本文主要是介绍解决AdaptiveAvgPool2d部署算子不支持问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、Pytorch中AdaptiveAvgPool2d函数详解
torch.nn.AdaptiveAvgPool2d()接受两个参数,分别为输出特征图的长和宽,其通道数前后不发生变化。如以下:
self.global_avgpool = nn.AdaptiveAvgPool2d(1) # 输出N*C*1*1
self.global_avgpool = nn.AdaptiveAvgPool2d((5,5)) # 输出N*C*5*5参考:
官方AdaptiveAvgPool2d介绍
官方AvgPool2d介绍
自适应平均池化是一种池化方法,可以在不同大小的输入中自适应地对每个位置进行平均池化。不需要指定池化核的大小,而是通过输出的大小来决定池化的大小和步幅。实际上AdaptiveAvgPool2d就是AvgPool2d,但是相比之下AdaptiveAvgPool2d指定输出大小可以固定输出大小,在一些模型输入不固定大小的场景下确保了输出的大小(kernel变化),而AvgPool2d会由于输入的大小而导致输出不定(kernel固定)。
self.global_avgpool = nn.AvgPool2d(kernel_size, stride)
二、如何用AvgPool2d替换AdaptiveAvgPool2d
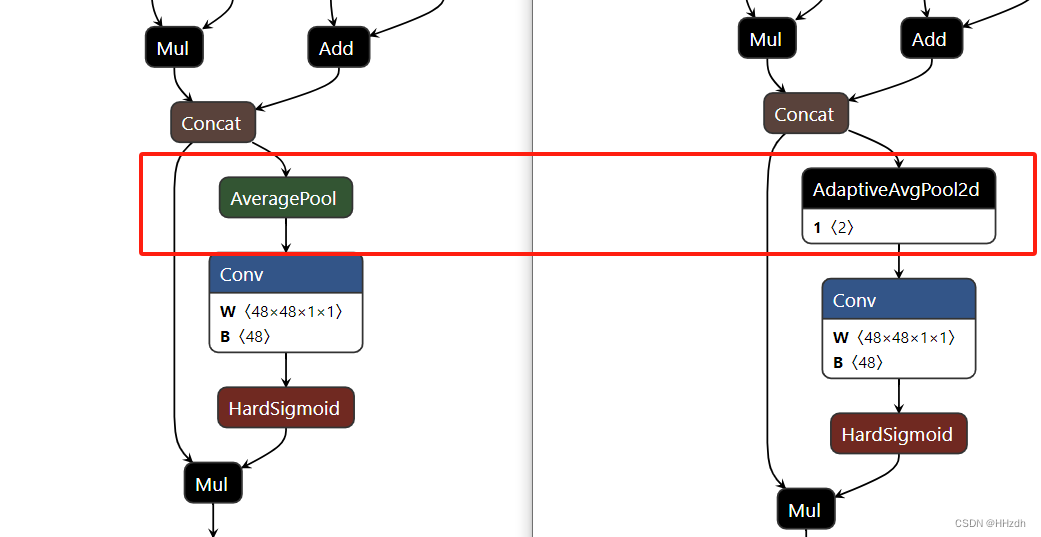
个人测试ncnn和Ascend端侧是不支持AdaptiveAvgPool2d算子的,这个时候如果直接转换是不行的,而根据上述,完全可以考虑把模型中的AdaptiveAvgPool2d更改为AvgPool2d,不过这时候需要根据输入计算一下kernel大小,stride默认是等于kernel。
def __init__(self, channels: int, init_cfg: OptMultiConfig = None) -> None:super().__init__(init_cfg=init_cfg)self.global_avgpool = nn.AdaptiveAvgPool2d(1)def forward(self, x: Tensor) -> Tensor:# AdaptiveAvgPool2dout_1 = self.global_avgpool(x)# AvgPool2dsize = x.shape[2:]k = [int(size[i]) for i in range(0, len(size))]out_2 = F.avg_pool2d(x,kernel_size=k,)return out_1, out_2如我这里希望输出是(1,1)的大小,那么kernel就是input_size/output_size=input_size,即输入的大小,这样就可以完成等价替换了。通过netorn可以查看,且经过测试可以通过ncnn和Ascend端侧的模型转换(即转为.param&.bin或者.om模型文件)
这篇关于解决AdaptiveAvgPool2d部署算子不支持问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







