本文主要是介绍Hive DDL DML 内置函数 wc统计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一 创建表
- 1.1 create...like...
- 1.2 Create Table As Select
- 二 修改表
- 三 删除表
- 3.1 Drop Table
- 3.2 Truncate Table
- 四 内部表和外部表
- 五 Load导入表数据
- 六 聚合函数
- 七 case when
- 八 order by、sort by、distribute by、cluster by
- 8.1 order by
- 8.2 sort by
- 8.3 distribute by
- 8.4 cluster by
- 九 内置函数(build - in)
- 9.1 数值
- 9.2 字符串
- 9.3 时间函数
- 十 Hive完成wc统计
一 创建表
1.1 create…like…
官网查找线路:hive.apache.org ->点击Hive wiki -> 点击User Document -> 点击DDL -> 点击Create/Drop/Truncate Table
官网的语法如下:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_nameLIKE existing_table_or_view_name
创建一个表,类似于已存在的表(此创建表的方式,只拷贝表结构,不拷贝表数据)
案例:
hive (d7_hive)> create table emp2 like emp;
OK
Time taken: 0.235 seconds
从下图可以看出,原始表emp是有数据,emp2没有数据,只有表结构

1.2 Create Table As Select
简称:CATS
官网语法:
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name [AS select_statement];
以查询语句的结果创建一张表
案例:
create table emp3 as select empno, ename, job from emp;
应用场景:
离线作业:天粒度的,今天统计昨天的数据,并把结果放到一个tmp表里
二 修改表
官方语法:
ALTER TABLE table_name RENAME TO new_table_name;
案例:
alter table emp2 rename to emp2_bak;


三 删除表
3.1 Drop Table
官方语法:
DROP TABLE [IF EXISTS] table_name [PURGE];
官方第一句描述:
DROP TABLE removes metadata and data for this table. 意思就是:drop table 会删除元数据表和hdfs上的数据
案例:
下面要删除emp2_bak这张表,我们先看下hdfs上的数据和元数据


执行删除命令:
hive (d7_hive)> drop table emp2_bak;
OK
Time taken: 0.505 seconds;
我们再查看下hdfs数据和元数据


3.2 Truncate Table
官方语法:
TRUNCATE TABLE table_name [PARTITION partition_spec];
会删除表的数据,但是表不会删除,下面我们删除emp表中的数据

执行命令:
hive (d7_hive)> truncate table emp;
OK
Time taken: 0.224 seconds
如下图,表信息还在,只是删除了数据


四 内部表和外部表
内部表:Managed table ,外部表:External table
我们看看官网的描述:
官网地址:https://cwiki.apache.org/confluence/display/Hive/Managed+vs.+External+Tables

也就是说
| 表类型 | 执行命令 | hdfs数据 | 元数据 |
|---|---|---|---|
| Managed table | Drop | 删除 | 删除 |
| External table | Drop | 保留 | 删除 |
创建表的时候,默认是Managed table,也就是内部表。
下面我们创建一个外部表,导入数据后,进行删除操作,然后我们看一看元数据和hdfs的数据
#创建表---------------------------------------
hive (d7_hive)> create external table emp_external(> empno int,> ename string,> job string,> mgr int,> hiredate string,> sal double,> comm double,> deptno int> ) ROW FORMAT delimited fields terminated by ','> location '/d7_external/emp';
OK
Time taken: 0.261 seconds
#导入数据---------------------------------------
hive (d7_hive)> load data local inpath '/home/hadoop/emp.txt'
overwrite into table emp_external
OK
Time taken: 0.698 seconds
查看导入的数据和表的类型

 查看hdfs上的文件数据
查看hdfs上的文件数据

下面执行Drop删除命令:
hive (d7_hive)> drop table emp_external;
OK
Time taken: 0.599 seconds
查看元数据,emp_external表已经被删除

查看hdfs,文件还存在

查看hdfs上的文件内容,也是存在的

五 Load导入表数据
官方语法:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename
LOCAL:相当于从本地系统导入,也就是Linux
不加LOCAL:相当于从hdfs系统导入,filepath就要写成:hdfs://namenode:9000/user/hive/project/data1
OVERWRITE:覆盖表数据
不加OVERWRITE:追加数据
六 聚合函数
聚合函数:count max min sum avg
如下图,只写了一个统计数量,其他的都类似
但是注意点:
出现在select子句中的字段要么出现在group by中要么出现在聚合函数中
七 case when
和MySQL语法一样
hive (d7_hive)> select ename,sal,> case> when sal >0 and sal <1000 then 'lower'> when sal >=1000 and sal <2500 then 'just so so'> when sal >=2500 and sal <3500 then 'ok ok'> else 'higher'> end> as level_desc> from emp;
OK
ename sal level_desc
SMITH 800.0 lower
ALLEN 1600.0 just so so
WARD 1250.0 just so so
JONES 2975.0 ok ok
MARTIN 1250.0 just so so
BLAKE 2850.0 ok ok
CLARK 2450.0 just so so
SCOTT 3000.0 ok ok
KING 5000.0 higher
TURNER 1500.0 just so so
ADAMS 1100.0 just so so
JAMES 950.0 lower
FORD 3000.0 ok ok
MILLER 1300.0 just so so
Time taken: 0.811 seconds, Fetched: 14 row(s)
八 order by、sort by、distribute by、cluster by
8.1 order by
orderby是一个全局排序
select * from emp order by empno desc;
执行上面的语句,报错了,如下图:

图上面写了在严格模式下,如果order by 指定了,那么limit也必须指定
我们加上limit 5去执行
select * from emp order by empno desc limit 5;

下图是官网的一句描述:

上面的意思就是:在严格模式下(hive.mapred.mode=strict),order by 语句必须跟limit语句。如果你设置hive.mapred.mode=nonstrict,limit语句不是必须的。主要原因:如果输出的记录行数太大的话,单个reduce将会消耗很长的时间才能完成任务
8.2 sort by
sort by是个局部排序,每个reduce内有序
先设置reduce任务个数
set mapred.reduce.tasks=3;
然后再通过sort by查询执行
select * from emp sort by empno desc;

我们下面把查询的结果从hdfs系统导出到linux系统
insert overwrite local directory '/home/hadoopadmin/emp'
row format DELIMITED FIELDS TERMINATED BY '\t'
select * from emp sort by empno desc;
从下图可以看出,生成的3个文件内,都是按照empno进行降序,所以sort by是局部有序

8.3 distribute by
distribute by是按照一定的规则分发到reduce
insert overwrite local directory '/home/hadoopadmin/distributeby'
row format delimited fields terminated by '\t'
select * from emp distribute by length(ename) sort by ename;
上面首先按照ename的长度分到不同的reduce中,然后再进行ename升序

8.4 cluster by
cluster by xxx = distribute by xxx sort by xxx
insert overwrite local directory '/home/hadoopadmin/clusterby'
row format delimited fields terminated by '\t'
select * from emp cluster by ename;
按照ename的hashcode再对reduce个数取模,然后分发

九 内置函数(build - in)
官网地址:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF#LanguageManualUDF-DateFunctions
看Hive里的内置函数
show functions
查看某个函数的详细说明
desc function extended length

9.1 数值
1.round 四舍五入
hive (d7_hive)> select round(3.145);
OK
_c0
3.0
Time taken: 0.102 seconds, Fetched: 1 row(s)
保留2位小数
hive (d7_hive)> select round(3.145,2);
OK
_c0
3.15
Time taken: 0.062 seconds, Fetched: 1 row(s)
2.ceil 天花板
hive (d7_hive)> desc function extended ceil;
OK
#找到最小的整数,这个值不小于x
ceil(x) - Find the smallest integer not smaller than x
Synonyms: ceiling
Example:> SELECT ceil(-0.1) FROM src LIMIT 1;0> SELECT ceil(5) FROM src LIMIT 1;5
Time taken: 0.021 seconds, Fetched: 7 row(s)
3.floor 地板
hive (d7_hive)> desc function extended floor;
OK
#找到一个不大于x的最大的整数
floor(x) - Find the largest integer not greater than x
Example:> SELECT floor(-0.1) FROM src LIMIT 1;-1> SELECT floor(5) FROM src LIMIT 1;5
Time taken: 0.023 seconds, Fetched: 6 row(s)
4.least 最小值
hive (d7_hive)> desc function extended least;
OK
#获取几个数中的最小值
least(v1, v2, ...) - Returns the least value in a list of values
Example:> SELECT least(2, 3, 1) FROM src LIMIT 1;1
Time taken: 0.022 seconds, Fetched: 4 row(s)
5.greatest 最大值
hive (d7_hive)> desc function extended greatest;
OK
#获取几个数中的最大值
greatest(v1, v2, ...) - Returns the greatest value in a list of values
Example:> SELECT greatest(2, 3, 1) FROM src LIMIT 1;3
Time taken: 0.018 seconds, Fetched: 4 row(s)
9.2 字符串
1.截取字符串substr
hive (d7_hive)> desc function extended substr;
OK
#使用语法
substr(str, pos[, len]) - returns the substring of str that starts at
pos and is of length len orsubstr(bin, pos[, len]) - returns the slice
of byte array that starts at pos and is of length len
#substr和substring是同义词
Synonyms: substring
#索引位置从1开始,索引如果小于0,那就要从后往前数,先找到索引的位置
pos is a 1-based index. If pos<0 the starting position is determined by
counting backwards from the end of str.
Example:> SELECT substr('Facebook', 5) FROM src LIMIT 1;'book'> SELECT substr('Facebook', -5) FROM src LIMIT 1;'ebook'> SELECT substr('Facebook', 5, 1) FROM src LIMIT 1;'b'
Time taken: 0.021 seconds, Fetched: 10 row(s)
2.拼接concat
hive (d7_hive)> desc function extended concat;
OK
#语法
concat(str1, str2, ... strN) - returns the concatenation of str1, str2, ... strN or
concat(bin1, bin2, ... binN) - returns the concatenation of bytes in binary data
bin1, bin2, ... binN
Returns NULL if any argument is NULL.
Example:> SELECT concat('abc', 'def') FROM src LIMIT 1;'abcdef'
Time taken: 0.046 seconds, Fetched: 5 row(s)
3.把所有字符串按照指定的符号拼接起来concat_ws
hive (d7_hive)> desc function extended concat_ws;
OK
#语法
concat_ws(separator, [string | array(string)]+) - returns the concatenation
of the strings separated by the separator.
Example:> SELECT concat_ws('.', 'www', array('facebook', 'com')) FROM src LIMIT 1;'www.facebook.com'
Time taken: 0.022 seconds, Fetched: 4 row(s)
9.3 时间函数
1.传入的日期格式不是想要的
例如一个字符串日期:‘20180808 121212’,我们要转换成’2018-08-08 12:12:12’
#第一步:先把字符串转成时间戳(bigint类型)
hive (d7_hive)> select unix_timestamp('20180808 121212','yyyyMMdd HHmmss');
OK
_c0
1533701532
Time taken: 0.065 seconds, Fetched: 1 row(s)
#第二步:再把时间戳专程字符串类型
hive (d7_hive)> select from_unixtime(1533701532);
OK
_c0
2018-08-08 12:12:12
Time taken: 0.408 seconds, Fetched: 1 row(s)
也可以把上面两条语句整合成一条语句
hive (d7_hive)> select from_unixtime(unix_timestamp('20180808 121212','yyyyMMdd HHmmss'));
OK
_c0
2018-08-08 12:12:12
Time taken: 0.794 seconds, Fetched: 1 row(s)
2.获取年、月、日、时、分、秒
#获取年
hive (d7_hive)> select year('2018-01-02 03:04:05');
OK
_c0
2018
Time taken: 0.079 seconds, Fetched: 1 row(s)
#获取月
hive (d7_hive)> select month('2018-01-02 03:04:05');
OK
_c0
1
Time taken: 0.106 seconds, Fetched: 1 row(s)
#获取天
hive (d7_hive)> select day('2018-01-02 03:04:05');
OK
_c0
2
Time taken: 0.05 seconds, Fetched: 1 row(s)
#获取小时
hive (d7_hive)> select hour('2018-01-02 03:04:05');
OK
_c0
3
Time taken: 0.467 seconds, Fetched: 1 row(s)
#获取分钟
hive (d7_hive)> select minute('2018-01-02 03:04:05');
OK
_c0
4
Time taken: 0.047 seconds, Fetched: 1 row(s)
#获取秒
hive (d7_hive)> select second('2018-01-02 03:04:05');
OK
_c0
5
Time taken: 0.117 seconds, Fetched: 1 row(s)
3.指定日期+n天
#指定日期+10天
hive (d7_hive)> select date_add('2018-01-02',10);
OK
_c0
2018-01-12
Time taken: 0.067 seconds, Fetched: 1 row(s)
#指定日期-10天
hive (d7_hive)> select date_add('2018-01-02',-10);
OK
_c0
2017-12-23
Time taken: 0.044 seconds, Fetched: 1 row(s)
十 Hive完成wc统计
1.本地准备一个如下图的文件
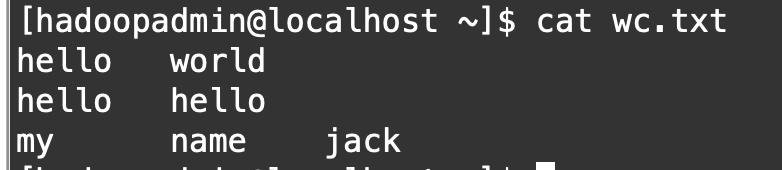
2.创建一个表wc,并把上面的数据导入wc
创建表
create table wc(sentence string);
导入数据
load data local inpath '/home/hadoopadmin/wc.txt' into table wc;
查询表
select * from wc;
 hive里有个split函数,把字符串转成数组array,我们看下帮助功能的描述:
hive里有个split函数,把字符串转成数组array,我们看下帮助功能的描述:

那我们对表wc的sentence字段进行split:
hive (d7_hive)> select split(sentence,'\t') from wc;
OK
_c0
["hello","world"]
["hello","hello"]
["my","name","jack"]
Time taken: 0.059 seconds, Fetched: 3 row(s)
hive中有个函数可以对数组array进行行转列,如下图说明,把数组转成单个的列

那么我们把上面的语句再添加一个explode函数:
hive (d7_hive)> select explode(split(sentence,'\t')) as word from wc;
OK
word
hello
world
hello
hello
my
name
jack
Time taken: 0.103 seconds, Fetched: 7 row(s)
拿到这样的数据,我们就可以通过group by分组统计了,把上面这个结果作为字表查询:
select word,count(1) cnt
from
(select explode(split(sentence,'\t')) as word from wc) t
group by word;

如上图,统计出每个单词出现的次数了
这篇关于Hive DDL DML 内置函数 wc统计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





