本文主要是介绍十六、Redis和数据库双写一致性问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
众所周知,Redis一般被用来做为数据的缓存中间件,提升系统读数据的能力。但是被缓存的数据并不是一成不变的。如果是永远不会变的,那不会存在双写一致性问题(只需构建一次缓存即可)。但是大部分情况下,或多或少都会涉及到缓存数据的变更的问题。这时就需要思考一个问题,到底是先操作数据库,还是先操作缓存。
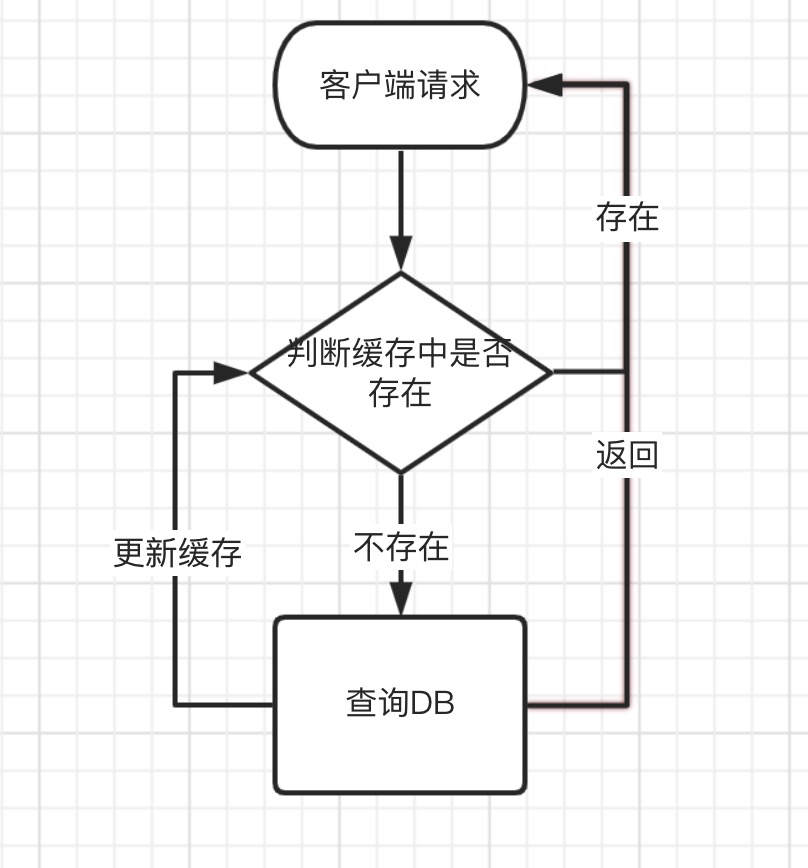
1、先更新数据库,在更新缓存
这套方案是最被大家反对的方案。有以下几点原因:
原因一、同时有请求A和请求B进行更新操作,那么会出现
- 线程A更新了数据库
- 线程B更新了数据库
- 线程B更新了缓存
- 线程A更新了缓存
这就出现请求A更新缓存应该比请求B更新缓存早,但是因为某种原因,B的更新却比A的更新早。这就造成了缓存中的脏数据出现。
2、先删缓存,在更新数据库
改方案导致不一致的原因是:同时有一个请求A进行更新操作,另一个请求B进行查询操作。那么就会出现以下情形:
- 请求A删除缓存
- 请求B查询,发现缓存中不存在
- 请求B去查询数据库得到旧值
- 请求B将旧值写入缓存
- 请求A将新值写入到数据库
上面就会出现数据不一致问题,即使请求A先删掉缓存,这是请求B在A更新数据库前请求,就会出现又将旧值写到缓存的问题。就会导致数据库和缓存不一致的问题。
对于上面的问题,可以采用延时双删的策略。
redis.deleteKey(key)
db.update
Thread.sleep(500)
redis.deleteKey(key)
其实就是:
- 先删除缓存
- 更新数据库
- 休眠一段时间,在删除缓存。(允许在睡眠这段时间内的脏数据)
针对上面的情景,睡眠的时间应该根据自己的业务来进行判断,写数据的休眠时间应该在读数据的耗时基础上加上个几百毫秒即可。这样做的目的可以确保读请求结束后,写请求可以删除读请求造成的缓存脏数据。
但是如果是使用的mysql的读写分离架构怎么办?
那么在这种情况下,造成数据不一致的原因如下:
- 请求A写操作,删除缓存
- 请求A将数据写入主数据库
- 请求B查询缓存,发现不存在
- 请求B去从库查询得到旧值
- 请求B将旧值写到缓存
- 数据库完成主从同步,从库变为新值
上面这种情形,就是造成数据不一致的原因。请求B在主从同步之前,来请求这是还会将旧值写到缓存中,即使A请求删除掉了缓存。
还是使用延时双删策略。只是睡眠时间修改为在主从同步的延时时间上增加几百毫秒。
但是采用延时双删策略,会降低系统的吞吐量。
对于这个问题,可以将第二次删除采用异步的方式。这样写请求就不用睡眠一段时间在返回。
但是如果,第二次删除失败了会怎么样?
当请求A去删除请求B读取的旧值写到的缓存时失败,这是又会出现,缓存和数据库不一致的情况。这种情况就看下第三种更新策略。
3、先更新数据库,在删缓存
其实这种情况也存在并发问题。
假设有两个请求,一个请求A做查询请求,另一个请求B做更新请求,那么会有如下情况产生:
- 缓存刚好失效
- 请求A查询数据库,得到一个旧值
- 请求B将新值写入数据库
- 请求B删除缓存
- 请求A将查询的旧值更新到缓存
这种情形也会发生脏数据。
但是这种情形发生的概率是极低的。
发生上述情况的前提条件是步骤3的写数据操作比步骤2的查询操作耗时更短(只有这样才能在请求B在请求A之后写库,但是比A先执行完)。
但是一般来说,写的请求耗时是比读的请求更多的。总的来说这种情形很少出现。
但是假设如果一定会出现这种情形呢!如何处理呢?
首先,给缓存设置一个过期时间是一个有效的解决方案。另外也可以采用策略2中提到的延时双删策略。但是这个方法也会出现第二次删除失败的问题。回导致数据的不一致。
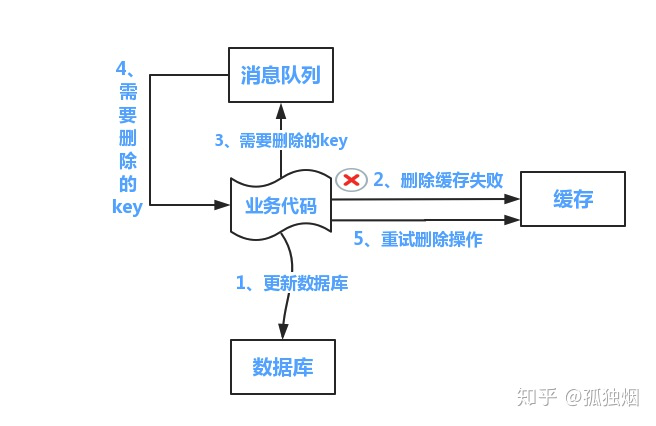
对于解决上述问题的方法,可以采用提供一个保障的重试机制方法。
方案一:采用失败发送MQ消息队列的方式,重试机制。
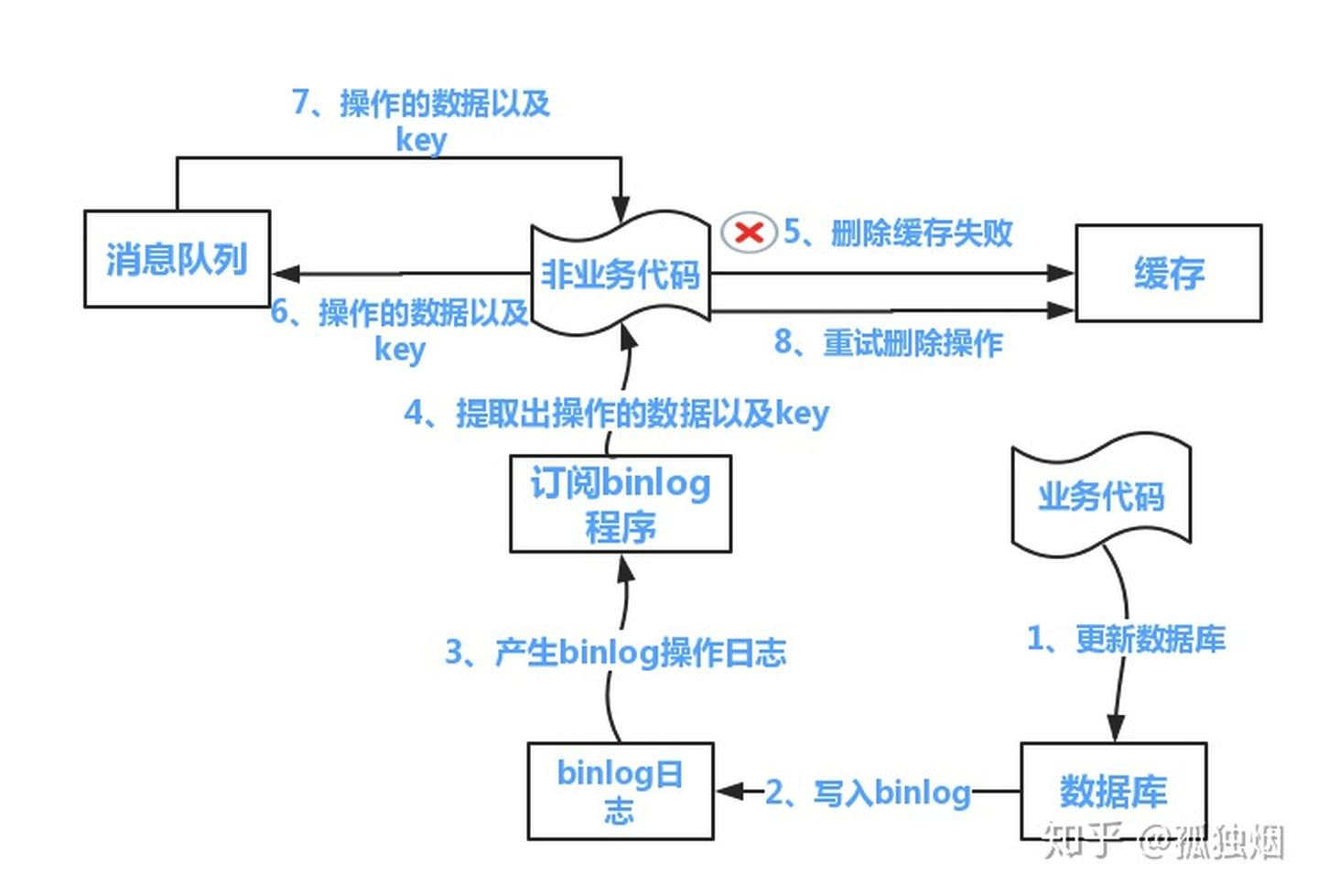
方案二:采用订阅数据库的binlog日志的方式
这篇关于十六、Redis和数据库双写一致性问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





