本文主要是介绍浅谈下MYSQL表设计的几条规则,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作为后端开发人员,避免不了和数据库打交道,可是我们怎么能够设计出高效,可维护,可扩展的数据库设计呢,在这里我总结了几个点,供大家参考。
在写之前,可能需要重复下数据库设计的范式原则,我们不需要完全死板遵循范式原则,它可以作为我们的一个标准,但是也需要结合业务实际情况,在尽可能遵循范式的同时也要高效地满足业务需求,可能1NF,2NF是原则,但是3NF我们需要结合自己的业务去思考设计。
第一范式(1NF):确保表中的每一列都是不可分割的基本数据项,即列具有原子性(列的不可再分性)。
第二范式(2NF):在1NF基础上,非主键列完全依赖于整个主键,消除部分依赖(也就是每行数据的唯一性)。
第三范式(3NF):在2NF基础上,非主键列之间不存在传递依赖,即每个非主键列只依赖于主键,不依赖于其他非主键列(也就是说如果出现依赖非主键的字段,那就要考虑是否需要拆出来一张表)。
1. 名称
要求:
1. 见名知意,采用下划线的命名方式。
2. 利用前缀对表进行业务性的归类,比如基础表:base_,订单表:order_。
3. 表字段尽可能采用小写,提高可读性。
4. 避免保留字,防止sql误读。
5. 如果是外键字段,字段前缀需要加上表名称。
6. 状态类的字段避免采用is_开头,因为:在对应到java实体类属性的时候,布尔类型的属性其getter方法应以is开头,而非布尔类型的属性则以get开头,如果属性本身就以is开头,这将导致getter方法的命名产生混淆或不符合规范。
7. 创建人,创建时间,更新人,更新时间,推荐使用:created_by,created_time,updated_by,updated_time。
2. 字段类型
原则: 尽可能选择占用存储空间小的字段类型,在满足正常业务需求的情况下,从小到大选择。
列举场景如下:
- 整型 (INT, TINYINT, SMALLINT, MEDIUMINT, BIGINT):
- INT: 通用的整数类型,适用于大部分计数或编号场景,如用户ID、订单ID。
- TINYINT: 当数值范围较小,如0-255,适用于状态码、权限标志。
- SMALLINT, MEDIUMINT: 当需要比TINYINT更大的范围但又不需要INT那么大的时候。
- BIGINT: 当整数范围需要超过INT的限制时,如非常大的用户基数或计数。
- 浮点型 (FLOAT, DOUBLE, DECIMAL):
- FLOAT, DOUBLE: 适合存储科学计算、精确度要求不高或大数据范围的数值,如地理坐标、物理测量值。
- DECIMAL: 对精度有严格要求的财务数据,如货币金额,因为它能提供固定的小数位数和完全精确的计算。
- 字符串类型 (VARCHAR, CHAR, TEXT, ENUM, SET):
- VARCHAR: 用于存储可变长度的字符串,是最常用的文本类型,适用于名字、地址等。
- CHAR: 固定长度字符串,适合存储长度稳定的字段,如邮编、固定长度的代码。
- TEXT: 存储大量文本内容,如文章、评论,当VARCHAR的长度不够时使用。
- ENUM: 用于定义一个预设的值列表,适用于有限选项的选择,如性别、状态。
- SET: 允许多选,存储一个预定义值的集合,适用于标签、权限集合。
- 日期时间类型 (DATE, TIME, DATETIME, TIMESTAMP):
- DATE: 只存储日期,不包含时间部分,适用于记录生日、签约日期。
- TIME: 只存储时间,不包含日期,适用于记录营业时间、事件持续时间。
- DATETIME: 同时存储日期和时间,精度到秒,适合大多数日期时间记录。
- TIMESTAMP: 类似DATETIME,但自动更新并支持时区转换,适合记录创建或更新时间。
- 二进制类型 (BINARY, VARBINARY, BLOB, TEXT):
- BINARY, VARBINARY: 存储二进制数据,如图片、文件的原始字节流。
- BLOB, TEXT: 用于存储较大的文本或二进制数据,BLOB适合二进制大对象,TEXT适合大文本。
注意:decimal(m,n),其中n是指小数的长度,而m是指整数加小数的总长度。
3. 字段长度
注意:在mysql中除了varchar和char是代表字符长度之外,其余的类型都是代表字节长度。
那么biginit(n) 这个n表示什么意思呢?
答:在MySQL中,BIGINT(n)中的n实际上并不改变BIGINT类型的实际存储大小或取值范围,这一点与INT(n)等其他整数类型的行为相似。这里的n表示的是显示宽度,它是一个可选的参数,用于指示在查询结果中显示该整数值时所使用的字符宽度。换句话说,它是一个格式化选项,用于控制数值的对齐和格式,而不是影响存储的值本身。
4. 字段个数
我们在建表的时候,一定要对字段个数做一些限制。建议每表的字段个数,不要超过20个。
5. 主键要求
-
在单个数据库中,主键可以通过AUTO_INCREMENT,设置成自动增长的。
-
在分布式数据库中,特别是做了分库分表的业务库中,主键最好由外部算法(比如:雪花算法)生成,它能够保证生成的id是全局唯一的。
6. 存储引擎
在mysql8以前的版本,默认的存储引擎是myisam,而mysql8以后的版本,默认的存储引擎变成了innodb。myisam的索引和数据分开存储,而有利于查询,但它不支持事务和外键等功能。而innodb虽说查询性能,稍微弱一点,但它支持事务和外键等,功能更强大一些。
以前的建议是:读多写少的表,用myisam存储引擎。而写多读多的表,用innodb。但mysql对innodb存储引擎性能的不断优化,现在myisam和innodb查询性能相差已经越来越小。
所以,建议我们在使用mysql8以后的版本时,直接使用默认的innodb存储引擎即可,无需额外修改存储引擎。
7. NOT NULL
在创建字段时,需要选择该字段是否允许为NULL。我们在定义字段时,应该尽可能明确该字段NOT NULL。
主要有以下原因:
- 在innodb中,需要额外的空间存储null值,需要占用更多的空间。
- null值可能会导致索引失效。
- null值只能用is null或者is not null判断,用=号判断永远返回false。
因此,建议我们在定义字段时,能定义成NOT NULL,就定义成NOT NULL,同时如果有必要,尽可能给一些状态类的字段设定默认值。
8. 索引
索引分类
索引的分类没有固定的标准,可以从这么几个维度进行分类:
1. 按数据结构分类:
- B-Tree索引:这是MySQL中最常见的索引类型,尤其InnoDB存储引擎默认使用B+Tree作为索引结构。它支持范围查询和排序操作,适用于大多数情况。
- Hash索引:主要应用于Memory存储引擎,适合于等值查询,查询速度快,但不支持范围查询。
- Full-Text索引:用于全文搜索,能够高效地处理LIKE '%keyword%'这类查询,支持InnoDB和MyISAM存储引擎。
- R-Tree索引:专为地理空间数据设计,适用于GEOMETRY类型的数据,支持高效的范围查询,但在MySQL中较少使用,且支持的存储引擎有限。
2. 按物理存储分类:
- 聚集索引(Clustered Index):数据行的物理顺序与索引顺序一致,每个InnoDB表都有一个聚集索引,通常是主键索引。
- 非聚集索引(Non-Clustered Index):也称辅助索引,索引结构中存储的是行的指针或主键值,而非实际行数据。InnoDB表的非主键索引属于此类。
3. 按逻辑功能分类:
- 主键索引:基于表的主键创建,确保唯一且非空,每个表只能有一个主键索引。
- 唯一索引:索引列的值必须唯一,可以有NULL值,但一个列中只能有一个NULL值。
- 普通索引:没有唯一性要求的基本索引,可以创建在任何列上,提高查询效率。
- 全文索引:用于全文搜索,特别适合文本字段的复杂查询。
4. 按字段个数分类:
- 单列索引:基于单一列创建的索引。
- 联合索引/复合索引/组合索引:基于多列创建的索引,遵循最左前缀原则,即查询时必须按照索引创建时的列顺序使用到索引。
5. 特殊索引:
- 空间索引:用于处理空间数据类型(如GEOMETRY),支持空间数据的高效查询,主要在MyISAM存储引擎中使用。
创建原则
- 高频查询字段:对查询频次较高且数据量较大的表建立索引,以加速查询过程。
- 索引字段选择:从WHERE子句中的条件提取最佳候选列,优先选择最常用且过滤效果好的列或列组合创建索引。若多个字段经常一起被查询,考虑创建组合索引。
- 唯一性索引:使用唯一索引(如主键索引、唯一索引)提高数据的区分度,进而提高查询效率。唯一索引还能提供数据唯一性的约束。
- 索引数量与效率:索引虽能提升查询速度,但过多的索引会增加写操作的成本(如插入、更新、删除)并占用更多存储空间。需要平衡查询速度和维护成本,建议索引个数不要超过5个。
- 组合索引优化:创建组合索引时,考虑查询中字段的顺序和组合频率,将选择性高的字段放在前面,以提高索引的利用率。
使用场景
- 快速查找:对经常需要快速定位记录的字段,如用户ID、产品ID等,创建索引。
- 排序与分组:如果查询中包含ORDER BY或GROUP BY子句,对排序或分组的字段创建索引可以显著提高执行效率。
- 范围查询:对于使用BETWEEN、>, <等操作符的范围查询,合适的索引可以加速检索过程。
- 联接操作:在多表联接查询中,为联接条件涉及的字段创建索引,可以加快联接速度。
- 分页查询:对于需要频繁执行的分页查询,确保排序字段上有索引,特别是当偏移量较大时。
- 高并发场景:在高并发读取的场景下,合理使用索引可以减少锁的竞争,提高并发处理能力。
注意:创建唯一索引时,相关字段一定不能包含null值,否则唯一性会失效。
9. 字符集
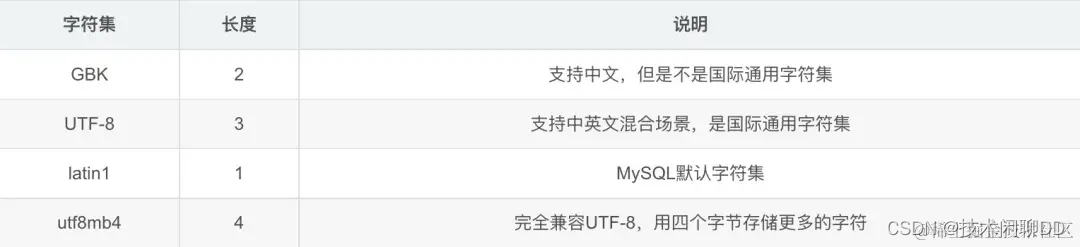
mysql的字符集使用最多的还是:utf-8和utf8mb4,其中utf-8占用3个字节,比utf8mb4的4个字节,占用更小的存储空间。
但utf-8有个问题:即无法存储emoji表情,因为emoji表情一般需要4个字节。由此,使用utf-8字符集,保存emoji表情时,数据库会直接报错。
建议在建表时字符集设置成:utf8mb4,会省去很多不必要的麻烦。
10. 排序规则
MySQL的字符排序规则定义了字符集内字符串比较和排序的规则,包括是否区分大小写、重音符号、以及特定语言的字母排序顺序。常见的排序规则通常以字符集名称为前缀,并以后缀表示其特性,**如_ci表示“Case Insensitive”(不区分大小写),_cs表示“Case Sensitive”(区分大小写),_bin表示二进制排序(区分大小写且区分字符的所有变体,如重音)**等。以下是一些常见的排序规则及其使用场景:
1. utf8mb4_general_ci
特性:不区分大小写,也不区分重音和其它变音符号。这是最常用的、最宽松的比较规则,适用于对性能有较高要求且不严格要求语言特定排序的应用。
使用场景:适用于大多数Web应用、博客、论坛等,尤其适合那些内容主要是英文且不涉及复杂语言排序需求的场景。
2. utf8mb4_unicode_ci
特性:基于Unicode Collation Algorithm (UCA),提供更准确的国际化排序,不区分大小写。它能更好地处理不同语言的特定排序规则。
使用场景:适用于需要支持多语言内容排序的应用,如国际化的网站、翻译平台、全球化企业系统等,当对排序准确性有较高要求时选用。
3. utf8mb4_0900_ai_ci
特性:基于Unicode 9.0标准,不区分大小写和重音符号,是MySQL 8.0.1及更高版本的默认排序规则。它比utf8mb4_unicode_ci更现代,可能包含更多最近的Unicode字符分类更新。
使用场景:适用于新开发的项目,尤其是那些需要利用最新Unicode标准特性的应用,以及期望获得更好国际化支持的系统。
4. utf8mb4_0900_as_ci
特性:类似于utf8mb4_0900_ai_ci,但提供了 accent-sensitive 的比较,意味着在比较时不区分大小写但区分重音。
使用场景:适合那些需要区分重音但在大小写上不作区分的特定语言环境,如某些欧洲语言的文本处理系统。
5. utf8mb4_bin
特性:二进制排序,区分大小写和所有字符变体,包括重音。这种排序规则提供最精确的比较,但性能消耗相对较高。
使用场景:适用于需要精确字符串比较的场景,如密码存储、唯一标识符验证、序列号比较等,以及对数据准确性要求极高的特定应用。
11. 大字段
我们在创建表时,对一些特殊字段,要额外关注,比如:大字段,即占用较多存储空间的字段。如果直接定义成text类型,可能会浪费存储空间,所以建议将这类字段定义成varchar类型的存储效率更高。
如果遇到大文档类的字段,最好的方式是将文件上传到文件服务器,数据库存储URL链接,如果真的要存数据库,可以存储到mongodb中,然后在mysql的业务表中,保存mongodb表的id。
12. 冗余字段
我们在设计表的时候,为了性能考虑,提升查询速度,有时可以冗余一些字段。但是需要注意数据的一致性问题,对冗余字段也需要关注更新,
13. 注释
我们在做表设计的时候,一定要把表和相关字段的注释加好。
举例:
CREATE TABLE `sys_dept` (`id` bigint NOT NULL AUTO_INCREMENT COMMENT 'ID',`name` varchar(30) NOT NULL COMMENT '名称',`pid` bigint NOT NULL COMMENT '上级部门',`valid_status` tinyint(1) NOT NULL DEFAULT 1 COMMENT '有效状态 1:有效 0:无效',`create_user_id` bigint NOT NULL COMMENT '创建人ID',`create_user_name` varchar(30) NOT NULL COMMENT '创建人名称',`create_time` datetime(3) DEFAULT NULL COMMENT '创建日期',`update_user_id` bigint DEFAULT NULL COMMENT '修改人ID',`update_user_name` varchar(30) DEFAULT NULL COMMENT '修改人名称',`update_time` datetime(3) DEFAULT NULL COMMENT '修改时间',`is_del` tinyint(1) DEFAULT '0' COMMENT '是否删除 1:已删除 0:未删除',PRIMARY KEY (`id`) USING BTREE,KEY `index_pid` (`pid`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='部门';特别是有些状态类型的字段,比如:valid_status字段,该字段表示有效状态, 1:有效 0:无效。
这篇关于浅谈下MYSQL表设计的几条规则的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






