本文主要是介绍dock er catch机制,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
docker build 简介
众所周知,一个 Dockerfile 唯一的定义了一个 Docker 镜像。如此依赖,Docker 必须提供一种方式,将 Dockerfile 转换为 Docker 镜像,采用的方式就是 docker build 命令。以如下的 Dockerfile 为例:
-
FROM ubuntu:14.04 -
RUN apt-get update -
ADD run.sh / -
VOLUME /data -
CMD ["./run.sh"]
一般此 Dockerfile 的当前目录下,必须包含文件 run.sh。通过执行以下命令
docker build -t="my_new_image" .
即可将当前目录下的 Dockerfile 构建成一个名为 my_new_image 的镜像,镜像的默认 tag 为 latest。对于以上的docker build请求,Docker Daemon 新创建了 4 层镜像,除了 FROM 命令,其余的 RUN、ADD、VOLUME 以及 CMD 命令都会创建一层新的镜像。
镜像 cache 机制介绍
Dockerfile 可以通过docker build命令构建为一个新的镜像,Dockerfile 中每一条命令都会构建出一个新的镜像层。既然如此,构建成功后宿主机上的镜像层是否会不断增多,导致磁盘空间资源逐渐缩小?另外,一个 Dockerfile 如果构建多次,对于 Dockerfile 中的某一指定命令,是否会出现产生多个对应镜像层的情况呢?
镜像层的增多自然是毋庸置疑,然而并非每一次构建的每一条 Dockerfile 命令都会产生一个全新的镜像层。谈及原因,那我们必须谈谈 docker build 的 cache 机制。
docker build 的 cache 机制: Docker Daemnon 通过 Dockerfile 构建镜像时,当发现即将新构建出的镜像与已有的某镜像重复时,可以选择放弃构建新的镜像,而是选用已有的镜像作为构建结果,也就是采取本地已经 cache 的镜像作为结果。
反复阅读以上解释,细心的朋友肯定会有两点疑惑:
1. “即将构建出的镜像”属于仍未构建完成的镜像,通过何种方式来标识此镜像?
2. 涉及到镜像比较,重复时选择放弃构建,那镜像比较时重复的标准是什么?
cache 机制实现原理
Docker 镜像,由镜像层文件系统内容和镜像 json文件组成,而这两者都含有一个相同的镜像 ID 。还记得我们之前谈及的父镜像和子镜像的概念吗?此处也会大量运用镜像间的父子关系。
还是以上文中的 Dockerfile 为例,我们结合下图,着重分析命令 FROM ubuntu:14.04 和 RUN apt-get update。
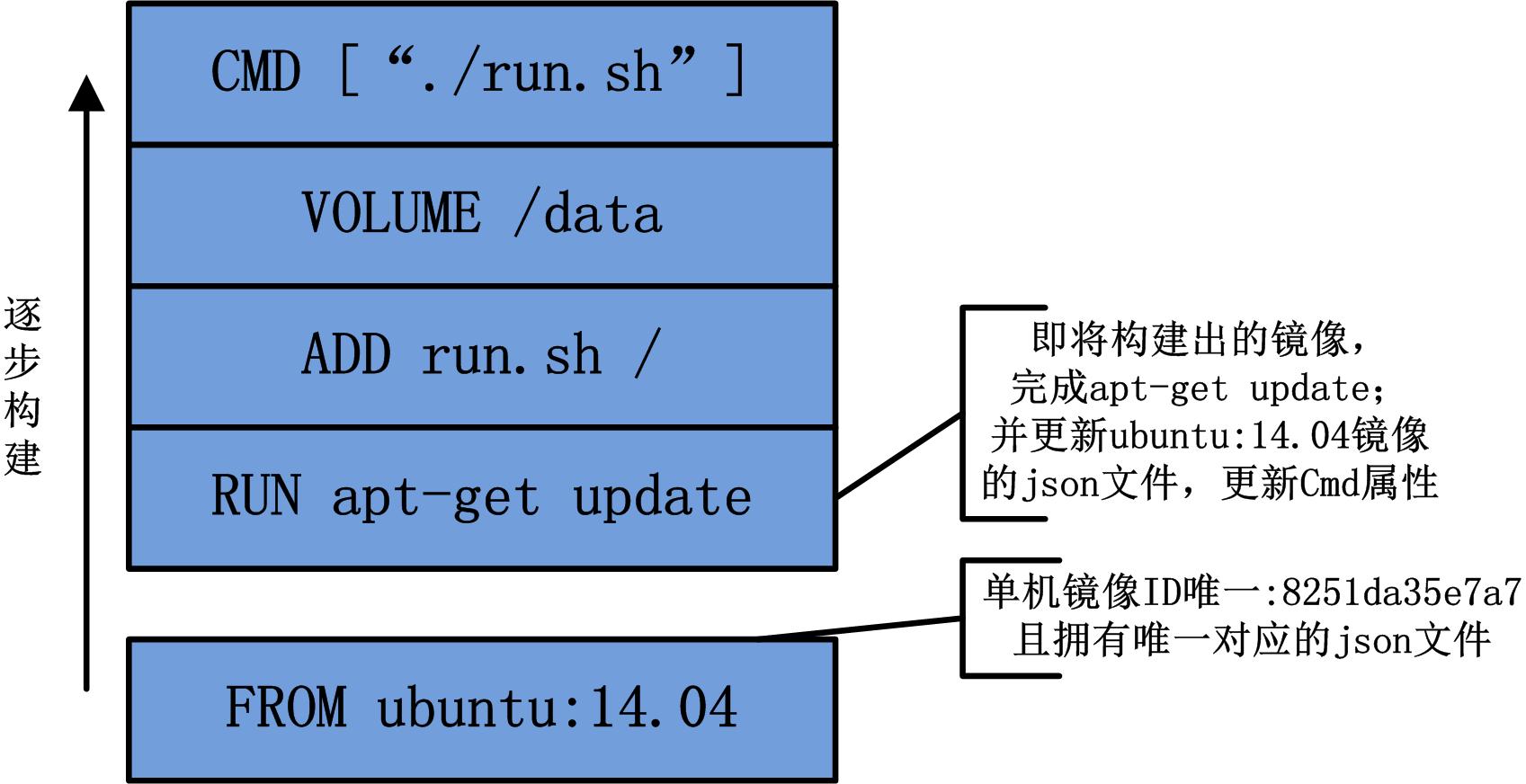
FROM ubuntu:14.04: FROM 命令是 Dockerfile 中唯一不可缺少的命令,它为最终构建出的镜像设定了一个基础镜像(base image)。docker build命令解析 Dockerfile 的 FROM 命令时,可以立即获悉在哪一个镜像基础上完成下一条命令RUN apt-get update的镜像构建。此时,Docker Daemon 获取 ubuntu:14.04 镜像的镜像 ID,并提取该镜像 json 文件中的内容,以备下一条命令构建时使用。
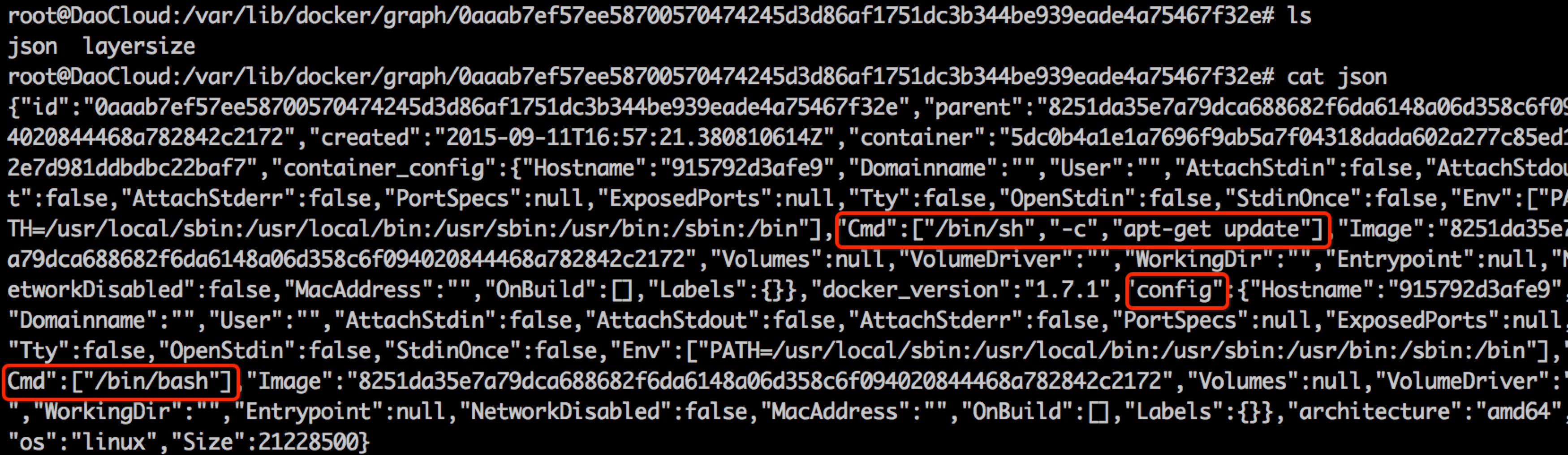
RUN apt-get update:RUN 命令是在上一层镜像(即 ubuntu:14.04 镜像)之上运行 apt-get update,所有对文件系统内容有更新的文件,都会保留于新构建的镜像层中,同时更新上一层镜像的 json 文件,更新镜像 json 文件的 Cmd 属性为"/bin/sh -c apt-get update"。注意:镜像 json 文件的 Cmd 属性与镜像 json 文件中 config 属性的 Cmd 属性,详见下图 RUN 命令所对应镜像(镜像 ID 为:0aaab7ef57ee)中两个 Cmd 的区别:
完成一条非 FROM 命令的构建,即产生一个新的镜像,新的镜像为其上一条命令产生镜像的子镜像。基于此以及以上的知识,我们可以提出这样的一个猜想:
“是否可以在构建 Dockerfile 某一命令前,就预知即将构建出新一层镜像的形态?”
围绕此问题,我们继续分析。未构建命令 RUN apt-get update 前,我们可以肯定的事实有以下几点:
-
镜像关系:对于命令
RUN apt-get update的构建,一定将会产生一个新镜像,新镜像的父镜像 ID 为 ubuntu:14.04 的镜像 ID,即 8251da35e7a7。 -
镜像 json 文件更新:运行命令 apt-get update 后产生新镜像,新镜像 json 文件仅仅更新 ubuntu:14.04 镜像 json 文件的 Cmd 属性,其它如 config 属性均不会进行修改。
-
镜像层文件系统内容更新:运行 apt-get update 后,对于容器可读写层的内容更新,全部将被打包进新镜像的镜像层文件系统内容。
基于这 3 个事实,我们再提出一个假设:如果在构建命令 RUN apt-get update 前,Docker Daemon 已经存在一个镜像满足以下两点:
- 此镜像的父镜像为 ubuntu:14.04
- 此镜像的 json 文件仅仅将 ubuntu:14.04 镜像 json 文件的 Cmd 属性更新为 apt-get update
那么是否可以认为:即将新构建的镜像与此镜像完全一致,不需要另行构建,只需复用此镜像即可?
如果你认可以上假设,那么 cache 机制的核心就接近浮出水面了:遍历本地所有镜像,发现镜像与即将构建出的镜像一致时,将找到的镜像作为 cache 镜像,复用 cache 镜像作为构建结果。
cache 机制注意事项
可以说,cache 机制很大程度上做到了镜像的复用,降低存储空间的同时,还大大缩短了构建时间。然而,不得不说的是,想要用好 cache 机制,那就必须了解利用 cache 机制时的一些注意事项。
1. ADD 命令与 COPY 命令:Dockerfile 没有发生任何改变,但是命令ADD run.sh / 中 Dockerfile 当前目录下的 run.sh 却发生了变化,从而将直接导致镜像层文件系统内容的更新,原则上不应该再使用 cache。那么,判断 ADD 命令或者 COPY 命令后紧接的文件是否发生变化,则成为是否延用 cache 的重要依据。Docker 采取的策略是:获取 Dockerfile 下内容(包括文件的部分 inode 信息),计算出一个唯一的 hash 值,若 hash 值未发生变化,则可以认为文件内容没有发生变化,可以使用 cache 机制;反之亦然。
2. RUN 命令存在外部依赖:一旦 RUN 命令存在外部依赖,如RUN apt-get update,那么随着时间的推移,基于同一个基础镜像,一年的 apt-get update 和一年后的 apt-get update, 由于软件源软件的更新,从而导致产生的镜像理论上应该不同。如果继续使用 cache 机制,将存在不满足用户需求的情况。Docker 一开始的设计既考虑了外部依赖的问题,用户可以使用参数 --no-cache 确保获取最新的外部依赖,命令为docker build --no-cache -t="my_new_image" .
3. 树状的镜像关系决定了,一次新镜像的成功构建将导致后续的 cache 机制全部失效:这一点很好理解,一旦产生一个新的镜像,同时意味着产生一个新的镜像 ID,而当前宿主机环境中肯定不会存在一个镜像,此镜像 ID 的父镜像 ID 是新产生镜像的ID。这也是为什么,书写 Dockerfile 时,应该将更多静态的安装、配置命令尽可能地放在 Dockerfile 的较前位置。
总结
docker build 的 cache 机制实现了镜像的复用,不仅节省了镜像的存储空间,也为镜像构建节省了大量的时间。 同时,如何命中 cache 镜像,也是衡量 Dockerfile 书写是否合理的重要标准之一。
这篇关于dock er catch机制的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





