路径来指定文件名。相对路径是相对于当前工作目录的路径,而绝对路径则是完整的文件系统路径。
1)txt读取
file = open('filename.txt', 'r') # 以读模式打开文件
content = file.read() # 读取整个文件
content = file.read(10) # 读取前10个字符
line = file.readline() # 读取一行
lines = file.readlines() # 读取所有行
file.close()
2)txt写
file = open('filename.txt', 'w') # 以写模式打开文件(会覆盖原有内容)
file.write('Hello, World!') # 写入内容
file.close() 注意:'w’只写模式,如果文件不存在则创建它;如果文件已存在,则覆盖它。
3)txt追加
file = open('filename.txt', 'a') # 以追加模式打开文件(在文件末尾添加内容)
file.write('\nAnother line.') # 追加内容
file.close()
4)使用 with ...as...语句
with open('filename.txt', 'r') as file: content = file.read() # 在这里处理文件内容
# 文件在这里自动关闭
5)异常处理
文件操作可能会引发各种异常,例如文件不存在、没有权限等。为了处理这些异常,可以使用 Python 的 try-except 块。
try: file = open('filename.txt', 'r') content = file.read()
except FileNotFoundError: print("文件不存在")
finally: if 'file' in locals() and not file.closed: file.close()
6)文件其他操作:使用 seek() 和 tell() 来读取文件的特定部分
文件操作中:seek(), tell(), 和 flush() 也是常用的方法,它们分别用于移动文件读取/写入的指针位置、获取当前文件指针的位置,以及将缓冲区中的数据强制写入文件。
当前文件夹中有example.txt文件
Hello, World!
This is an example file.
可以使用 seek() 和 tell() 来读取文件的特定部分。
with open('example.txt', 'r+') as f: # 读取前13个字符(即 "Hello, World!") print(f.read(13)) # 使用tell()查看当前文件指针的位置 print("Current file position:", f.tell()) # 输出应该是 13 # 使用seek()将文件指针移动到文件的开头 f.seek(0) # 再次读取整个文件以验证指针已移动回开头 print(f.read()) # 将文件指针移动到文件中间(例如,跳过第一行) f.seek(14) # 跳过 "Hello, World!\n" 这部分 # 读取从当前位置到文件末尾的内容 print(f.read())
flush() 方法通常用于确保所有待写入的数据都被实际写入到磁盘上的文件中,而不是仅仅停留在内存缓冲区中。
with open('output.txt', 'w') as f: f.write("This is some importance data that will be written to the file.") # 在正常情况下,数据可能会留在缓冲区中,直到文件关闭时才会被写入 # 但是,如果我们想立即确保数据被写入文件,我们可以调用 flush() f.flush() print("Data has been flushed to the file.") # 现在,即使我们没有关闭文件,数据也应该已经被写入到 output.txt 中了
二、CSV文件(.csv)
1.使用csv模块读写CSV文件
读:
import csv with open('file.csv', 'r', newline='', encoding='utf-8') as file: reader = csv.reader(file) for row in reader: print(row)
写:
import csv data = [['Name', 'Age'], ['Alice', 25], ['Bob', 30], ['Ralan', 5], ['Thy', 32]] with open(r'F:/RasoDatasets/csdn_test/file.csv', 'w', newline='', encoding='utf-8') as file: writer = csv.writer(file) writer.writerows(data)
测试结果:
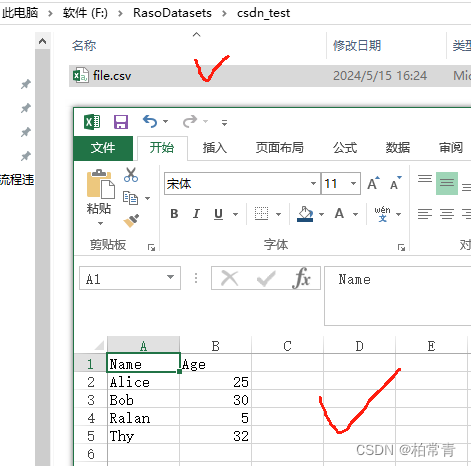
2.使用pandas库读写CSV文件
读:
import pandas as pd df = pd.read_csv('file.csv')
print(df)
写:
import pandas as pd data = {'Name': ['Alice', 'Bob'], 'Age': [25, 30]}
df =
df.to_csv('file.csv', index=False)
注:pandas库更适合数据分析哦!
在Python的pandas库中,pd.DataFrame(data) 是用来从各种数据输入源创建一个新的DataFrame对象的。这里的 data 可以是多种格式,包括列表、字典、二维数组(如NumPy数组)等。
import pandas as pd data1 = { 'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35], 'City': ['New York', 'San Francisco', 'Los Angeles']
}
data2 = [ ['Alice', 25, 'New York'], ['Bob', 30, 'San Francisco'], ['Charlie', 35, 'Los Angeles']
]
data3 = np.array([ ['Alice', 25, 'New York'], ['Bob', 30, 'San Francisco'], ['Charlie', 35, 'Los Angeles']
])
columns = ['Name', 'Age', 'City'] df1 = pd.DataFrame(data1) # 从字典创建DataFrame
df2 = pd.DataFrame(data2, columns=columns) # 从列表的列表创建DataFrame
df3 = pd.DataFrame(data3, columns=columns) # 从二维数组创建DataFrame
print(df1,'\n',df2,'\n',df3,'\n')
输出一样的结果
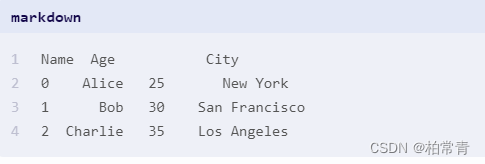
三、Excel文件(.xlsx)
使用pandas模块读写Excel文件
写:
import pandas as pddata = {'Name': ['Alice', 'Bob'], 'Age': [25, 30]}
df = pd.DataFrame(data)
df.to_excel(r'F:/RasoDatasets/csdn_test/fileXl.xlsx', index=False)
测试写Excel文件

注意:需要保证环境安装了openpyxl,否则会报错ModuleNotFoundError: No module named 'openpyxl':使用pip install openpyxl安装缺失模块。
读:
import pandas as pd df = pd.read_excel('file.xlsx')
print(df)
四、 JSON文件(.json)
使用json 模块读写JSON文件
写:
import json data = {'name': 'Alice', 'age': 25} with open('file.json', 'w', encoding='utf-8') as file: json.dump(data, file, ensure_ascii=False, indent=4)
测试写文件结果:
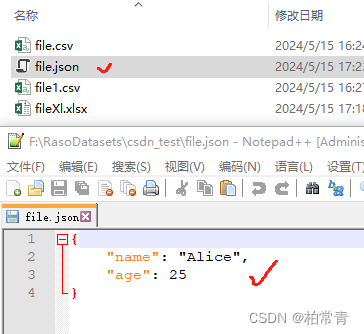
读:
import json with open(r'F:/RasoDatasets/csdn_test/file.json', 'r', encoding='utf-8') as file: data = json.load(file)
print(data)
五、总结
1.文本对open()函数,seek()函数, tell() 函数,flush()函数等文件操作函数做了简单的介绍,和实例应用。
2.使用文件工具,pandas,csv,json等操作txt,cvs,excel,json文件。
关注,收藏;多多浏览,书读百遍
这篇关于python文件操作常用方法(读写txt、xlsx、CSV、和json文件)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




