本文主要是介绍【Interview】深入理解ConcurrentLinkedQueue源码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 概述
- 常用方法
- 源码分析
- offer入队操作
- 初始化
- 出队操作
- 总结
概述
ConcurrentLinkedQueue是一个基于链接节点的无边界的线程安全队列,它采用先进先出原则对元素进行排序,插入元素放入队列尾部,出队时从队列头部返回元素,利用CAS方式实现的ConcurrentLinkedQueue的结构由头节点和尾节点组成的,都是使用volatile修饰的。每个节点由节点元素item和指向下一个节点的next引用组成,组成一张链表结构。ConcurrentLinkedQueue继承自AbstractQueue类,实现Queue接口
常用方法
boolean add(E e)将指定元素插入此队列的尾部,当队列满时,抛出异常boolean contains(Object o)判断队列是否包含次元素boolean isEmpty()判断队列是否为空boolean offer(E e)将元素插入队列尾部,当队列满时返回falseE peek()获取队列头部元素但不删除E poll()获取队列头部元素,并删除boolean remove(Object o)从队列中移指定元素int size()返回此队列中的元素数量,需要遍历一遍集合。判断队列是否为空时,不推荐此方法
源码分析
// 头节点private transient volatile Node<E> head;//尾节点private transient volatile Node<E> tail;public ConcurrentLinkedQueue() {//初始化构造时 头结点等于尾结点head = tail = new Node<E>(null);}//创建一个最初包含给定 collection 元素的 ConcurrentLinkedQueue,按照此 collection 迭代器的遍历顺序来添加元素。public ConcurrentLinkedQueue(Collection<? extends E> c) {Node<E> h = null, t = null;for (E e : c) {checkNotNull(e);Node<E> newNode = new Node<E>(e);if (h == null)h = t = newNode;else {t.lazySetNext(newNode);t = newNode;}}if (h == null)h = t = new Node<E>(null);head = h;tail = t;}private static class Node<E> {volatile E item;volatile Node<E> next;//构造一个新节点Node(E item) {UNSAFE.putObject(this, itemOffset, item);}boolean casItem(E cmp, E val) {return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);}void lazySetNext(Node<E> val) {UNSAFE.putOrderedObject(this, nextOffset, val);
}boolean casNext(Node<E> cmp, Node<E> val) {return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);}private static final sun.misc.Unsafe UNSAFE;//当前结点的偏移量private static final long itemOffset;//下一个结点的偏移量private static final long nextOffset;static {try {UNSAFE = sun.misc.Unsafe.getUnsafe();Class<?> k = Node.class;itemOffset = UNSAFE.objectFieldOffset(k.getDeclaredField("item"));nextOffset = UNSAFE.objectFieldOffset(k.getDeclaredField("next"));} catch (Exception e) {throw new Error(e);}}}offer入队操作
初始化
- 初始化操作就是创建一个新结点,并且
head和tail相等,结点的数据域为空。

- 当第一次入队操作时,检查插入的值是否为空,为空则抛空指针,然后用当前的值创建一个新
Node结点。然后执行死循环开始入队操作

- 首先定义了两个指针
p和t,都指向tail - 然后定义
q结点存储p的next指向的结点,此时p的next是为空没有结点的

- 此时
q==null条件成立。执行p.casNext(null, newNode).以cas方式把p的下一个节点指向新创建出来的结点,然后往下执行,p=t直接返回true。此时初始化构造的结点的next指向第一次入队成功的结点
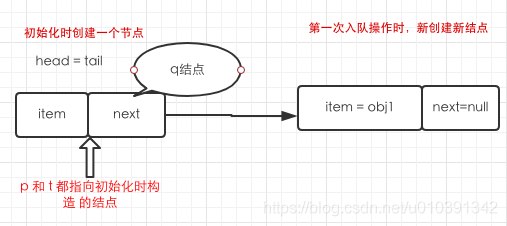
- 第二次入队操作,首先也是非空检查,然后创建一个新结点。此时死循环入队操作。定义了两个指针
p和t,都指向tail。定义q结点存储p的next指向的结点,此时p的next是不为空的,指向了上面创建的结点。所以q==null不成立。执行else操作

- 此时
p也不等于q。p!=t不成立,p和t都是指向tail。因为不成立所以让p=q,此时p和q都是指向第二个结点。再次循循环操作。

- 然后再次
p和t,都指向tail。定义q结点存储p的next指向的结点。此时p的next指向还是空,所以q=null成立。执行p.casNext(null, newNode).以cas方式把p的next指向新创建出来的结点。

- 此时
if (p != t)是成立的 执行casTail(t, newNode);期望值是t,更新值新创建的结点。于是更新了tail结点移动到最后添加的结点

大概的入队流程就是这样重复上述操作。直到入队成功。tail结点并不是每次都是尾结点。所以每次入队都要通过tail定位尾结点。
public boolean offer(E e) {//检查结点是为null,如果插入null则抛出空指针checkNotNull(e);//构造一个新结点final Node<E> newNode = new Node<E>(e);//死循换,一直到入队成功for (Node<E> t = tail, p = t;;) {//p表示队列尾结点,默认情况尾巴=结点就是taill结点//获取p结点的下一个节点Node<E> q = p.next;//q为空,说明p就是taill结点if (q == null) {//case方式设置p(p=t)节点的next指向当前节点if (p.casNext(null, newNode)) {if (p != t) //p不等于t更新尾结点,casTail(t, newNode); //失败了也是没事的,因为表示有其他线程成功更新了tail节点return true;}//其他线程抢先完成入队,需要重新尝试}//q不为空,p和相等else if (p == q)p = (t != (t = tail)) ? t : head;else// // 在两跳之后检查尾部更新.p = (p != t && t != (t = tail)) ? t : q;}}
出队操作
public E poll() {//一个标号restartFromHead://死循环方for (;;) {// 定义p,h两个指针 都指向headfor (Node<E> h = head, p = h, q;;) {//获取当前p的值E item = p.item;//值不为空,且以cas方式设置p的item赋值为空。两个条件成立向下执行if (item != null && p.casItem(item, null)) {// p和h不相等则更新头结点,否则直接返回值if (p != h) //更新头结点,预期值是h,当p的next指向不为空,更新值是q,为空则是pupdateHead(h, ((q = p.next) != null) ? q : p);//返回当前p的值return item;}//如果item为空说明已经被出队了,然后判断q是否null,是空则说明当前队列为空了。但是q = p.next赋值语句已经执行了else if ((q = p.next) == null) {//更新头结点,预期值h=head,更新p.此时p的item是空,说明已经被出队了updateHead(h, p);return null;}else if (p == q)continue restartFromHead;elsep = q;}}}
- 出队操作是以死循环的方式直到出队成功。 第一次出队首先执行
for (Node<E> h = head, p = h, q;;)定义两个指针p和h都指向head
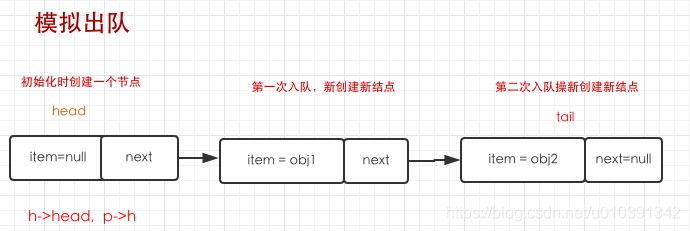
- 然后定义一个item存储p(这里就是head)的值,然后判断item是否为空,此时第一次出队时为空的,则执行
else if ((q = p.next) == null),此条件不成立,因为head的next有结点。执行else if (p == q),此时不相等,因为上个操作已经把q赋值为p的next结点了。所以执行最后的else语句p = q;在次循环执行。
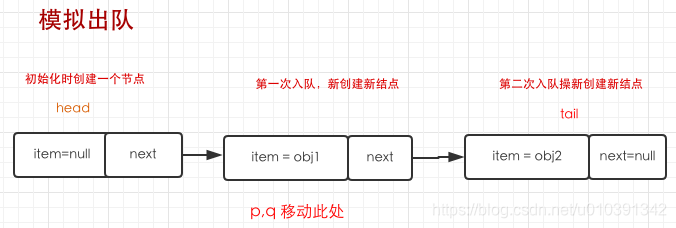
- 此时
p.item不为空条件成立且以cas方式更新p的item为空p.casItem(item, null)。如果都两个条件都成立,判断if (p != h)此时不成立的,更新updateHead(h, ((q = p.next) != null) ? q : p);预期值是h,更新值是q因为不为空。并返回item,第一次出队成功。

总结
CoucurrentLinkedQueue的结构由头节点和尾节点组成的,都是使用volatile修饰的。每个节点由节点元素item和指向下一个节点的next引用组成.入队:先检查插入的值是否为空,如果是空则抛出异常。然后以死循坏的方式执行一直到入队成功,整个过程大概就是把tail结点的next指向新结点,然后更新tail为新结点即可。但是tail结点并不是每次都是尾结点。所以每次入队都要通过tail定位尾结点。出队:出队操作就是从队列里返回一个最早插入的节点元素,并清空该节点对元素的引用。并不是每次出队都更新head节点,当head节点有元素时,直接弹出head节点的元素,并以cas方式设置节点的item为null,不会更新head节点。只有当head节点没有元素值时,出队操作才会更新head节点,这种做法是为了减少cas方式更新head节点的消耗,提供出队的效率
这篇关于【Interview】深入理解ConcurrentLinkedQueue源码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





